

Paper 地址:https://arxiv.org/abs/2301.13865
开源代码仓库地址:https://github.com/AIR-DISCOVER/Omni-PQ
简介
室内场景的框架预测任务(Room layout estimation, [1, 2, 3, 4, 5] )是一项长期存在的机器人视觉任务,为机器人的环境感知和运动规划等行为提供算法层面的支持。但大多数现有的工作 [6, 7, 8, 9, 10, 11] 都尝试利用房屋的 2D 透视图或全景图作为输入,用 3D 点云作为输入 [12] 的方法仍然面临着标注难、数据缺乏的问题。
同时,我们相信在未来,世界各地的智能机器人可以利用大量的无标注数据来不断提高集体智慧(在本项目中即利用大量无标注的室内三维点云数据来提高框架预测准度)。为此,我们先从半监督(Semi-supervised)设定开始探索,假设 ScanNet [13] 数据集只有一小部分比例的数据存在标注。然后,我们将我们的方法推广到真实世界的半监督学习(Omni-supervised)的设定,使用最新发布的 ARKitScenes [14] 数据集来证明我们的方法的有效性。
实际上,半监督的室内场景框架预测在工作 SSLayout360 [15] 中已被提出。然而,这份工作只是简单地利用了模型参数指数移动平均(Exponential Moving Average of model parameters, EMA)技术,从没有标注的 2D 室内场景全景图中学习。同时,这种范式并不适用于全监督场景下室内场景框架预测任务的最新进展—— 基于 3D 点云作为输入,直接预测房屋的框架 [12]。
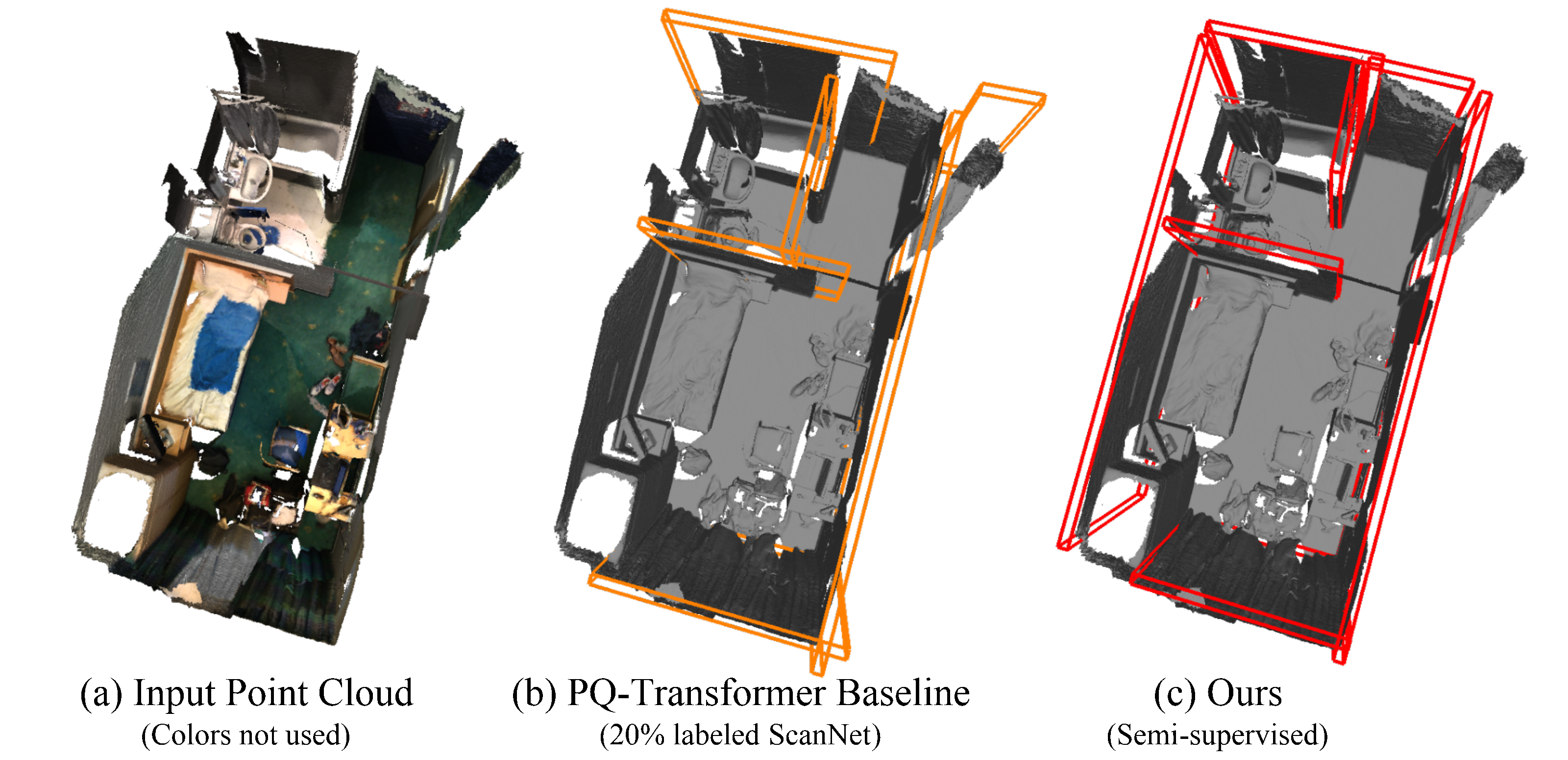
为此,我们提出首个使用点云作为输入的半监督的室内场景框架预测方法。我们的方法建立在室内场景框架预测的原 SOTA 方法 PQ-Transformer [12] 之上,该方法的输入是室内场景的三维点云(图 1(a)),并训练模型直接预测一组代表房屋框架元素(墙、地板或天花板)的平面参数,包括平面中心点坐标、平面法向与平面的长与宽。但是,该方法在缺少数据标注时表现并不理想,正如图 1(b) 中所展示的,在只利用 20% 数据的情况之下,它在没见过的室内场景中表现十分之差。而相比之下,我们的方法则可以利用剩下的 80% 的无标注的数据中所蕴含的知识,从而预测出更准确的房屋框架,正如图 1(c) 所示。
具体来说,我们方法的成功主要有两个原因。
-
第一是基于模型输出一致性的训练框架,其灵感来自于 Mean Teacher [16] 方法。基于中心距离最近这一匹配策略,我们定义了两组场景框架预测结果之间的“距离”,设计了三组损失函数来约束面对输入扰动时,模型输出的一致性。
-
第二是一个伪标签改良模块,我们在点云和预测框架间定义一个新的度量(Metric)来表示点云中的点和某个预测框架的相关性,然后假设这个度量服从 \Gamma 混合分布,将这个度量分解成两支。
直观上来说,我们通过这种方法将和预测框架强相关的点筛选出来,然后利用这些筛选出来的点进一步估计一个更加准确的场景框架作为“伪标签”。消融实验证明这两种方法都是有效的,而将它们结合起来会带来更大的改进。
通过实验,可以证明我们方法的有效性:
-
在 ScanNet 数据集上,面对不同的有标注的数据比例(5% ∼ 40%),我们的方法在无标注数据的帮助下,可以大大超越仅用这些标注数据训练的基线模型。
-
仅用 ScanNet 40% 的标注数据,我们就能够超越原先的全监督 SOTA。
-
即使是在 ScanNet 全监督的设置中,引入我们的方法还可以比基线结果提高+4.11 %。
-
我们进一步将我们的方法扩展到真实世界的半监督学习的设置中 [17],利用所有 ScanNet 训练数据和未标记的 ARKitScenes [14] 数据,在 ARKitScenes 测试集上取得了显著的性能提升,F1 分数从 10.66% 上升到 25.85%。
总结来看,我们的作品贡献如下:
-
我们提出了首个点云输入的室内场景框架预测任务的半监督框架,包括中心距离最近匹配策略和三组一致性损失函数。
-
我们提出了一种通过分解相关性度量这一混合分布来筛选和预测结果有关联的点的伪标签改良技术。
-
我们在半监督、全监督和真实世界的半监督学习的实验设定下都取得了显著的成果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢