
本文作为 Transformer-based 预测模型,它是和计算机视觉中的 ViT 最相似的一篇论文。它成功超过了 DLinear,也证明了 DLinear 中 Transformer可能不适合于序列预测任务的声明是值得商榷的。

本文的核心思想就是 Patching,这和 Preformer 中的核心思想很相似,只不过效果要比 Preformer 好不少。具体来说,它们都是将时间序列分成若干个时间段(Preformer 里用的术语是 segment,本文用的是 patch,实际上是差不多的),每一个时间段视为一个 token(这不同于很多 Transformer-based 模型将每一个时间点视为一个token)。
Preformer 的论文如下:https://arxiv.org/pdf/2202.11356.pdf
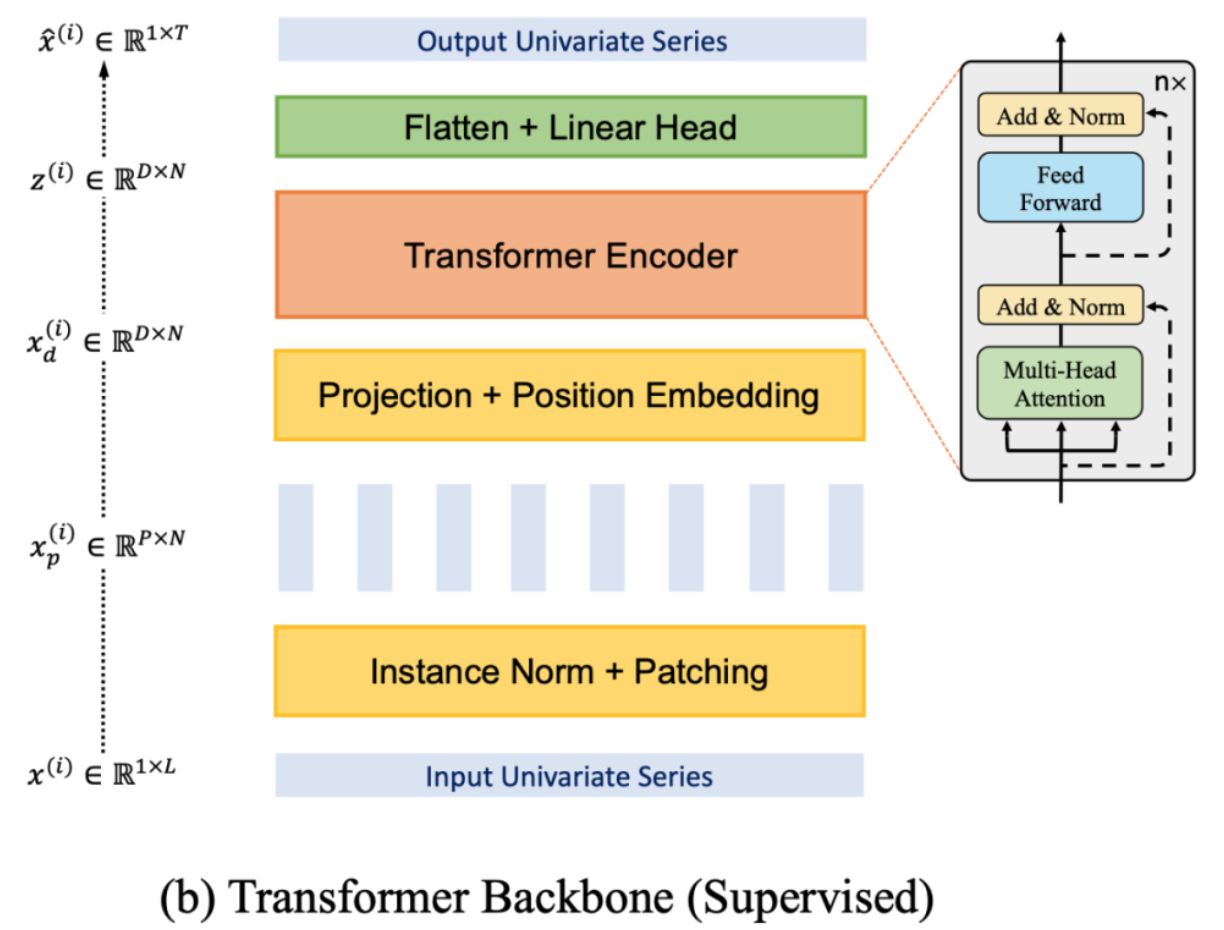
分 patch(时间段)的好处主要有四点:
1.降低复杂度,因为 Attention 的复杂度是和 token 数量成二次方关系。如果每一个patch代表一个token,而不是每一个时间点代表一个token,这显然降低了 token 的数量。
2.保持时间序列的局部性,因为时间序列具有很强的局部性,相邻的时刻值很接近,以一个 patch 为 Attention计算的最小单位显然更合理。
3.方便之后的自监督表示学习,即 Mask 随机 patch 后重建。
4.分 patch 还可以减小预测头(Linear Head)的参数量。如果不分 patch 的话,Linear Head 的大小会是(LD)✖️(MT) , 是输入序列长度,M是序列个数,L是预测序列长度;如果分 patch 的话,Linear Head 的大小是(ND)✖️(T) ,N是 patch 个数要远小于L。因此,分 patch 之后,Linear Head 参数量大大减小,可以防止过拟合。
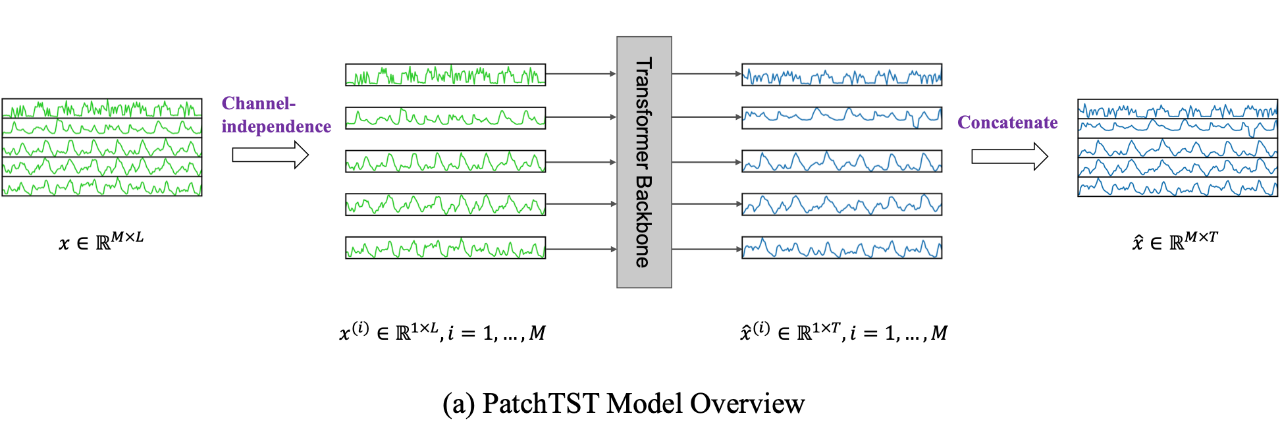
Channel-independence
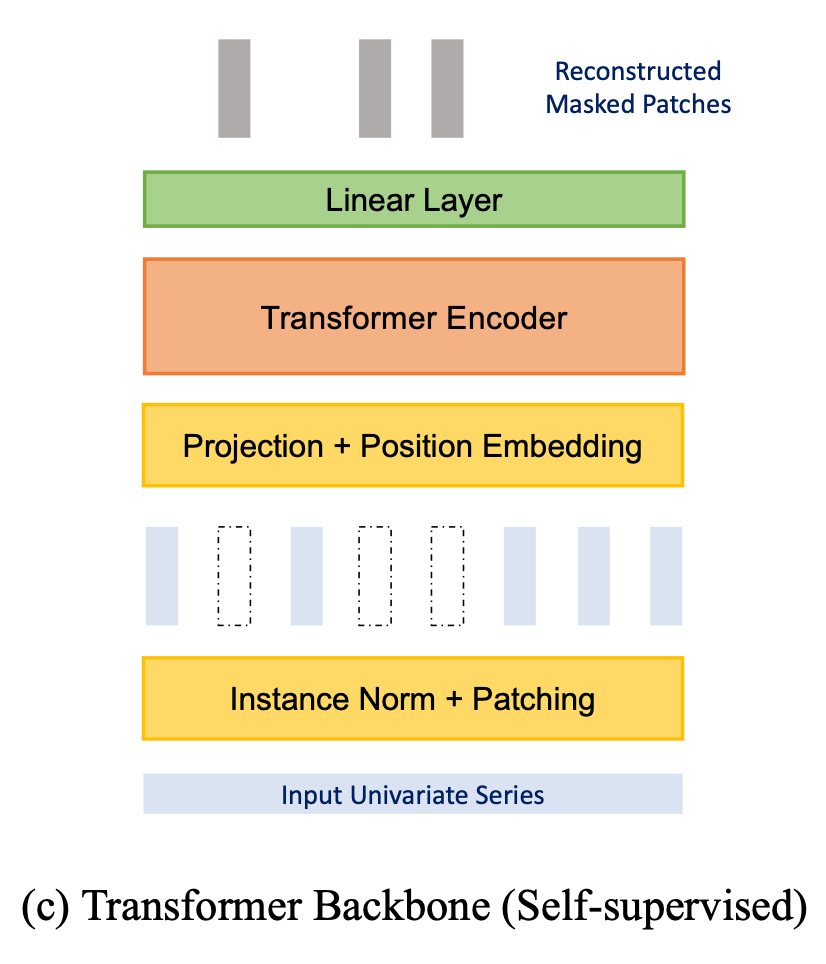
自监督表示学习
实验结果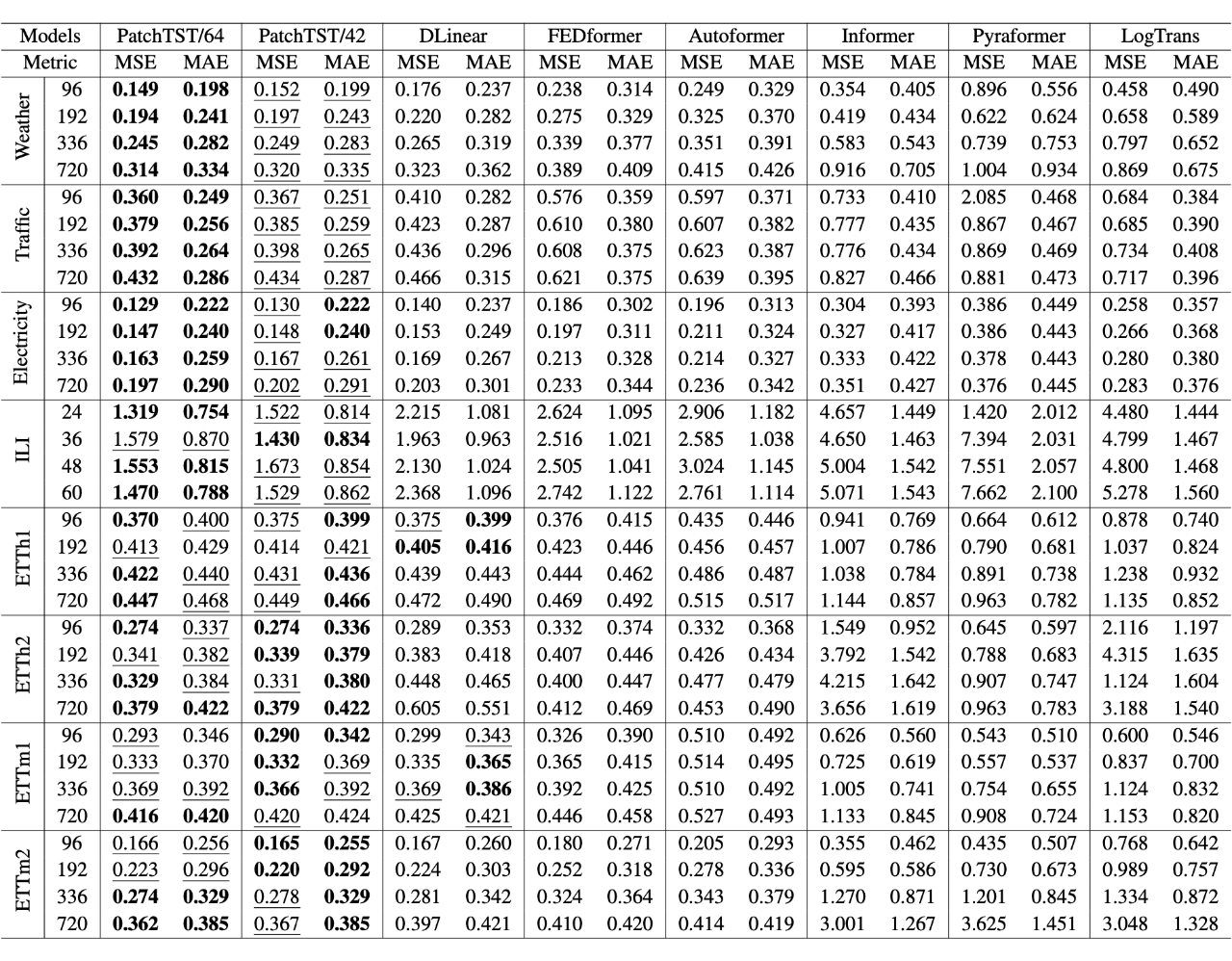
可以看到 PatchTST 的效果超过了 DLinear 以及其它的 Transformer-based 模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢