

导读
在多标签分类系统中,经常遇到大量在训练集中未曾出现的标签,如何准确地识别这些标签是非常重要也极富挑战性的问题。为此,腾讯优图实验室联合清华大学和深圳大学,提出了一种基于多模态知识迁移的框架 MKT,利用图文预训练模型强大的图文匹配能力,保留图像分类中关键的视觉一致性信息,实现多标签场景的 Open Vocabulary 分类。本工作已入选 AAAI 2023 Oral。
背景
图像多标签识别算法的目标,是识别图像中存在的所有类别标签。作为计算机视觉应用中的一项基础能力,在场景理解、监控系统、自动驾驶等任务中有着广泛的应用。在实际落地场景中,多标签识别系统不仅需要识别图像中存在的大量已知类别标签,最好还能较为准确地识别出未知标签,即模型在训练集中未曾见过的标签。迄今为止,典型的有监督多标签分类方法,只能在训练过的已知类别标签上进行识别,远远无法满足实际场景中对大量未知标签的识别需求。因此,如何设计有效的算法,实现在有限的已知类别标签上进行训练,并在部署时同时支持在有限的已知类别和大量未知类别上的标签识别,是实际落地场景中非常重要的问题。
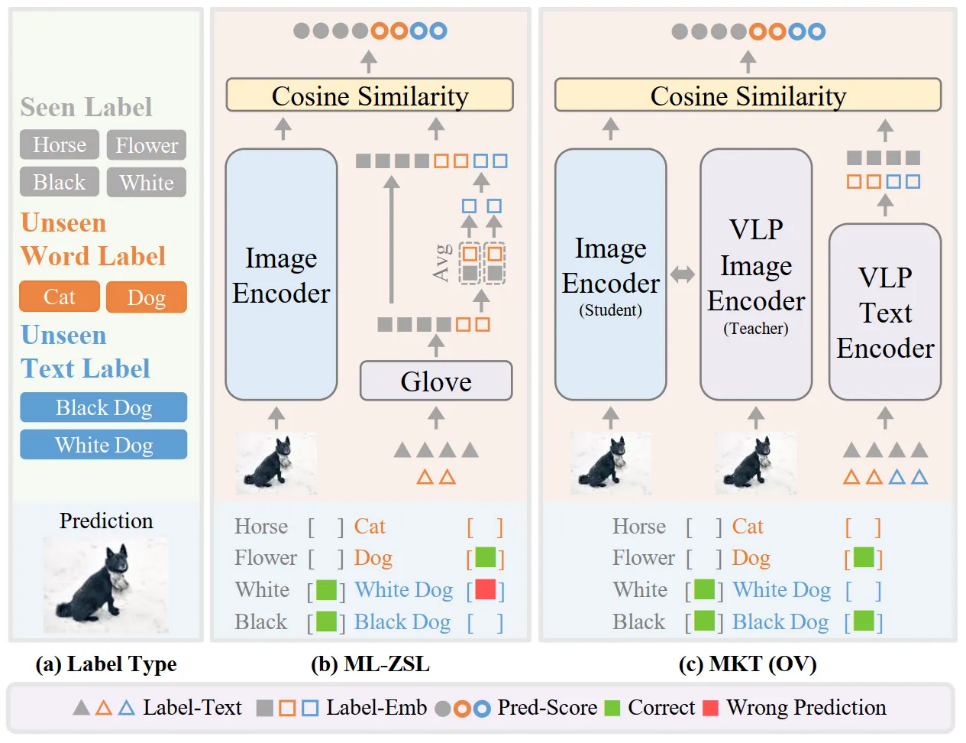
为了识别这些训练集未知标签,已有的多标签零样本学习(ML-ZSL)方法,往往通过从训练集已知标签到训练集未知标签的知识迁移,来实现对未知标签的识别。然而,这些方法存在以下问题:
-
这些方法只利用预训练语言模型(如 GloVe)的单模态知识,来提取已知和未知标签的 Embedding,如图 1. (b) 所示,而忽视了文本标签的视觉语义信息;
-
尽管 GloVe 等语言模型可以比较好地提取单个 Word 标签的 Embedding,如 ‘Cat’,但是不能很好地扩展到由多个 Word 组成的标签,如 ‘Black Cat’,因而妨碍了模型在词组标签上的识别效果。
单模态的语言模型虽然很好地建模了标签之间的语义一致性,但忽视了图像分类中关键的视觉一致性信息。近来,基于图文预训练模型的 Open Vocabulary 分类模型,在单标签 Open Vocabulary 分类任务上取得了令人印象深刻的效果,但如何将这种能力迁移到多标签场景,仍是亟待探索的问题。
由此,研究者提出了一种基于多模态知识迁移(Multi-modal Knowledge Transfer, MKT)的框架,通过迁移大规模图文预训练模型中的多模态知识,挖掘文本标签中的视觉一致性信息,实现了多标签的 Open Vocabulary 分类。如图 1. (c) 所示,MKT 模型主要包含图像编码器和图文预训练模型的图像、文本编码器。研究者采用知识蒸馏(Knowledge Distillation)和提示学习(Prompt-Tuning)来进一步增强图像和文本 Embedding 的语义一致性,从而更好地迁移图文模型的图文匹配能力。在实践中,知识蒸馏使得图像编码器提取的图像 embedding 更好地与其相对应的文本 Embedding 对齐,而提示学习使得标签 Embedding 更好地适应分类任务。除此之外,为了进一步提升特征表达能力,研究者提出了一种简单有效的双流特征提取模块,同时捕获局部和全局特征,从而增强模型的判别特征表示能力。通过上述设计,MKT 框架可以更好地利用图文模型中丰富的语义信息,迁移多模态知识,更好地识别训练集未知标签。
该研究的主要技术贡献可概括为如下几点:
-
研究者提出了一种基于多模态知识迁移的 Open Vocabulary 多标签识别框架 MKT,利用图文预训练模型中的多模态语义信息,进行未知标签的识别。这是业界首个研究 Open Vocabulary 多标签分类任务的工作。
-
MKT 框架主要包括图像编码器,和图文预训练模型的图像和文本编码器。研究者采用知识蒸馏来保证图像和文本 Embedding 的一致性,并引入提示学习机制来迭代更新标签 Embedding。为进一步增强特征表示能力,研究者提出了双流特征提取模块,同时捕获局部和全局特征。
-
MKT 在 NUS-WIDE 和 Open Images 公开数据集上显著超过了以往的 ML-ZSL 方法,在 Open Vocabulary 多标签分类任务上达到 SOTA。
方法
MKT 总体框图如图 2. 所示,主要包含 Vision Transformer、双流模块(Two-Stream Module)、图文预训练(VLP)Image/Text Encoder 等模块。其中,Vision Transformer 是提取图片语义特征的 Backbone 网络。由于 CLIP 具有强大的图文匹配能力,研究者采用 CLIP 的图像和文本编码器作为图文模型多模态知识的迁移来源。标签 Embedding 由 CLIP 文本编码器产生,并通过提示学习进一步更新。研究者引入知识蒸馏来促进图像和文本 Embedding 的对齐。
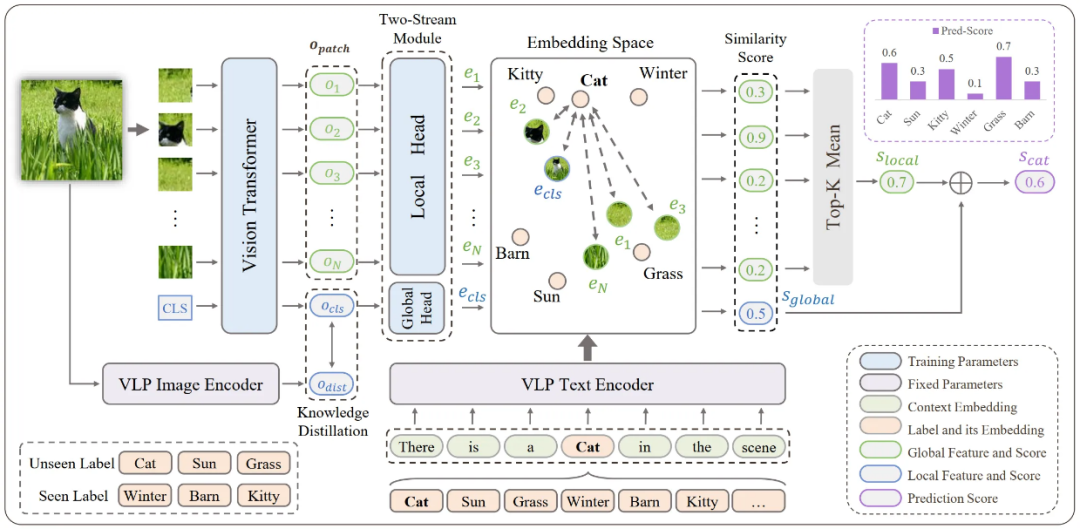
1 Backbone 网络和双流模块
对于一张图片,首先经过分块(Patchify)输入 Vision Transformer 网络,得到表征全局特征的 CLS Feature 和表征局部特征的 Patch Feature,然后分别采用全局 Head 和局部 Head,将全局和局部特征映射到 Embedding 空间,最后采用 TopK 平均的方式得到局部 Head 的相似度分数,与全局 Head 分数求平均得到最终预测分数,并采用排序损失(Ranking Loss)优化模型:
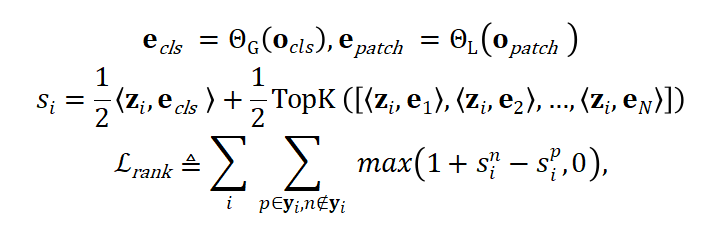
其中 表示图片 i 的标签 Embedding,<.,.>表示内积运算, 表示图片 i 的标签预测分数向量, 表示图片 存在标签的集合,是已知标签集合的子集。
2 知识蒸馏和特征对齐
图像 Embedding 和对应标签 Embedding 的对齐,在从已知标签到未知标签的知识迁移过程中非常重要,对于开放集合多标签分类来说是十分关键的。考虑到 CLIP 模型在预训练阶段进行图文对比训练,产生的图像和文本 Embedding 具有比较高的相似性,研究者采用知识蒸馏来迁移 CLIP 模型的多模态特征表示能力,促进图像 Embedding 和相关文本 Embedding 之间的对齐,蒸馏损失函数如下式:
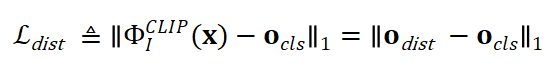
其中 \( o_{cls} \) 是图像全局特征,\( o_{dist} \) 是 CLIP 图像编码器产生的特征。
3 标签 Embedding 的提示学习
参照 CLIP,研究者首先使用固定模板 “There is a {label} in the scene” 作为标签上下文,将标签文本送入 CLIP 文本编码器,从而得到标签 Embedding。由于固定模板的文本与 CLIP 训练时的自然文本存在差异,有理由认为通过这种方式产生的标签 Embedding 不是最优的。因此,最好对标签 Embedding 的产生过程进行进一步 finetune,但是由于训练标签数量有限,直接优化文本编码器容易造成过拟合。受到 CoOp 的启发,研究者采用提示学习,仅优化上下文 Embedding,其余模型参数均固定,这种在 Embedding 空间连续搜索的方式能够促进最优上下文 Embedding 的学习,从而得到更好的标签 Embedding。
4 损失函数
研究者将 MKT 训练过程分为两个阶段。在第一阶段,标签 Embedding 由预训练的 CLIP 文本编码器产生,Backbone 网络和双流模块由排序损失和蒸馏损失联合优化:
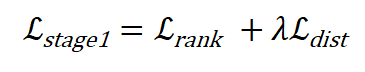
在第二阶段,采用排序损失进行提示学习,只优化标签上下文 Embedding:
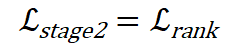
实验
为了验证算法的效果,研究者在 NUS-WIDE 和 Open Images 两个 Benchmark 数据集上进行实验。NUS-WIDE 数据集包含 925 个已知标签,81 个未知标签,161,789 张训练图片,107,859 张测试图片。更具挑战性的 Open Images (v4) 数据集包含 7,186 个已知标签,400 个未知标签,900 万张训练图片,125,456 张测试图片。实验结果见表 1.,可以看出 MKT 相比以往 ML-ZSL 的 SOTA 方法有明显提升,也显著优于直接微调(Fine Tune)CLIP 模型的结果(CLIP-FT)。
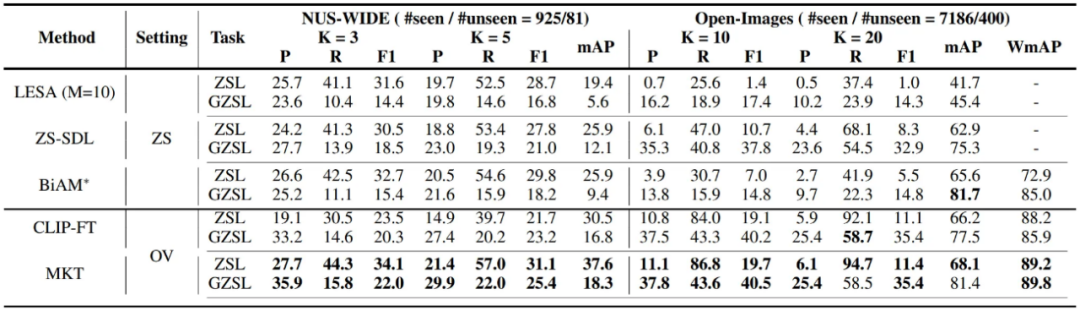
MKT 和 CLIP、BiAM 模型,在 NUS-WIDE 测试集上的示例图片可视化效果对比见图 3.。

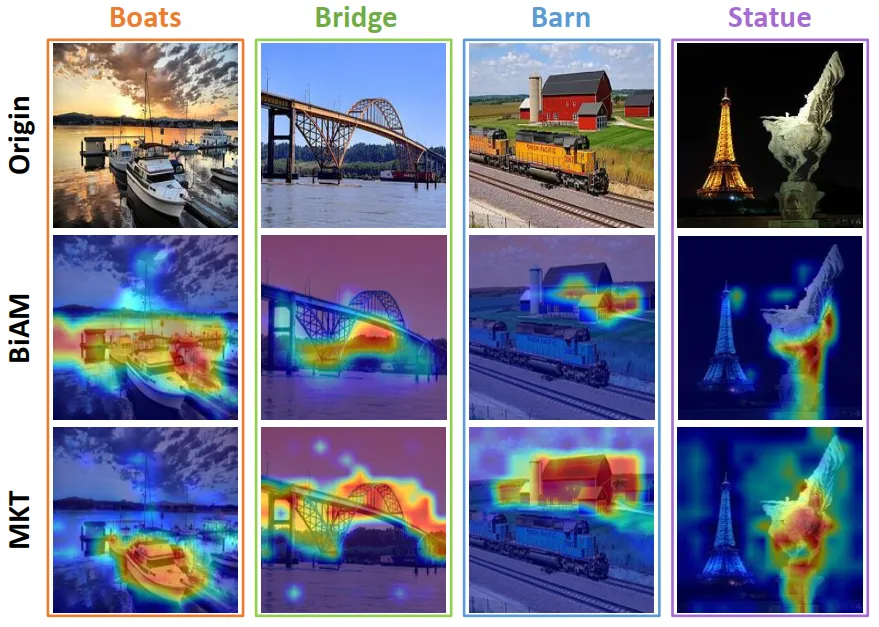
MKT 和 BiAM 的 Grad-CAM 可视化效果对比见图 4.。
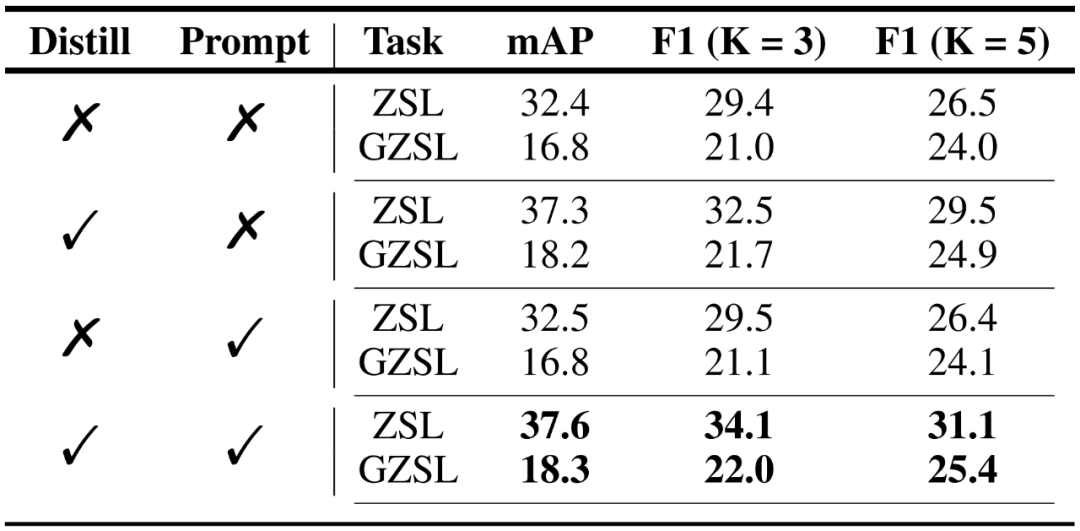
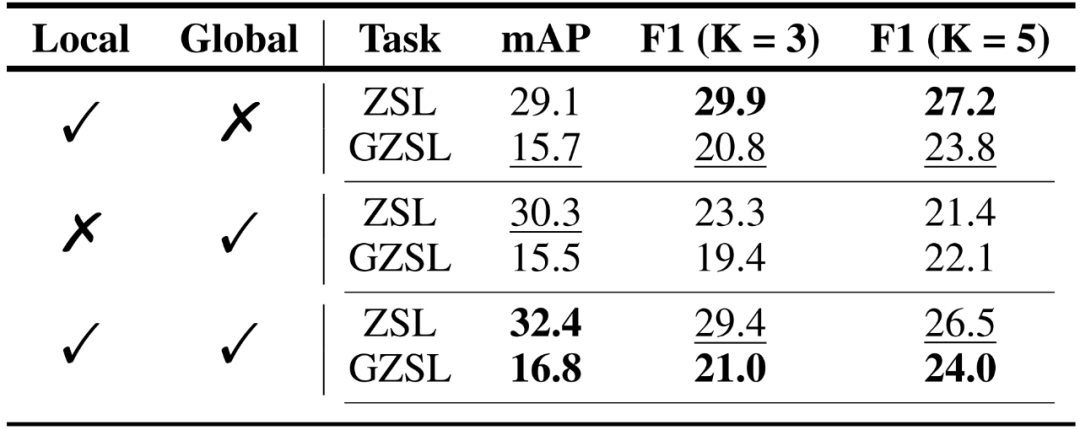
在表 2. 和表 3. 的消融实验中,研究者对知识蒸馏、提示学习和双流模块进行了探索,验证了这些模块对于 MKT 框架多标签识别效果的重要性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢