
大型语言模型 (LLM) 通过利用思维链 (CoT) 提示生成中间推理链作为推断答案的基本原理,在复杂推理上表现出了令人印象深刻的性能。 然而,现有的 CoT 研究大多孤立于 LLM 的语言模态中,LLM 难以部署。 为了在多模态中引发 CoT 推理,一种可能的解决方案是通过融合视觉和语言特征来微调小型语言模型以执行 CoT 推理。 关键的挑战在于,这些语言模型往往会产生误导答案推理的幻觉推理链。
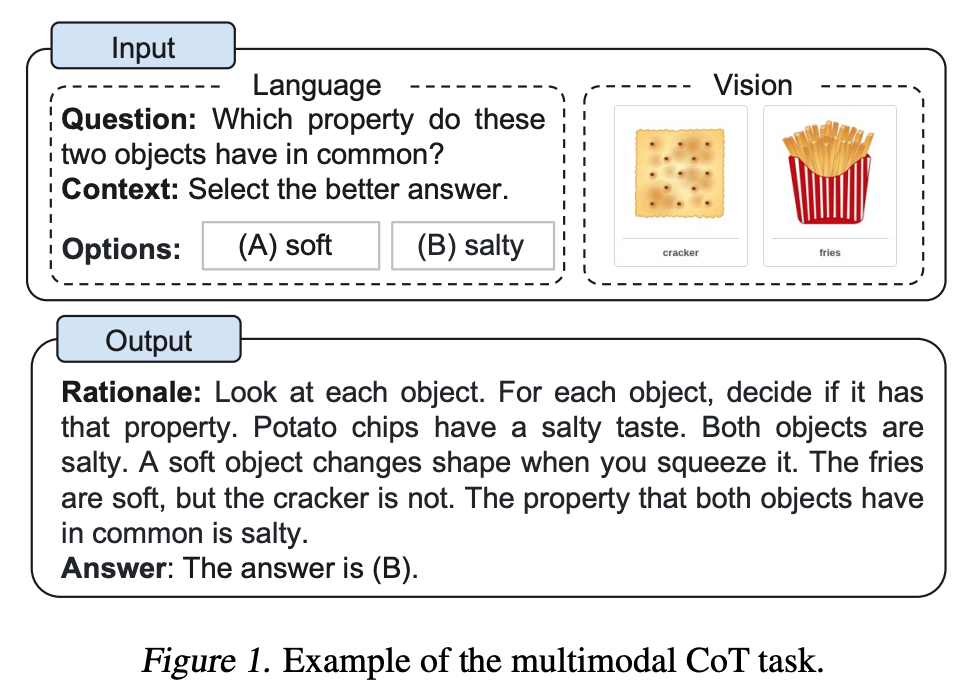
为了减轻此类错误的影响,本文提出了 Multimodal-CoT,它在解耦训练框架中结合了视觉特征。 该框架将基本原理生成和答案推理分为两个阶段。 通过在两个阶段结合视觉特征,该模型能够生成有助于答案推理的有效原理。

本文的主要贡献如下:
- 研究了 Multimodal-CoT 的问题并解决了引发多模态 CoT 推理的关键挑战。 据我们所知,这项工作是第一个以不同的方式研究 CoT 推理。
- 提出了一个两阶段框架,通过微调语言模型来融合视觉和语言表示执行多模式 CoT。 该模型能够生成有助于推断最终答案的信息性基本原理。
- 该方法实现了新的最先进的性能在 ScienceQA 基准测试中,准确度优于GPT-3.5 16%甚至超越人类表现。
论文链接:paper
代码链接:code
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢