
作者:G Mariani, I Tallini, E Postolache, M Mancusi, L Cosmo, E Rodolà
[Sapienza University of Rome]
要点:
-
提出多源扩散模型(MSDM),通过共享上下文的源的联合概率密度学习,能进行音乐合成和音源分离; -
通过训练MSDM,在去噪分数匹配框架的基础上,对生成任务进行新的表述,包括音源的归属; -
提出推理时基于狄拉克三角函数的源分离的新采样程序。
总结:
提出一种用于同步音乐生成和分离的多源扩散模型(MSDM),基于去噪分数匹配,可通过对混合的先验条件和对所得后验分布的采样来处理生成和分离任务,并在推理时引入一种新的分离采样方法,在分离任务中取得了有竞争力的结果。
原文:https://arxiv.org/abs/2302.02257
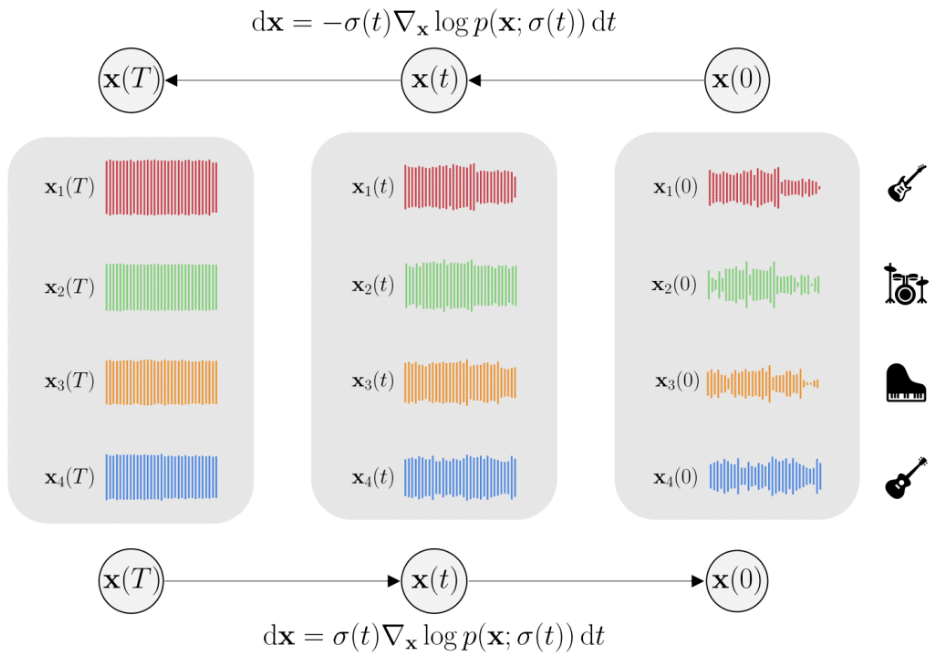
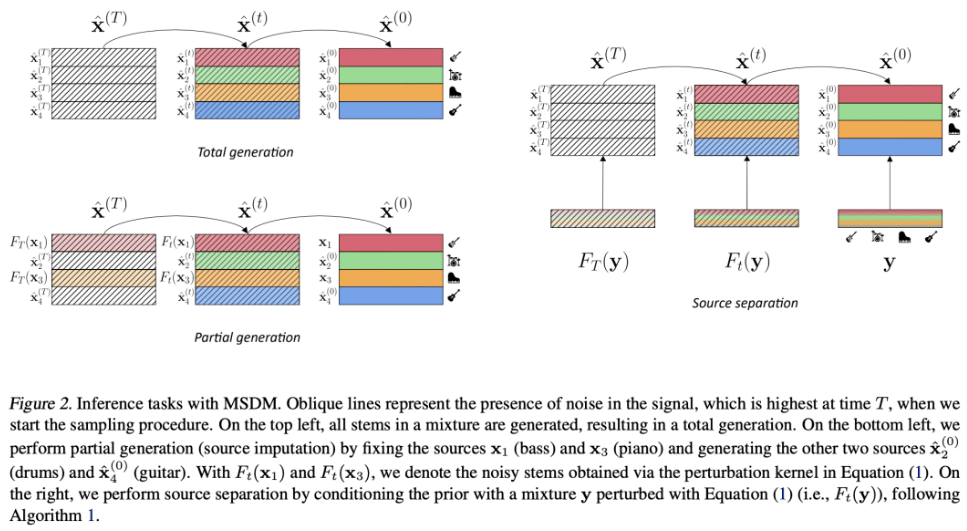
In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢