
论文:Zero-shot Image-to-Image Translation
作者:Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, Jun-Yan Zhu
摘要:大规模的文本到图像生成模型已经显示出其合成多样化和高质量图像的非凡能力。 然而,由于两个原因,直接应用这些模型来编辑真实图像仍然具有挑战性。 首先,用户很难想出一个完美的文本提示来准确描述输入图像中的每个视觉细节。 其次,虽然现有模型可以在某些区域引入所需的变化,但它们通常会显着改变输入内容并在不需要的区域引入意外的变化。 在这项工作中,我们提出了 pix2pix-zero,一种图像到图像的转换方法,可以在没有手动提示的情况下保留原始图像的内容。 我们首先自动发现反映文本嵌入空间中所需编辑的编辑方向。 为了在编辑后保留一般内容结构,我们进一步提出了交叉注意引导,旨在在整个扩散过程中保留输入图像的交叉注意图。 此外,我们的方法不需要对这些编辑进行额外训练,可以直接使用现有的预训练文本到图像扩散模型。 我们进行了大量实验,表明我们的方法在真实和合成图像编辑方面优于现有和并行工作。
主要贡献:
1.高效、自动的编辑方向发现机制
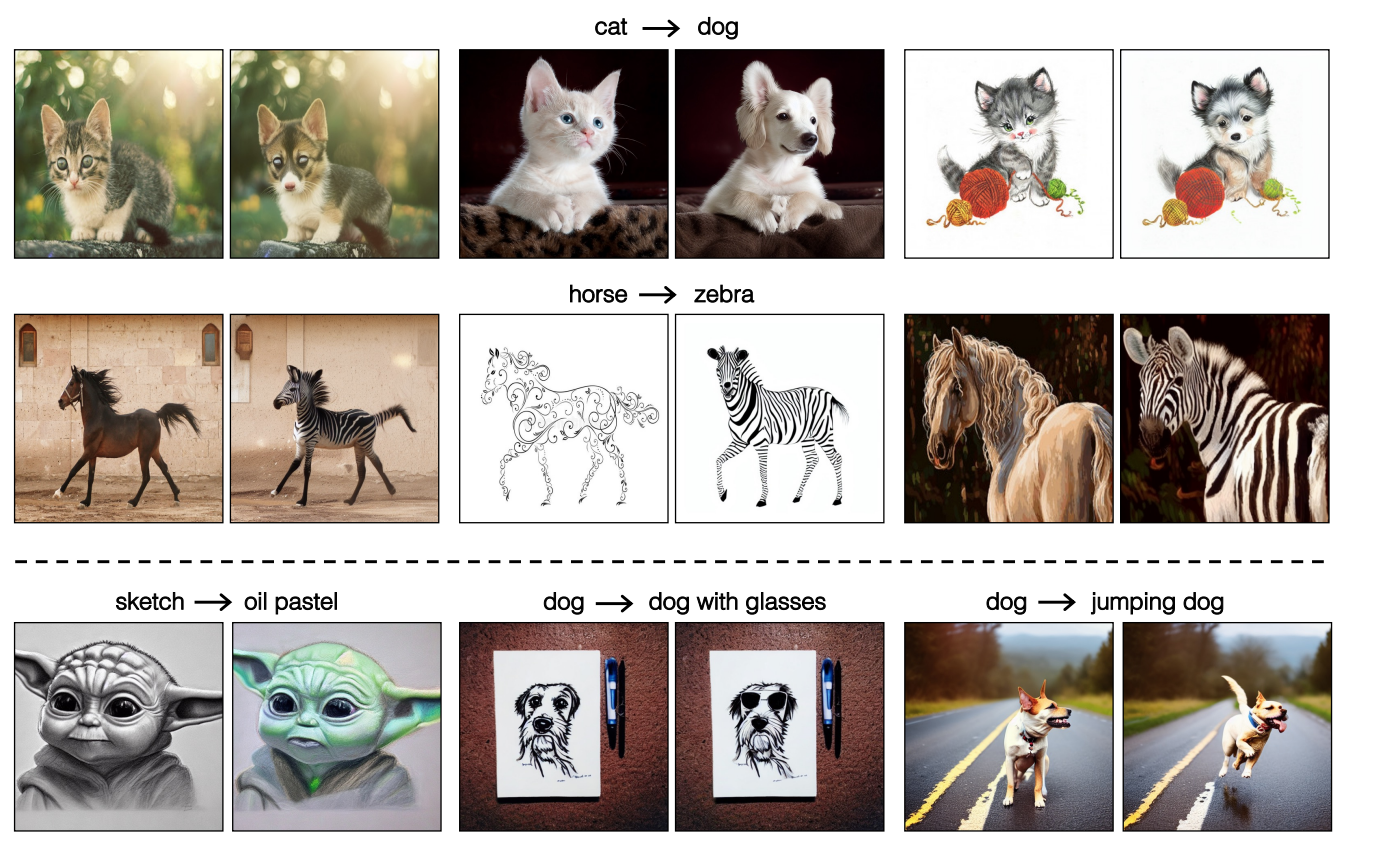
没有输入文字提示。 我们自动发现适用于各种输入的通用编辑方向图片。 给定一个原始词(例如,cat)和一个编辑过的词词(例如,狗),我们生成两组分别包含原始词和编辑后词的句子。 然后我们计算两者之间的 CLIP 嵌入方向。由于这个编辑方向是基于多个句子的,所以比只找原始词和编辑词之间的方向更健壮。这一步大约需要5 秒,可以预先计算。
2.通过交叉注意力指导保存内容
我们的观察是交叉注意力图对应于生成对象的结构。 为了保留原始结构,我们鼓励文本-图像交叉注意力图翻译前后保持一致。 因此,在整个扩散过程中我们应用交叉注意力指导来加强这种一致性。 在图中,我们使用我们的方法显示了各种编辑结果,同时保留了输入图像的结构。
3.进一步提高了我们的结果和推理速度
(1)自相关正则化:当通过 DDIM [55] 应用反演时,我们观察到DDIM 反演容易使中间预测噪声变得不那么高斯分布,从而降低了反演图像的可编辑性。 因此,我们引入自相关正则化以确保在反演期间噪声接近高斯分布。
(2)Conditional GAN distillation:由于昂贵的扩散过程的多步推理,扩散模型很慢。 为了启用交互式编辑,我们将扩散模型提炼为快速条件 GAN 模型,给定配对来自扩散的原始和编辑图像的数据模型,实现实时推理。我们在广泛的图像到图像转换任务上展示了我们的方法,例如更改前景对象(猫→狗),修改对象(添加眼镜到猫图像),并更改输入的样式(草图→ 油画棒),用于真实图像和合成图像。广泛的实验表明 pix2pix-zero 优于关于真实感和内容保存的现有和并行作品。
4.包括一个对单个算法组件进行广泛的消融研究,并讨论方法的局限性。
查看网站:https://pix2pixzero.github.io/
论文链接:paper
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢