
OpenAI 的 ChatGPT 风靡全球,仅在 1 月份就迅速积累了超过 1 亿活跃用户。 这是任何应用程序增长到这种规模的最快速度,之前的两个记录保持者是 TikTok 9 个月和 Instagram 2.5 年。 每个人最关心的问题是大型语言模型 (LLM) 对搜索的破坏性有多大。 本周,微软发布了 Bing,将 OpenAI 的技术整合到搜索中,震惊了世界。
这个新的Bing会让谷歌跳出来,我想让人们知道是我们让他们跳出来的。
萨蒂亚·纳德拉,微软 CEO
虽然我们相信谷歌拥有比世界上任何其他公司更好的模型和人工智能专业知识,但他们没有一种有利于实施和商业化其领先技术的文化。 来自 Microsoft 和 OpenAI 的竞争压力正在迅速改变这种情况。
搜索领域的颠覆和创新不是免费的。 正如我们在此处详述的那样,训练LLM的成本很高。 更重要的是,在以任何合理规模部署模型时,推理成本远远超过训练成本。 事实上,每周推理 ChatGPT 的成本超过培训成本。 如果将类似于 ChatGPT 的 LLM 部署到搜索中,则意味着 Google 的 300 亿美元利润直接转移到了计算行业的手中。
今天我们将深入探讨 LLM 在搜索中的不同用途、ChatGPT 的日常成本、LLM 的推理成本、Google 的搜索中断效应和数字、LLM 推理工作负载的硬件要求,包括 Nvidia H100 的性能改进数字和 TPU 成本比较、序列长度、延迟标准、可以调整的各种方法、微软、谷歌和 Neeva 解决这个问题的不同方法,以及我们在此处详述的 OpenAI 下一个模型架构的模型架构如何显着降低成本战线。
搜索业务
首先,让我们定义搜索市场的参数。 我们的消息来源表明,谷歌每秒运行约 320,000 个搜索查询。 将此与谷歌的搜索业务部门进行比较,该部门在 2022 年的收入为 1624.5 亿美元,每次查询的平均收入为 1.61 美分。 从这里开始,谷歌必须为搜索、广告、网络爬虫、模型开发、员工等计算和网络支付大量开销。谷歌成本结构中一个值得注意的项目是他们支付了大约 20 美元 B 成为 Apple 产品的默认搜索引擎。
谷歌服务业务部门的营业利润率为 34.15%。 如果我们为每个查询分配 COGS/运营费用,则每个搜索查询的成本为 1.06 美分,产生 1.61 美分的收入。 这意味着具有 LLM 的搜索查询每次查询的费用必须大大低于 0.5 美分,否则搜索业务对 Google 来说将变得极其无利可图。
我们很高兴地宣布,新的 Bing 正在运行一种新的下一代 OpenAI 大型语言模型,该模型比 ChatGPT 更强大,并且专门针对搜索进行了定制。 它吸取了 ChatGPT 和 GPT-3.5 的重要经验和进步,而且速度更快、更准确、功能更强大。
微软
ChatGPT 费用
由于几个未知变量,估计 ChatGPT 成本是一个棘手的命题。 我们建立了一个成本模型,表明 ChatGPT 每天在计算硬件成本方面的运营成本为 694,444 美元。 OpenAI 需要约 3,617 台 HGX A100 服务器(28,936 个 GPU)来为 Chat GPT 提供服务。 我们估计每次查询的成本为 0.36 美分。
我们的模型是在每次推理的基础上从头开始构建的,但它与 Sam Altman 的推文和他最近接受的采访一致。 我们假设 OpenAI 使用 GPT-3 密集模型架构,参数大小为 1750 亿,隐藏维度为 16k,序列长度为 4k,每个响应的平均令牌为 2k,每个用户 15 个响应,1300 万日活跃用户,FLOPS 利用率在 <2000 毫秒的延迟、int8 量化、纯空闲时间导致的 50% 硬件利用率以及每 GPU 小时 1 美元的成本下,速率比FasterTransformer 高 2 倍。
使用 ChatGPT 搜索费用
如果 ChatGPT 模型被强加到谷歌现有的搜索业务中,其影响将是毁灭性的。 营业收入将减少 360 亿美元。 这是 360 亿美元的 LLM 推理成本。
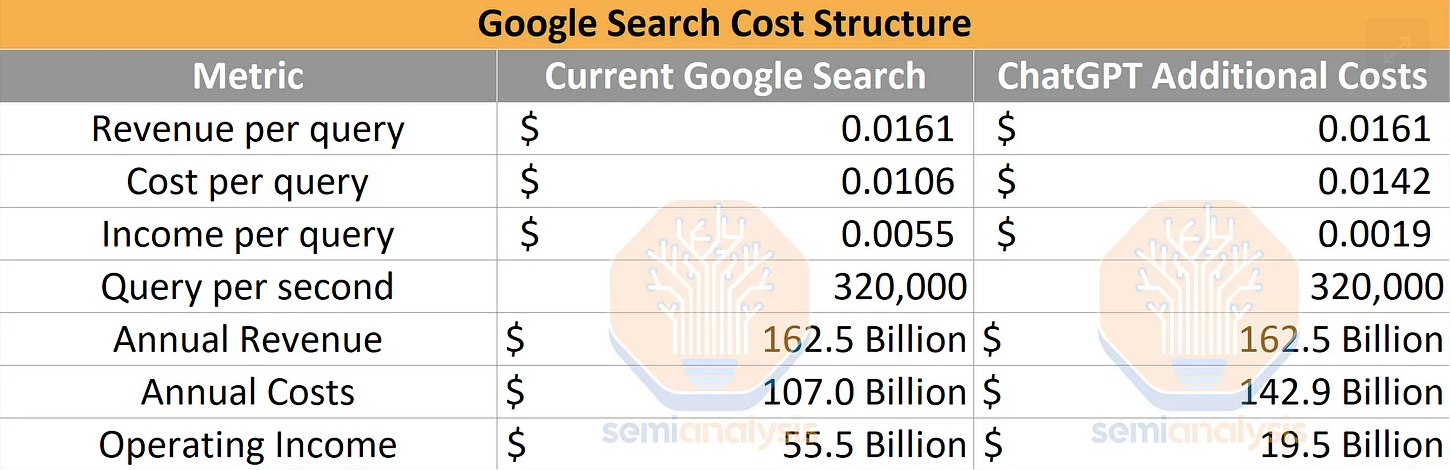
将当前的 ChatGPT 部署到 Google 进行的每次搜索中,需要 512,820.51 A100 HGX 服务器和总共 4,102,568 个 A100 GPU。 这些服务器和网络的总成本仅资本支出就超过 1000 亿美元,其中Nvidia将获得很大一部分。 当然,这永远不会发生,但是如果我们假设没有进行任何软件或硬件改进,那就是有趣的思想实验。 我们还使用谷歌的 TPUv4 和 v5 在订阅者部分建模的推理成本,它们非常不同。 我们也有一些 H100 LLM 推理性能改进数据。
令人惊奇的是,微软知道将 LLM 插入搜索将压垮搜索的盈利能力并需要大量的资本支出。 虽然我们估计了营业利润率的变化,但看看 Satya Nadella 对毛利率的看法。
从现在开始,搜索的(毛利率)将永远下降。
萨蒂亚·纳德拉,微软 CEO
这甚至没有考虑以下事实:随着搜索质量的提高,搜索量可能会有所下降,将广告插入 LLM 的响应中会遇到困难,或者我们将在本报告后面讨论的无数其他技术问题。
微软正在高兴地夸大搜索市场的盈利能力。
在搜索广告市场上每增加一个百分点的份额,我们的广告业务就会获得 20 亿美元的收入机会。
微软
Bing 的市场份额很小。 微软获得的任何份额收益都将给他们带来巨大的顶线和底线财务。
我认为这里对我们都有很大的好处。 我们将发现这些新模型可以做什么。如果我们被搜索垄断,就不得不考虑和新广告单元的货币化方式将面临真正的挑战,甚至可能是暂时的下行压力,我不会对此感觉很好。
这里有这么多的价值,我无法想象我们无法弄清楚如何在上面敲响收银机。
OpenAI 首席执行官 Sam Altman 谈 Stratechery
与此同时,谷歌处于守势。 如果他们的搜索专营权动摇,他们的底线就会出现巨大问题。 由于谷歌在运营成本方面相当臃肿,因此股票损失看起来比上面的分析还要糟糕。
谷歌的回应
谷歌并没有对此视而不见。 在 ChatGPT 发布后的短短几个月内,谷歌就已经将他们的 LLM 搜索版本推向了公共领域。 从我们所看到的Bing与新谷歌的对比来看,各有利弊。
Bing GPT 在 LLM 功能方面似乎更加强大。 谷歌在准确性方面已经存在问题,即使是在他们对这项新技术的舞台演示中也是如此。 如果您同时测量 Bing GPT 和 Google Bard 的响应时间,Bard 在响应时间上压倒了 Bing。 这些模型响应时间和质量差异与模型大小直接相关。
Bard将世界知识的广度与大型语言模型的力量、智慧和创造力相结合。 它利用来自网络的信息来提供新鲜和高质量的回复。 我们最初将与我们的 LaMDA 轻量级模型版本一起发布。 这个小得多的模型需要更少的计算能力,使我们能够扩展到更多的用户,从而获得更多的反馈。
谷歌
谷歌正在通过这种较小的模型在利润率上进行防御。 他们本可以部署他们的全尺寸 LaMDA 模型或功能更强大、更大的 PaLM 模型,但相反,他们选择了更薄的东西。
这是不得已的。
谷歌无法将这些庞大的模型部署到搜索中。 这会严重侵蚀他们的毛利率。 我们将在本报告稍后部分详细讨论 LaMDA 的这种轻量级版本,但重要的是要认识到 Bard 的延迟优势是其竞争力的一个因素。
由于谷歌的搜索收入来自广告,不同的用户每次搜索产生不同的收入水平。 与印度男性农民相比,美国郊区女性平均每个目标广告的收入要高得多。 这也意味着它们也产生了截然不同的营业利润率。
搜索中大型语言模型的未来
Ham 将 LLM 直接投入搜索并不是改进搜索的唯一方法。 多年来,谷歌一直在搜索中使用语言模型来生成嵌入。 这应该会改善最常见搜索的结果,而不会增加推理成本预算,因为这些可以一次生成并提供给许多人。
将 LLM 插入搜索中的最大挑战之一是序列长度增长和低延迟标准。 我们将在下面讨论这些以及它们将如何塑造搜索的未来。
我们还将在 LLM 推理和每次查询成本的背景下讨论 Nvidia A100、H100 和 Google 的 TPU。 我们还将分享 H100 推理性能改进及其对硬件市场的影响。 GPU 与 TPU 的竞争在这场战斗中是与生俱来的。此外,无需新硬件即可显着降低每次推理的成本。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢