
作者:Z Yang, W Ping, Z Liu, V Korthikanti, W Nie, D Huang, L Fan, Z Yu...
[NVIDIA & UIUC]
要点:
-
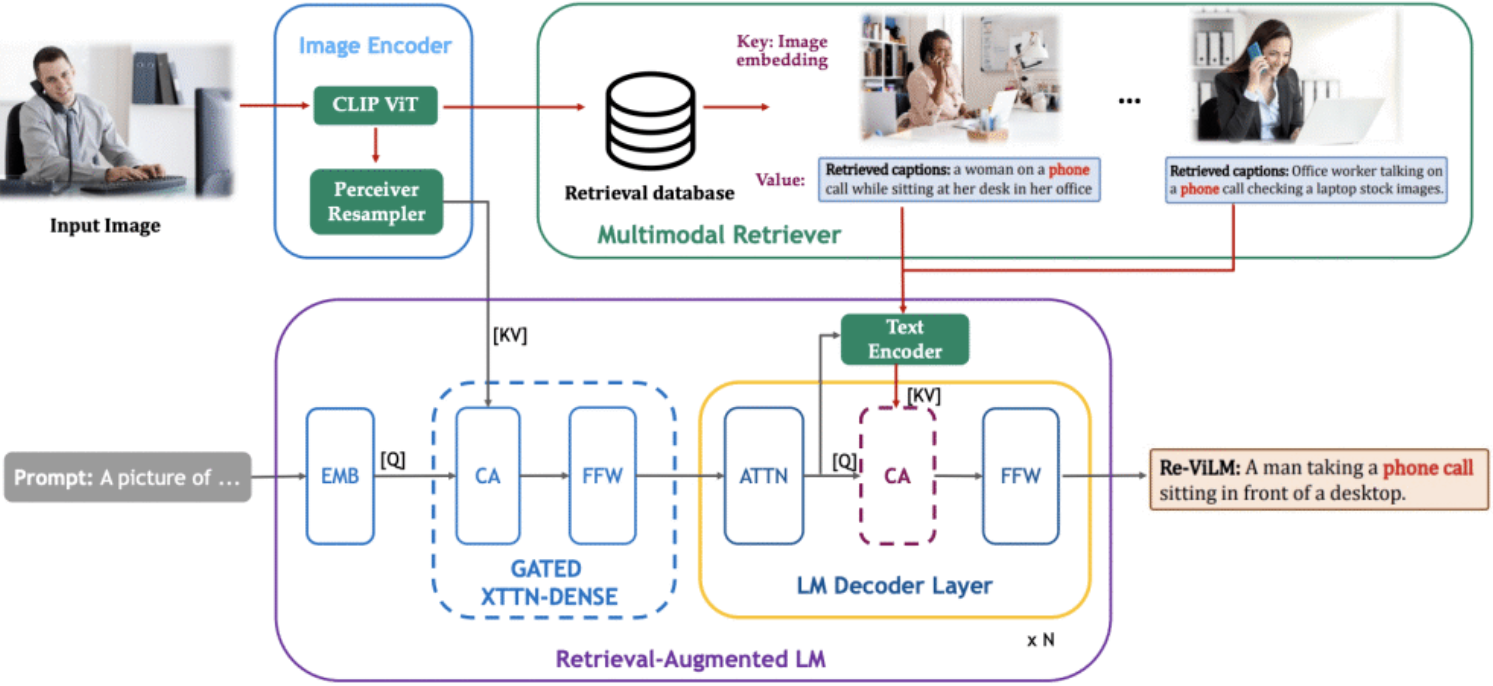
Re-ViLM是一个用于图像到文本生成的检索增强型视觉语言模型,建立在 Flamingo 架构基础上; -
Re-ViLM通过从外部数据库检索相关知识,减少了模型参数的数量,并能有效地纳入新数据; -
Re-ViLM用RETRO初始化,RETRO是一个预训练检索增强语言模型,在多模态预训练的开始就整合了检索能力。 -
Re-ViLM在检索时采用了简单的过滤策略,以避免"复制粘贴"行为,并采用了新的交错图像-文本数据集进行预训练,有利于在上下文中进行少样本学习。
总结:
提出一种检索增强视觉语言模型(Re-ViLM),通过整合多模态检索器和检索增强语言模型层,从外部数据库中检索相关知识,增强了最先进的视觉语言模型 Flamingo,用于零样本和少样本的图像描述。
摘要:
用视觉编码器(如 Flamingo)增强预训练语言模型(LM),在图像到文本生成中获得了最先进的结果。然而,这些模型将所有的知识存储在参数中,往往需要巨大的模型参数来为丰富的视觉概念和非常丰富的文本描述建模。此外,它们在纳入新数据方面效率低下,需要一个计算成本高昂的微调过程。本文提出一个检索增强的视觉语言模型,Re-ViLM,建立在 Flamingo 的基础上,支持从外部数据库中检索相关知识,以实现零样本和上下文少样本图像到文本的生成。通过在外部数据库中显式存储某些知识,该方法减少了模型参数的数量,并且在评估过程中只需更新数据库就能轻松容纳新数据。本文还构建了一个交错的图像和文本数据,以促进内涵式的少样本学习能力。本文证明,Re-ViLM 极大地提高了图像到文本生成任务的性能,特别是在域外设置中的零样本和几样本生成,与基线方法相比,参数少了4倍。
Augmenting pretrained language models (LMs) with a vision encoder (e.g., Flamingo) has obtained state-of-the-art results in image-to-text generation. However, these models store all the knowledge within their parameters, thus often requiring enormous model parameters to model the abundant visual concepts and very rich textual descriptions. Additionally, they are inefficient in incorporating new data, requiring a computational-expensive fine-tuning process. In this work, we introduce a Retrieval-augmented Visual Language Model, Re-ViLM, built upon the Flamingo, that supports retrieving the relevant knowledge from the external database for zero and in-context few-shot image-to-text generations. By storing certain knowledge explicitly in the external database, our approach reduces the number of model parameters and can easily accommodate new data during evaluation by simply updating the database. We also construct an interleaved image and text data that facilitates in-context few-shot learning capabilities. We demonstrate that Re-ViLM significantly boosts performance for image-to-text generation tasks, especially for zero-shot and few-shot generation in out-of-domain settings with 4 times less parameters compared with baseline methods.



![]()
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢