
来自今天的爱可可AI前沿推介
[LG] Memory-Based Meta-Learning on Non-Stationary Distributions
T Genewein, G Delétang, A Ruoss, L K Wenliang, E Catt, V Dutordoir, J Grau-Moya, L Orseau, M Hutter, J Veness
[DeepMind]
基于记忆的非平稳分布元学习
要点:
-
回顾了最小化顺序预测误差、元学习及其隐贝叶斯目标之间的联系; -
记忆对最小化顺序预测误差这一目标的必要性; -
通过元学习的神经模型对两种一般非参数贝叶斯算法的匹配预测性能进行经验论证。
一句话总结:
基于记忆的元学习是一种接近贝叶斯最优预测器的技术,本文研究了当前序列预测模型和训练方案实现的有效性,结果表明,基于记忆的神经模型可以接近已知的贝叶斯最优算法,并证明学到的神经解决方案可以匹配贝叶斯算法的预测性能。
摘要:
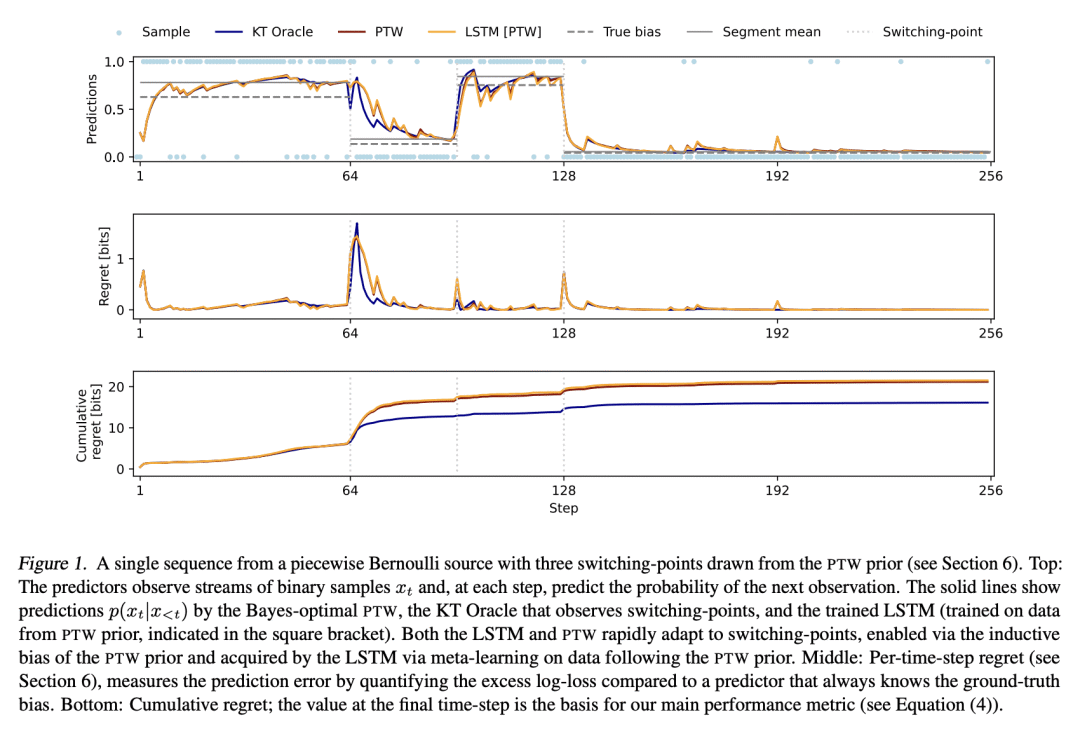
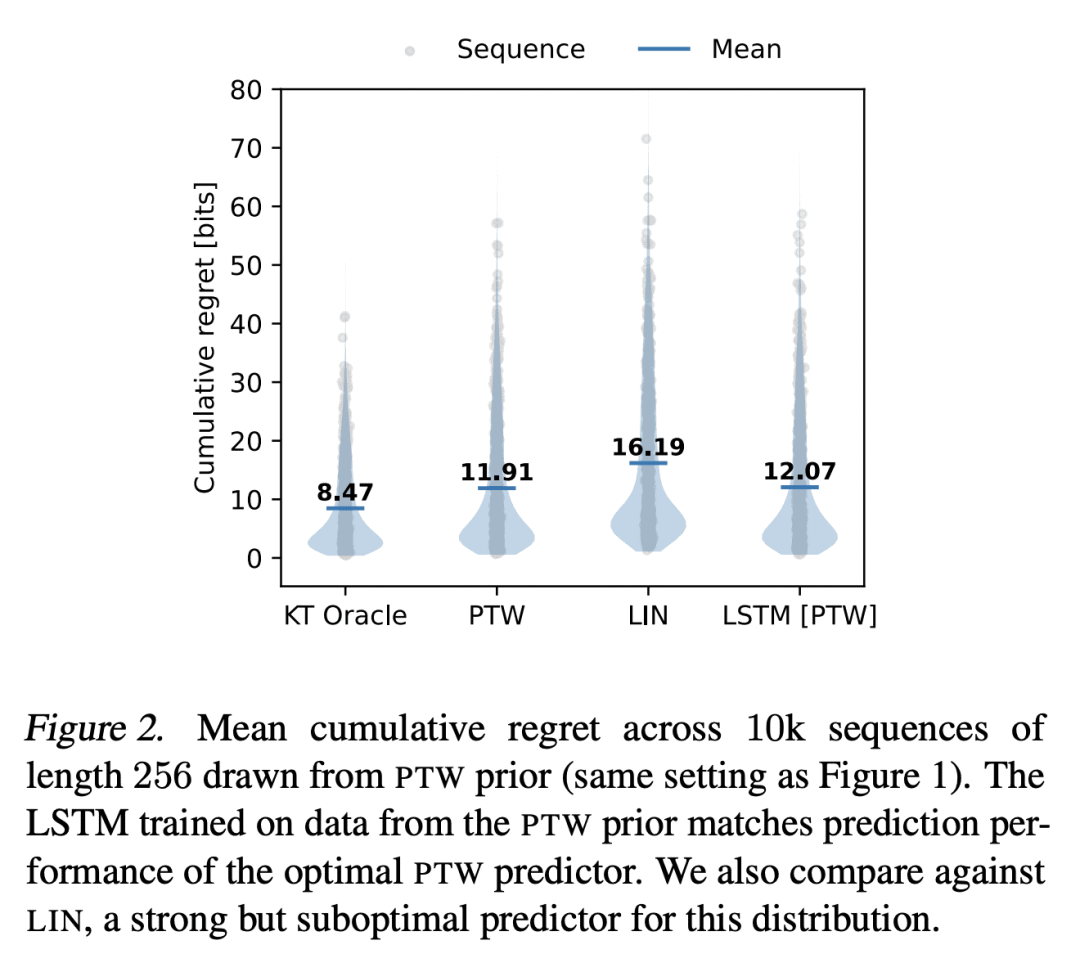
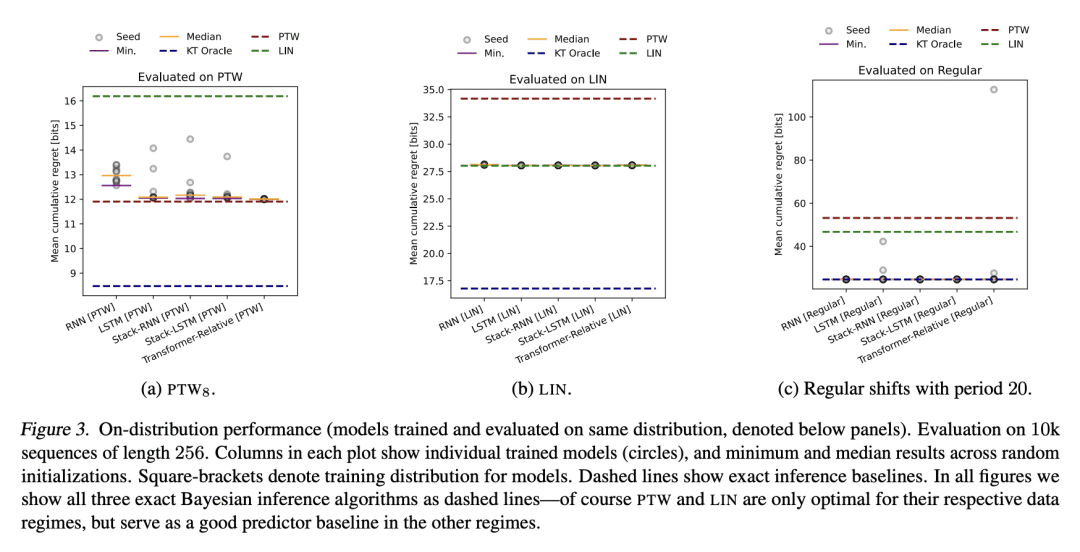
基于记忆的元学习,是一种近似贝叶斯最优预测器的技术。在相当普遍的条件下,通过对数损失来衡量的序列预测误差最小化,导致了隐性元学习。本文的目标是研究目前的序列预测模型和训练方案,在多大程度上可以实现这种解释。重点是具有未观察的切换点的片状静止源,这可以说是反映了部分可观察环境中自然语言和行动观察序列的一个重要特征。本文表明,各种类型的基于记忆的神经模型,包括 Transformer、LSTM 和 RNN 都能学会准确地接近已知的贝叶斯最优算法,并表现得像对潜在的切换点和支配每段数据分布的潜参数进行贝叶斯推理一样。
Memory-based meta-learning is a technique for approximating Bayes-optimal predictors. Under fairly general conditions, minimizing sequential prediction error, measured by the log loss, leads to implicit meta-learning. The goal of this work is to investigate how far this interpretation can be realized by current sequence prediction models and training regimes. The focus is on piecewise stationary sources with unobserved switching-points, which arguably capture an important characteristic of natural language and action-observation sequences in partially observable environments. We show that various types of memory-based neural models, including Transformers, LSTMs, and RNNs can learn to accurately approximate known Bayes-optimal algorithms and behave as if performing Bayesian inference over the latent switching-points and the latent parameters governing the data distribution within each segment.
论文链接:https://arxiv.org/abs/2302.03067
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢