
来自今天的爱可可AI前沿推介
[LG] Leveraging Demonstrations to Improve Online Learning: Quality Matters
B Hao, R Jain, T Lattimore, B V Roy, Z Wen
[Deepmind]
利用演示数据改善在线学习:质量很重要
要点:
-
调查离线演示数据对在线学习的影响; -
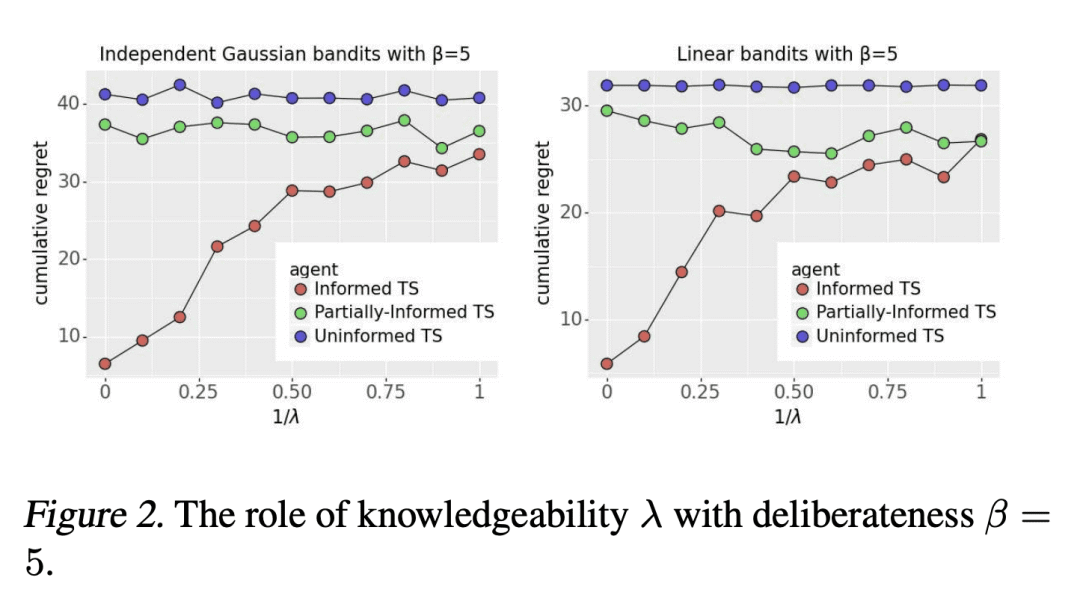
引入"专家能力水平”的概念,作为演示数据质量的衡量标准; -
提出一种通过贝叶斯法则利用演示数据的知情汤普森采样算法; -
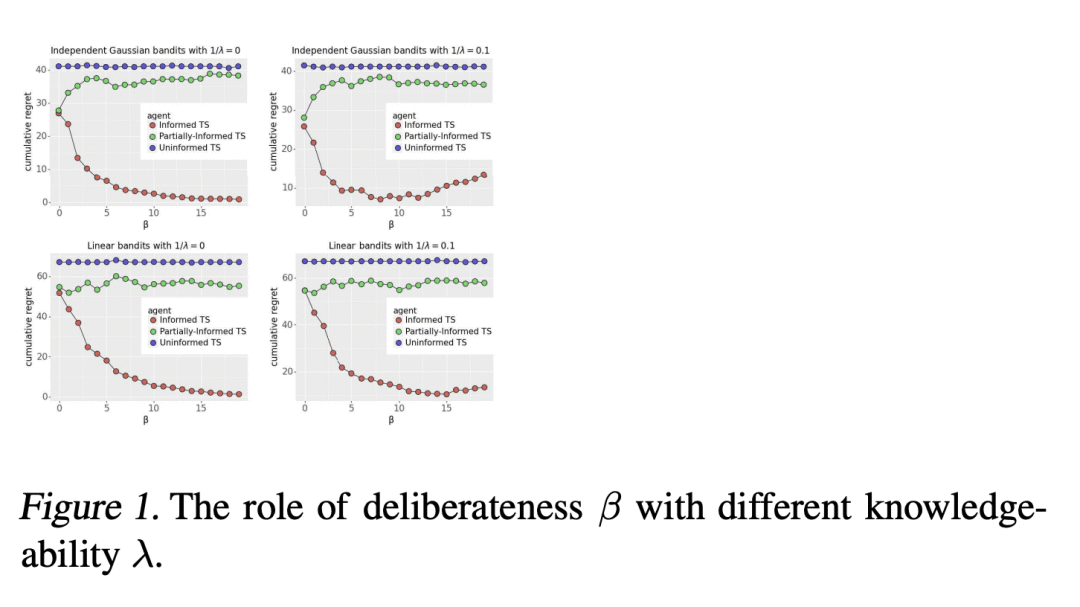
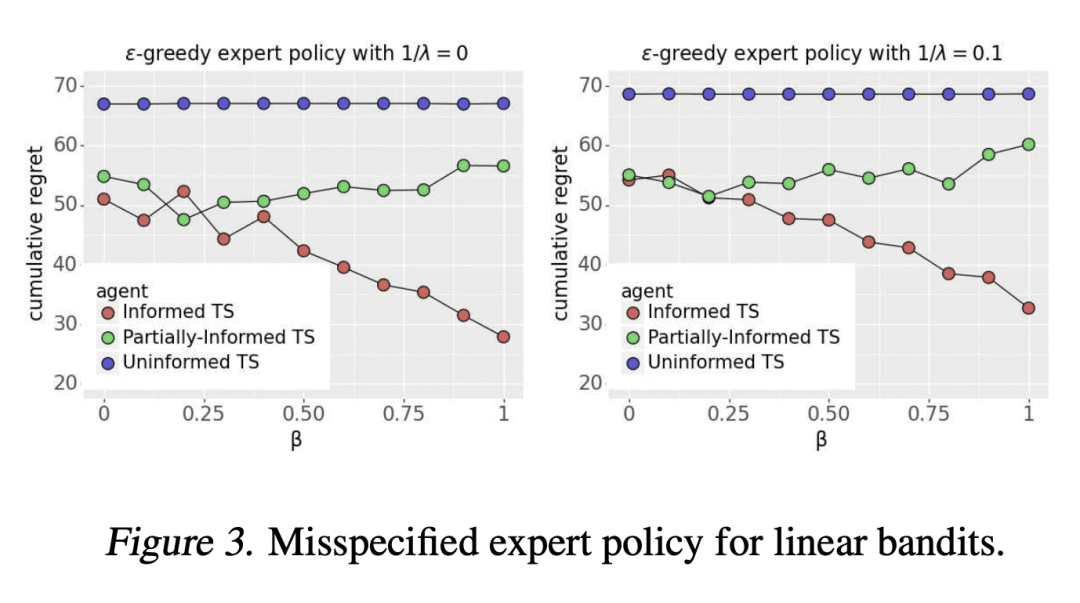
经验证明,通过使用由演示数据和专家能力水平提供信息的汤普森采样算法,大大减少了遗憾。
一句话总结:
研究了使用离线演示数据对在线学习的影响,发现演示数据的质量对改进至关重要,提出了一种通过贝叶斯法则利用演示数据的知情汤普森采样算法,建立了一个依赖先验的贝叶斯遗憾界,并通过贝叶斯 bootstrapping 开发了一种实用的近似算法。
摘要:
本文研究了离线演示数据能在多大程度上改善在线学习。期待一些改进是很自然的,但问题是如何改进,以及改进多少?本文表明,改进的程度必须取决于演示数据的质量。为了产生可迁移的见解,本文把汤普森采样(TS)作为在线学习算法和模型的原型应用于多臂老虎机。演示数据是由一个具有特定能力水平的专家产生的,这是本文引入的一个概念。本文提出了一种知情的TS算法,该算法通过贝叶斯规则以一种连贯的方式利用演示数据,并推导出一种依赖先验的贝叶斯遗憾约束。使得能深入了解预训练如何能极大提高在线性能,以及改进的程度如何随着专家能力水平的提高而增加。本文还通过贝叶斯 bootstrapping 开发了一种实用的、近似的知情TS算法,并通过实验显示了大量的经验性遗憾减少。
We investigate the extent to which offline demonstration data can improve online learning. It is natural to expect some improvement, but the question is how, and by how much? We show that the degree of improvement must depend on the quality of the demonstration data. To generate portable insights, we focus on Thompson sampling (TS) applied to a multi-armed bandit as a prototypical online learning algorithm and model. The demonstration data is generated by an expert with a given competence level, a notion we introduce. We propose an informed TS algorithm that utilizes the demonstration data in a coherent way through Bayes' rule and derive a prior-dependent Bayesian regret bound. This offers insight into how pretraining can greatly improve online performance and how the degree of improvement increases with the expert's competence level. We also develop a practical, approximate informed TS algorithm through Bayesian bootstrapping and show substantial empirical regret reduction through experiments.
论文链接:https://arxiv.org/abs/2302.03319
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢