
来自今天的爱可可AI前沿推介
[LG] Sketchy: Memory-efficient Adaptive Regularization with Frequent Directions
V Feinberg, X Chen, Y. J Sun, R Anil, E Hazan
[Google Research & Princeton University]
Sketchy: 基于频繁方向的内存高效自适应正则化
要点:
-
提出一种低秩概要的方法,以减少自适应正则化方法中的内存和计算要求; -
利用了深度学习训练任务中 Kronecker 系数梯度协方差矩阵的谱集中在一个小的主导特征空间上; -
通过对频繁方向(FD)概要应用动态对角线正则化,在内存约束下,全矩阵 AdaGrad 遗憾可以恢复到加性谱项。
一句话总结:
提出一种内存高效的自适应正则化方法,使用频繁方向概要来减少深度学习训练任务的内存和计算要求。
摘要:
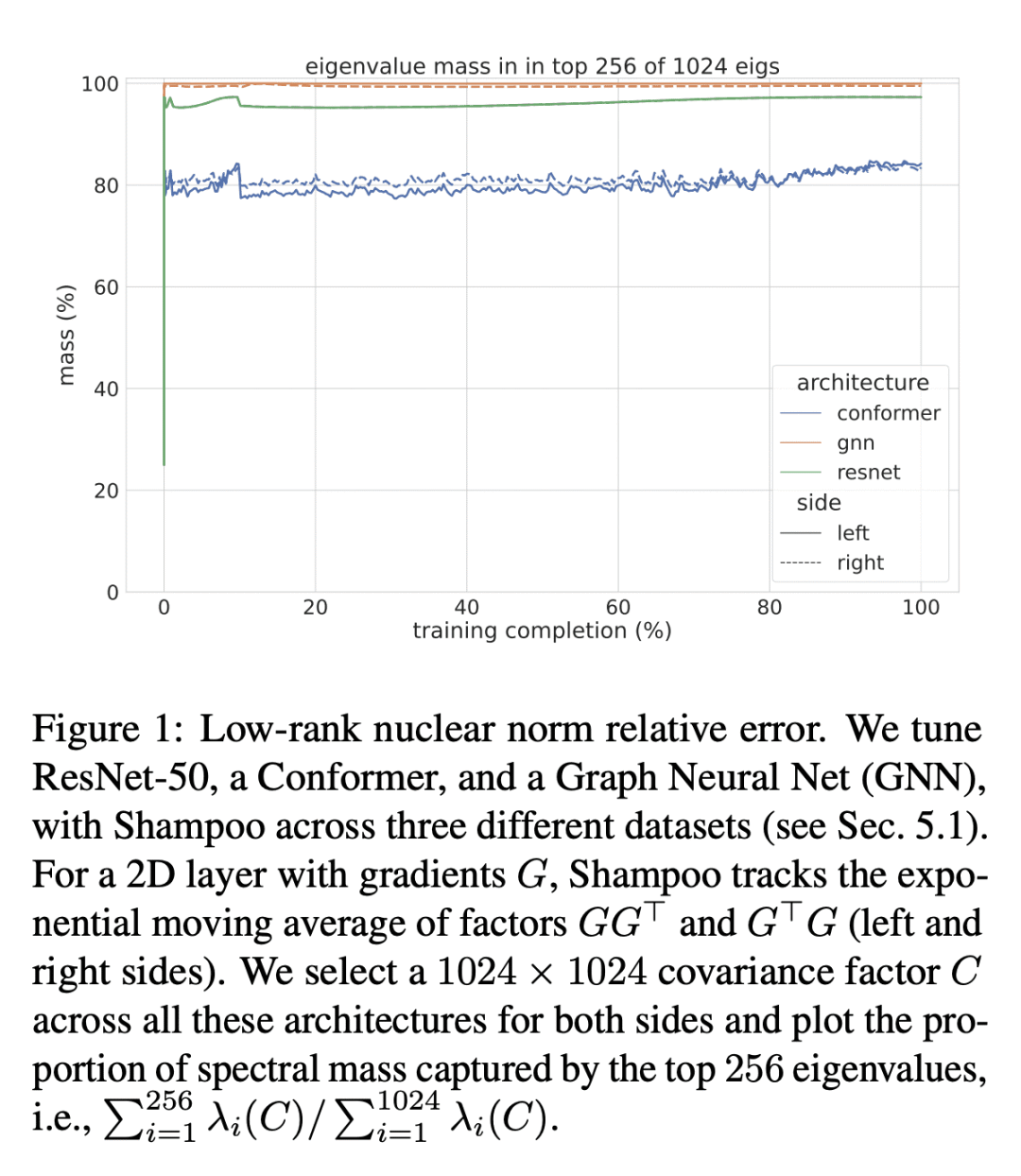
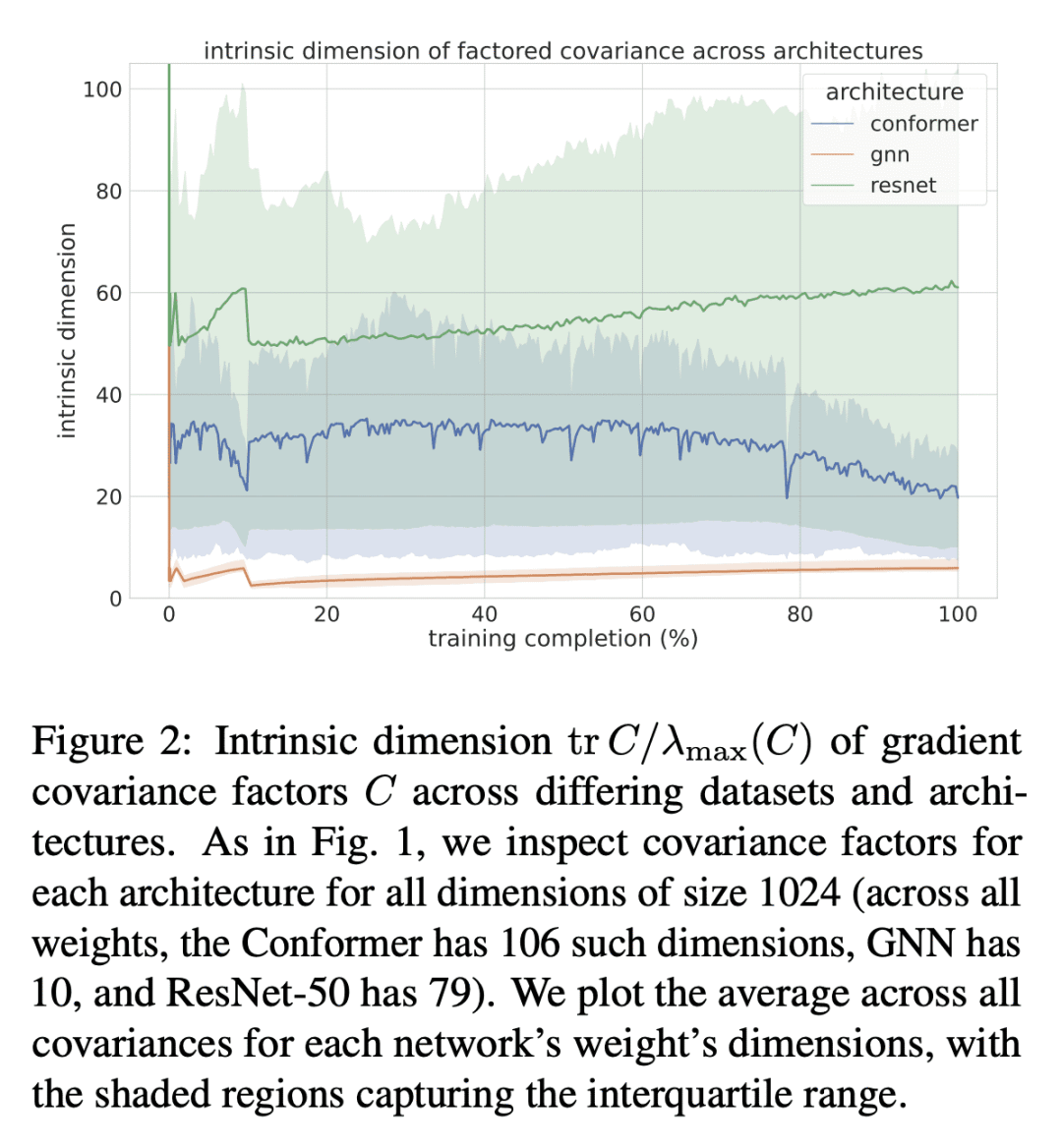
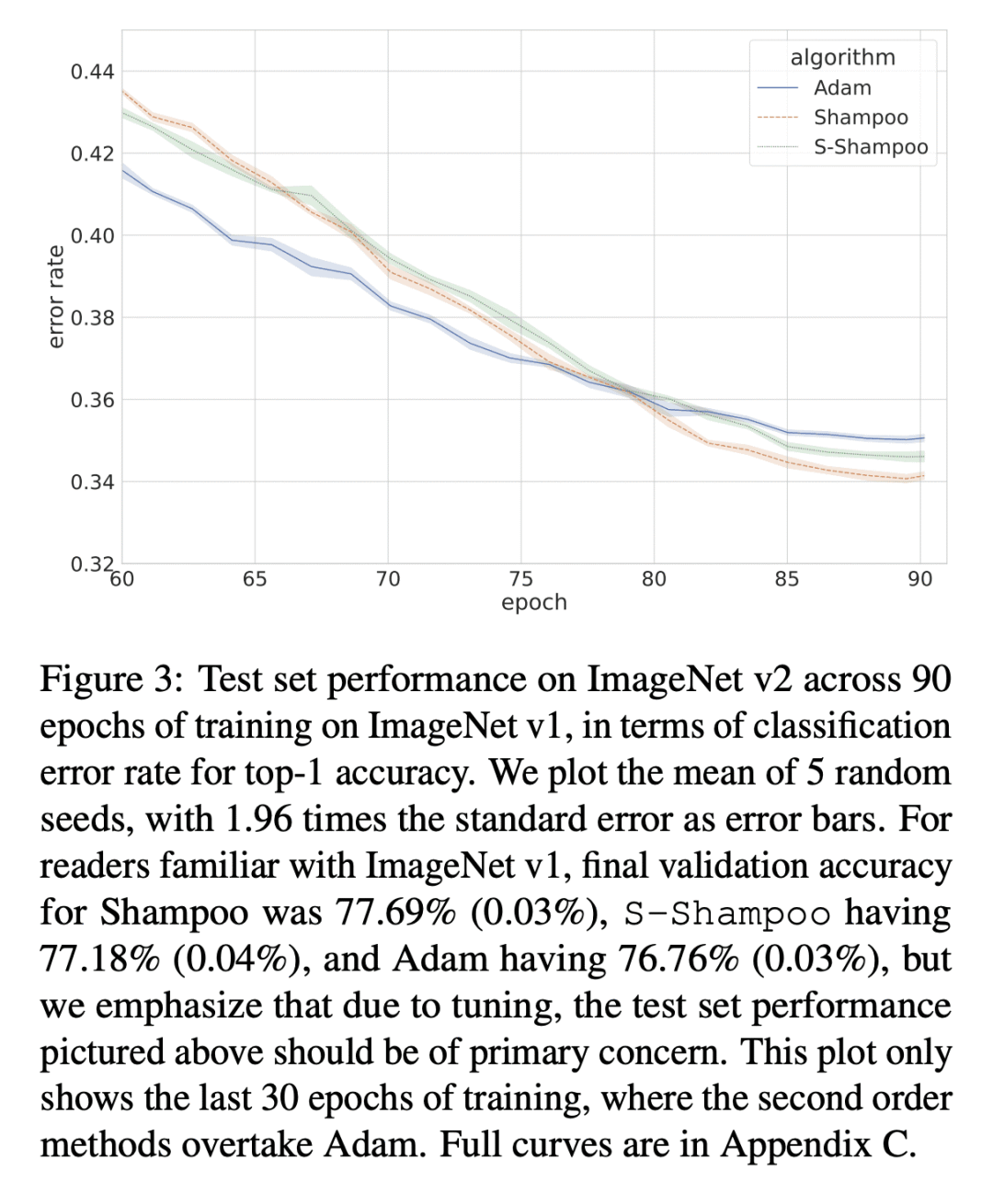
利用超出对角项的自适应正则化方法在许多任务中表现出最先进的性能,但在内存和运行时间方面可能是令人望而却步的。本文发现深度学习(DL)训练任务中的 Kronecker 系数梯度协方差矩阵的谱集中在一个小的主导特征空间上,这个特征空间在整个训练过程中会发生变化,这促使我们采用低秩概要方法。本文描述了一种通用的方法,以减少用频繁方向(FD)概要维护矩阵预调节器的内存和计算要求。所提出技术允许在资源要求和遗憾保证随秩 k 的下降之间进行插值:在维度为 d 的在线凸优化(OCO)设置下,只用 d-k 内存来匹配全矩阵 d2 内存的遗憾,直到梯度协方差的底部 d-k 特征值的加性误差。此外,本文展示了对 Shampoo 的扩展,将该方法置于几个大规模基准的内存-质量帕累托前沿。
Adaptive regularization methods that exploit more than the diagonal entries exhibit state of the art performance for many tasks, but can be prohibitive in terms of memory and running time. We find the spectra of the Kronecker-factored gradient covariance matrix in deep learning (DL) training tasks are concentrated on a small leading eigenspace that changes throughout training, motivating a low-rank sketching approach. We describe a generic method for reducing memory and compute requirements of maintaining a matrix preconditioner using the Frequent Directions (FD) sketch. Our technique allows interpolation between resource requirements and the degradation in regret guarantees with rank k: in the online convex optimization (OCO) setting over dimension d, we match full-matrix d2 memory regret using only dk memory up to additive error in the bottom d−k eigenvalues of the gradient covariance. Further, we show extensions of our work to Shampoo, placing the method on the memory-quality Pareto frontier of several large scale benchmarks.
论文链接:https://arxiv.org/abs/2302.03764
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢