
来自今天的爱可可AI前沿推介
[CV] Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval
K Saito, K Sohn, X Zhang, C Li, C Lee, K Saenko, T Pfister
[Google Research & Google Cloud AI Research & Boston University]
Pic2Word: 将图映射到词进行零样本组合图像检索
要点:
-
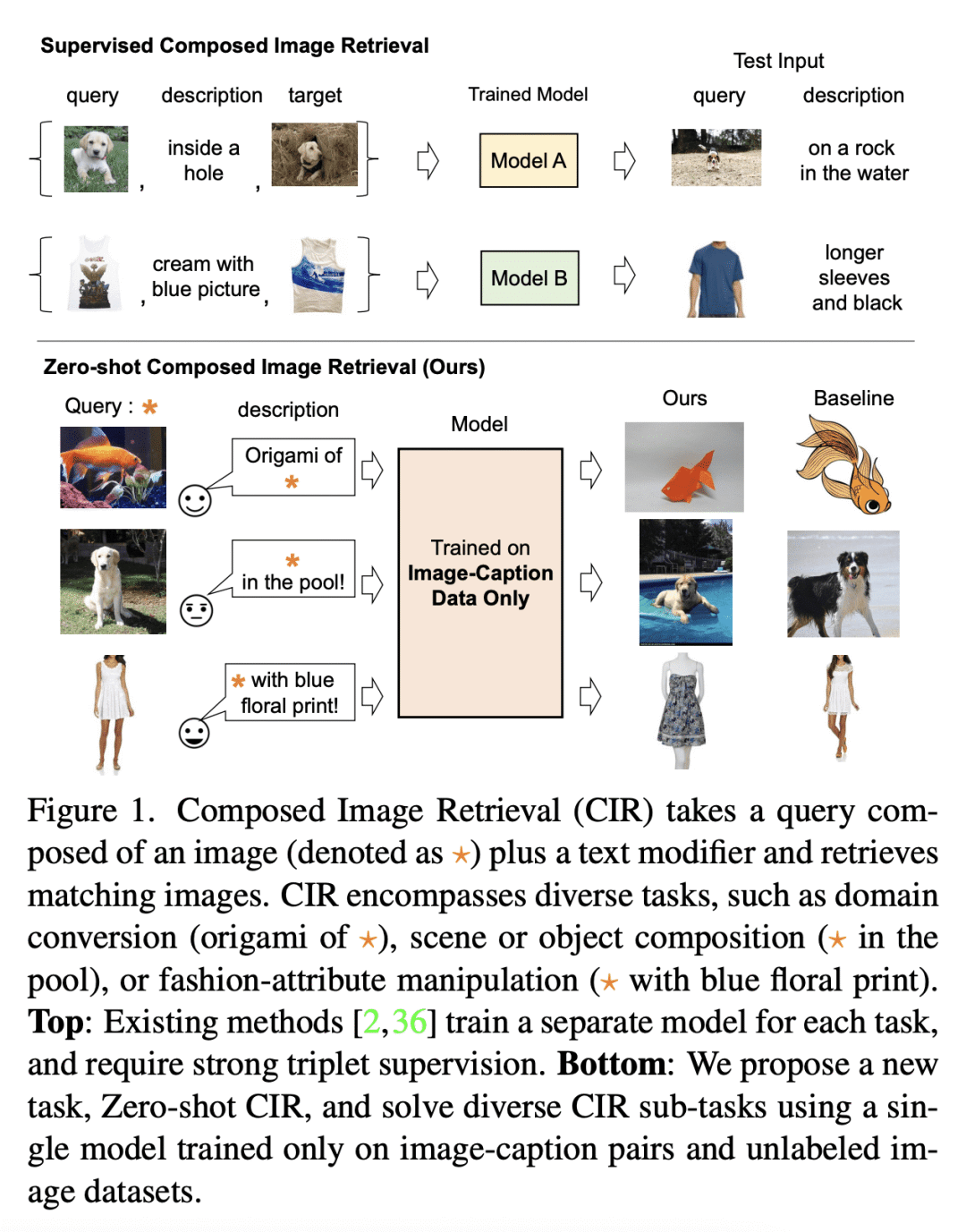
提出一种新任务,即零样本组合图像检索(ZS-CIR),旨在解决不同的 CIR 任务,而不需要标记三元组训练数据集; -
提出 Pic2Word,一种新的 ZS-CIR 方法,只需使用图像描述和未标记图像数据集就可以训练; -
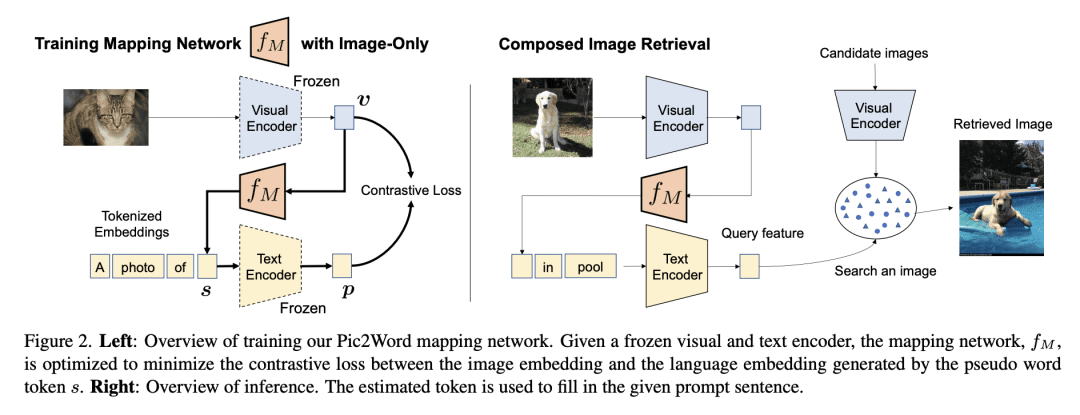
Pic2Word 利用预训练视觉-语言模型,将输入图像转化为语言token,以组成图像和文本查询。
一句话总结:
Pic2Word是一种新的零样本组合图像检索(ZS-CIR)方法,在弱标记图像-描述对和未标记图像数据集上进行训练,其性能优于现有的有监督 CIR 模型,并取得了与最近有标记训练数据的 CIR 方法相当或更好的结果。
摘要:
在组合图像检索(CIR)中,用户将查询图像与文本结合起来,描述他们的目标。现有的方法依赖于对 CIR 模型的监督学习,使用由查询图像、文本说明和目标图像组成的标记三元组。给这种三元组贴标签是很昂贵的,并且阻碍了 CIR 的广泛适用。本文提议研究一项重要任务,即零样本组合图像检索(ZS-CIR),其目标是建立一个不需要标记三元组的CIR模型进行训练。为此,本文提出一种新方法 Pic2Word,只需要弱标记的图像-描述对和无标记图像数据集来进行训练。与现有的监督 CIR 模型不同,本文在弱标记或无标记数据集上训练的模型在不同的 ZS-CIR 任务上显示出强大的泛化能力,例如属性编辑、对象合成和领域转换。本文方法在常见的 CIR 基准、CIRR 和 Fashion-IQ 上优于几种有监督 CIR 方法。
In Composed Image Retrieval (CIR), a user combines a query image with text to describe their intended target. Existing methods rely on supervised learning of CIR models using labeled triplets consisting of the query image, text specification, and the target image. Labeling such triplets is expensive and hinders broad applicability of CIR. In this work, we propose to study an important task, Zero-Shot Composed Image Retrieval (ZS-CIR), whose goal is to build a CIR model without requiring labeled triplets for training. To this end, we propose a novel method, called Pic2Word, that requires only weakly labeled image-caption pairs and unlabeled image datasets to train. Unlike existing supervised CIR models, our model trained on weakly labeled or unlabeled datasets shows strong generalization across diverse ZS-CIR tasks, e.g., attribute editing, object composition, and domain conversion. Our approach outperforms several supervised CIR methods on the common CIR benchmark, CIRR and Fashion-IQ. Code will be made publicly available at this https URL.
论文链接:https://arxiv.org/abs/2302.03084

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢