
自然语言生成 (NLG) 技术的最新进展显着提高了大型语言模型生成文本的多样性、控制力和质量。一个值得注意的例子是 OpenAI 的 ChatGPT,它在回答问题、撰写电子邮件、论文和代码等任务中展示了卓越的性能。然而,这种新发现的高效生成文本的能力也引起了人们对检测和防止大型语言模型在网络钓鱼、虚假信息 和学术造假等任务中滥用的担忧。例如,由于担心学生利用 ChatGPT 写作业,纽约公立学校全面禁止了 ChatGPT 的使用,媒体也对大型语言模型产生的假新闻发出警告。这些对大型语言模型 滥用的担忧严重阻碍了自然语言生成在媒体和教育等重要领域的应用。
大型语言模型(LLM)的出现导致其生成的文本非常复杂,几乎与人类编写的文本难以区分。本文旨在提供现有大型语言模型生成文本检测技术的概述,并加强对语言生成模型的控制和管理。
最近关于是否可以正确检测大型语言模型生成的文本以及如何检测的讨论越来越多,这篇文章对现有检测方法进行了全面的技术介绍。

-
论文地址:https://github.com/datamllab/The-Science-of-LLM-generated-Text-Detection
-
相关研究地址:https://github.com/datamllab/awsome-LLM-generated-text-detection/tree/main
现有的方法大致可分为两类:黑盒检测和白盒检测。
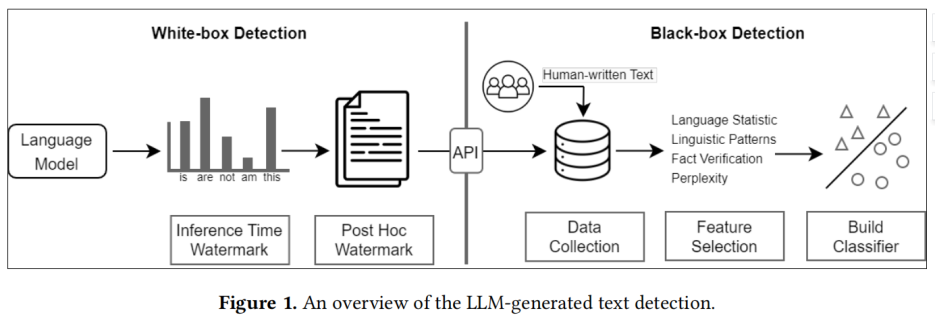
大型语言模型生成文本检测概述
-
黑盒检测方法对大型语言模型通常只有 API 级别的访问权限。因此,这类方法依靠于收集人类和机器的文本样本来训练分类模型;
-
白盒检测,这类方法拥有对大型语言模型的所有访问权限,并且可以通过控制模型的生成行为或者在生成文本中加入水印(watermark)来对生成文本进行追踪和检测。
在实践中,黑盒检测器通常由第三方构建,例如 GPTZero,而白盒检测器通常由大型语言模型开发人员构建。
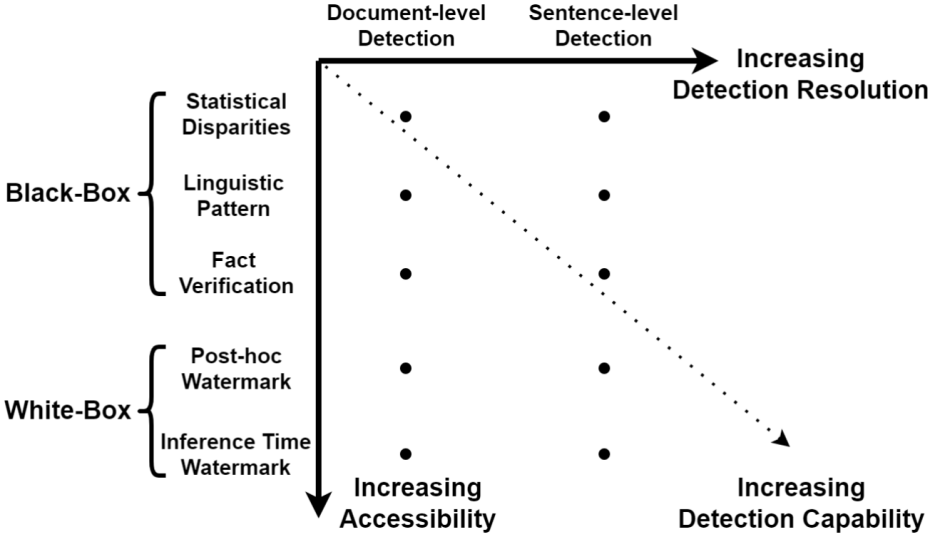
大型语言模型生成的文本检测分类学
更多内容分析可参考 AI生成文本检测方法
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢