
不同于传统的目标检测问题,少样本目标检测(FSOD)假设我们有许多的基础类样本,但只有少量的新颖类样本。其目标是研究如何将基础类的知识迁移到新颖类,进而提升检测器对新颖类的识别能力。
FSOD 通常遵循两阶段训练范式。在第一阶段,检测器使用丰富的基础类样本进行训练,以学习目标检测任务所需的通用表示,如目标定位和分类。在第二阶段中,检测器仅使用 少量(如 1, 2, 3...)新颖类样本进行微调。然而由于基础类和新颖类样本数量的不平衡,其学习到的模型通常偏向于基础类,进而导致新颖类目标与相似的基础类混淆。此外,由于每个新颖类只有少量样本,模型对新颖类的方差很敏感。例如,随机采样新颖类样本进行多次训练,每次的结果都会有较大的差异。因此十分有必要提升模型在少样本下的鲁棒性。
近期,腾讯优图实验室与武汉大学提出了基于变分特征聚合的少样本目标检测模型 VFA。VFA 的整体结构是基于改进版的元学习目标检测框架 Meta R-CNN++,并提出了两种特征聚合方法:类别无关特征聚合 CAA(Class-Agnostic Aggregation)和变分特征聚合 VFA(Variational Feature Aggregation)。
特征聚合是 FSOD 中的一个关键设计,其定义了 Query 和 Support 样本之间的交互方式。前面的方法如 Meta R-CNN 通常采用类别相关特征聚合 CSA(class-specific aggregation),即同类 Query 和 Support 样本的特征进行特征聚合。与此相反,本文提出的 CAA 允许不同类样本之间的特征聚合。由于 CAA 鼓励模型学习类别无关的表示,其降低了模型对基础类的偏向。此外,不同类之间的交互能够更好地建模类别间的关系,从而降低了类别的混淆。
基于 CAA,本文又提出了 VFA,其采用变分编码器(VAEs)将 Support 样本编码为类的分布,并从学习到的分布中采样新的 Support 特征进行特征融合。相关工作 [1] 指出类内方差(如外观的变化)在不同类之间是相似的,并且可以通过常见的分布进行建模。因此我们可以利用基础类的分布来估计新颖类的分布,进而提高少样本情况下特征聚合的鲁棒性。
VFA 在多个 FSOD 数据集上表现优于目前最好的模型,相关研究已经被 AAAI 2023 录用为 Oral。
论文地址:https://arxiv.org/abs/2301.13411
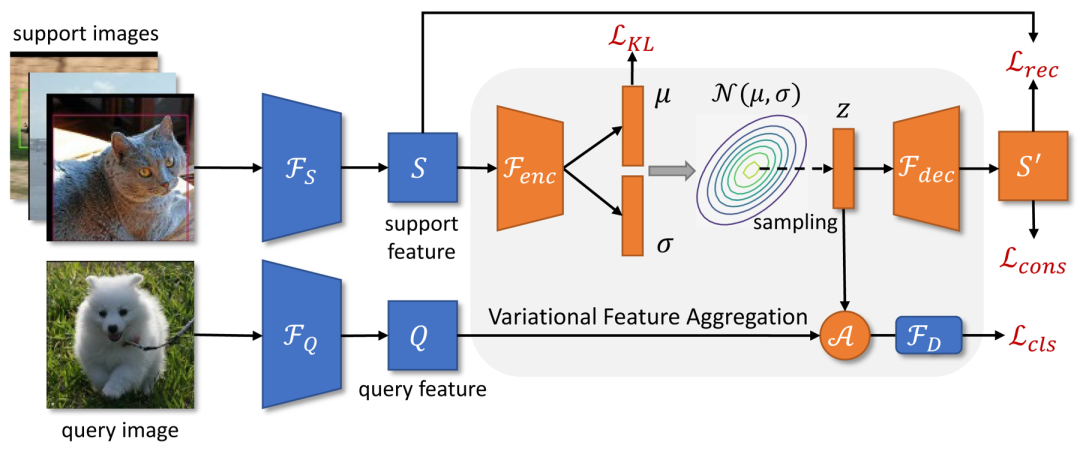 VFA 模型示意图
VFA 模型示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢