
诚然,目前语言模型的诸多指标看来局部注意力的思路确实能解决长度外推问题,但这种“强行截断”的做法也许会不符合某些读者的审美,因为人工雕琢痕迹太强,缺乏了自然感,同时也让人质疑它们在非语言模型任务上的有效性。
本文我们从模型对位置编码的鲁棒性角度来重新审视长度外推性这个问题,此思路可以在基本不对注意力进行修改的前提下改进 Transformer 的长度外推效果,并且还适用多种位置编码,总体来说方法更为优雅自然,而且还适用于非语言模型任务。

其中,第 2 点说的是更多的 token 会导致注意力更加分散(或者说注意力的熵变大),从而导致的训练和预测不一致问题,其实我们在《从熵不变性看Attention的Scale操作》已经初步讨论并解决了它,答案是将 Attention 从:
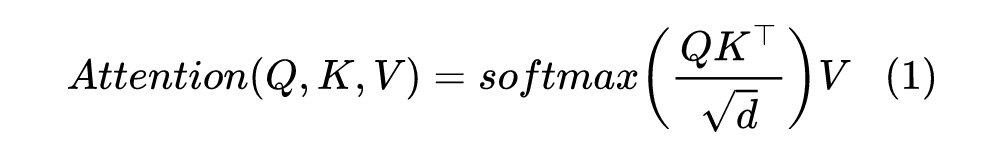
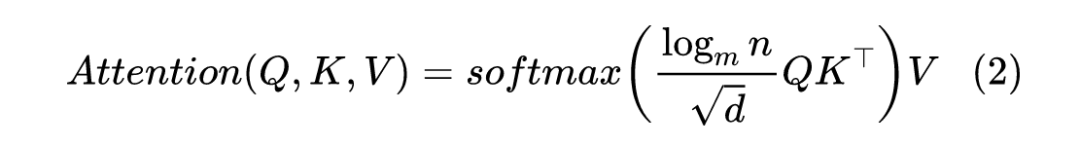
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢