
来自今天的爱可可AI前沿推介
[AS] Noise2Music: Text-conditioned Music Generation with Diffusion Models
Q Huang, D S. Park, T Wang, T I. Denk, A Ly…
[Google Research]
Noise2Music: 基于扩散模型的文本条件音乐生成
要点:
-
提出名为 Noise2Music 的扩散模型族,以文本提示为条件生成30秒的音乐片段; -
训练并连续利用两类扩散模型,即生成器模型和级联器模型,以生成高保真的音乐; -
探索了音乐的中间表现形式的两种选择,即频谱图和低保真音频,并发现生成的音频能够反映文本提示的元素;
4、 用预训练大型语言模型来生成配对文本并提取文本提示的嵌入,并在训练和生成时、可扩展性和可解释性方面对频谱图和波形图方法进行了比较。
一句话总结:
提出 "Noise2Music",一个利用一系列扩散模型和大型语言模型从文本提示中生成高质量的30秒音乐片段的系统,探索了中间表征的两种选择,生成的音频反映了文本提示的关键元素,并超越了ground细粒度语义。
摘要:
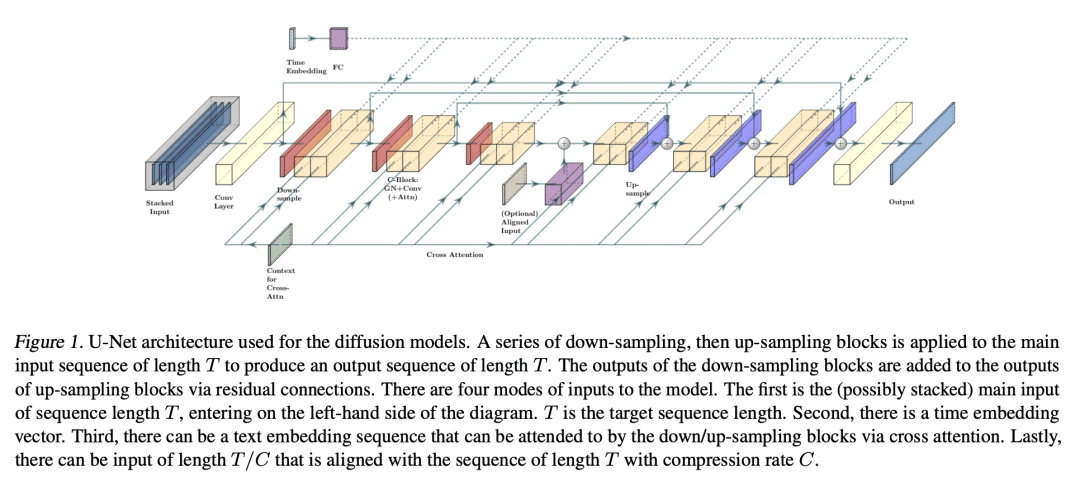
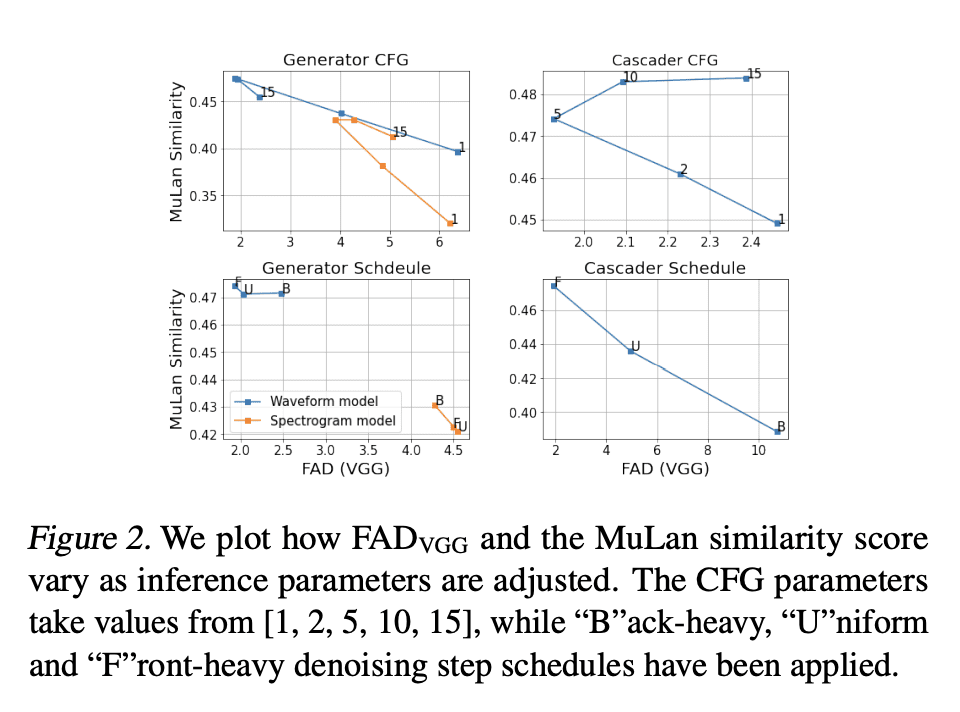
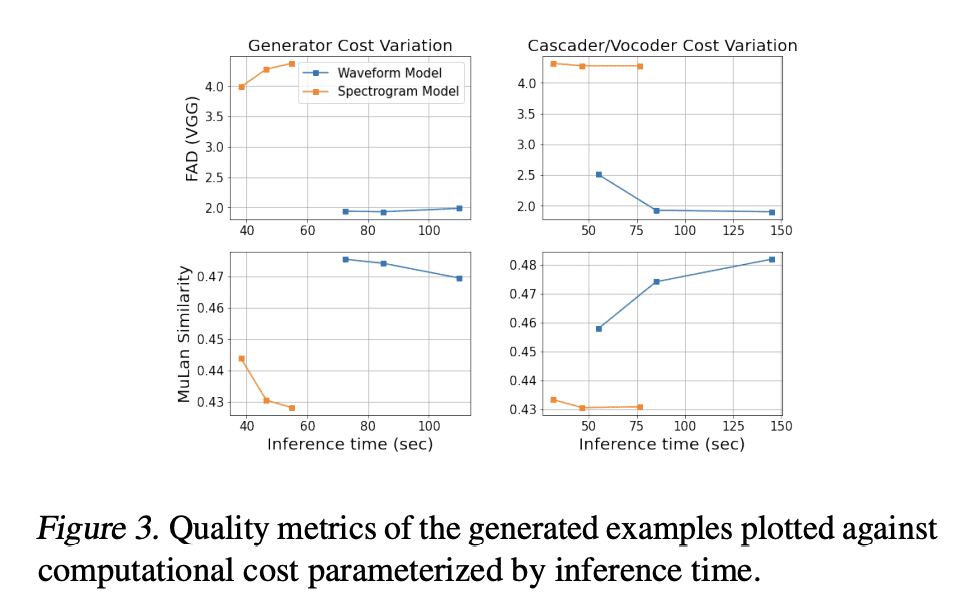
提出 Noise2Music,其中一系列扩散模型被训练用来从文本提示中生成高质量的30秒音乐片段。两种类型的扩散模型,一种是生成器模型,以文本为条件生成中间表征,另一种是级联器模型,以中间表征和可能的文本为条件生成高保真音频,被连续训练和利用来生成高保真音乐。本文探讨了中间表示的两种选择,一种是使用频谱图,另一种是使用低保真度音频。结果发现,生成的音频不仅能够忠实地反映文本提示的关键元素,如流派、节奏、乐器、情绪和时代,还能超越ground提示细粒度语义。预训练的大型语言模型在其中发挥了关键作用——被用来为训练集的音频生成配对文本,并提取由扩散模型摄入的文本提示的嵌入。
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: this https URL
论文链接:https://arxiv.org/abs/2302.03917
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢