

论文链接:https://arxiv.org/abs/2210.13382
代码链接:https://github.com/likenneth/othello_world
导读
随着ChatGPT的强势登场,以GPT-3系列为代表的大型语言模型(large language models,LLMs)目前俨然成为了AI界的焦点话题,ChatGPT的爆火也吸引了众多非自然语言处理(NLP)社区的研究者们介入其中,研究其背后的关键技术原理。这些研究更启发了大型语言模型在除智能对话、文本生成等传统NLP任务之外的广泛发展和应用。
本文介绍一篇刚被国际人工智能表征顶会ICLR2023录用为Oral的论文,作者来自哈佛大学、麻省理工学院和美国东北大学。本文作者提出了一个关键的问题,即研究探索LLMs的惊人语言能力的内部机制,这些模型是仅仅通过记忆训练数据实现了直观上的统计能力,还是依赖于它们对输入序列的内部建模过程的学习呢?
作者选取了一个非常有趣的切入点,即通过一种棋盘游戏Othello进行研究,Othello又称“黑白棋”,是一种经典的棋盘对弈游戏。作者为其量身定制了一个GPT模型变体,称为Othello-GPT,Othello-GPT的训练目标是预测每一步的棋子位置来战胜对手,这一做法与当年的AlphaGo类似,只不过AlphaGo背后的人工智能技术是强化学习。尽管参与研究的GPT模型本身并没有针对黑白棋游戏规则和技巧的先验知识,但作者仍然从中发现了其针对棋盘状态构建出了一种高效的非线性表征。通过进一步施加干预实验,发现这种表征可以被用来控制网络的输出,进而作者提出了可以对LLMs内部机制进行解释的“嵌入显著性图”(latent saliency maps)。
引言
目前引发大家火热关注的是LLMs的智能对话能力和在对某些专业领域的知识解析功能,这些功能可以简单概括为一种模型“对下一个词”的预测任务,最为典型的案例就是利用ChatGPT解决一些行业内的逻辑问题和编写基本的程序代码。
然而,这些功能是如何从序列预测任务中学习到的呢,这仍然是目前研究的热点。有些研究者认为,这种对序列建模任务的训练机制本身具有一定的局限性,训练模型得到的预测能力极有可能是来自于其通过记忆训练数据达到的“表面统计(surface statistics)”现象,表面统计可能会因为一些本身不相关的训练序列而引入因果混杂,这将导致模型在实际场景中做出错误预测。另一方面,现有语言模型表现出来的,是一种可以应用于多种场景中的world models可解释能力,world models可以轻松理解一些基础性常识性的概念,并在它们的基础上生成更多相关的概念。
本文作者将棋盘看做是一种“世界”视角,因为棋盘上的落子顺序也可以看作是一种序列数据,并且其相对于自然语言的数据分布具有更为友好的复杂度,使用这种数据训练得到的GPT模型可以精确跟踪棋盘状态,并且做出非常合理的落子预测。作者随后对模型内部的表征进行了研究,并且引入了一组探针(probes),本质上是一些分类器,它允许我们从网络内部的激活中来推导棋盘状态,这种类型的探针目前已成为分析神经网络的标准工具[1]。最后,作者希望通过在这种简化的“世界”场景中对语言模型world models能力的探索结论最终也能在自然语言环境中发挥作用。
方法
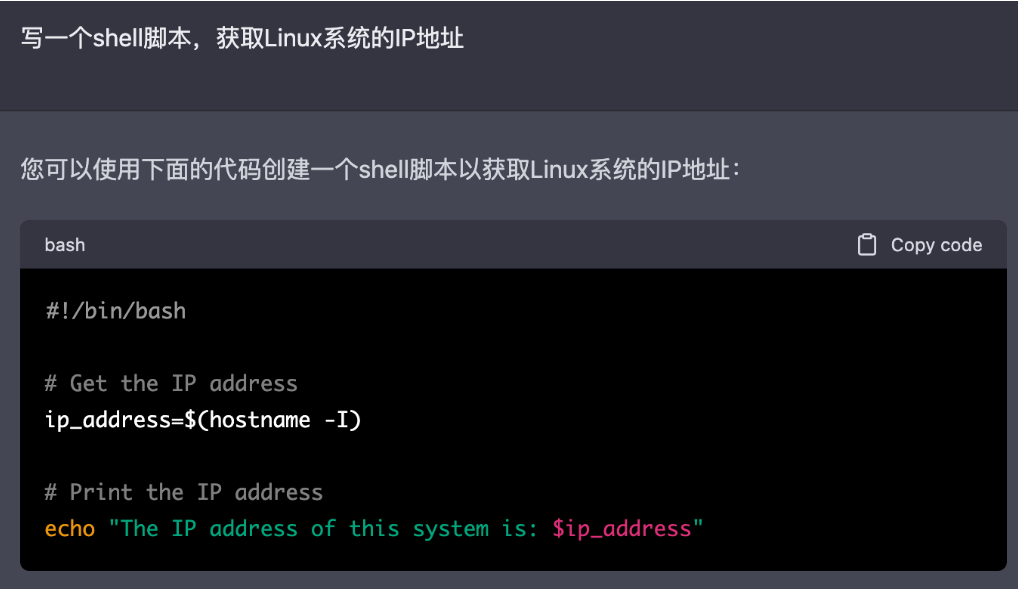
Othello是一种经典且流行的黑白棋游戏(如下图所示),其规则是在一个8x8的棋盘上的中心位置,先放入四个棋子,黑白各两个。然后双方轮流下子,在直线或斜线方向,己方两子之间的所有敌子(不能包含空格)全部变为己子(称为吃子),每次落子必须有吃子。最后棋盘全部占满,子多者为胜。选取Othello的主要原因是因为它的规则相比国际象棋更为简单,而且它的棋盘搜索空间也足够大可以避免模型直接对其进行记忆。
作者首先训练了一个Othello-GPT模型来对棋盘落子位置进行预测。在训练阶段,作者将一些具有符合规则的棋盘游戏数据送入模型中,其中的每个token代表一个落子方块,并且为了公平起见,参与训练的棋盘数据分布较为均衡,其中没有使模型总是取胜的倾向。
1 训练Othello-GPT
作者对Othello-GPT准备了两组数据,分别是"championship"和"synthetic",两个数据集具有不同的数据质量和规模,其中championship数据集是从两个Othello冠军赛数据网站上收集得到,分别包含7605和132921场比赛。它们被合并并按8:2的比例随机分成训练集和验证集。championship数据集反映了专家级人类玩家的战略数据。synthetic数据集是通过计算机合成得到,其包含有2000万场比赛数据用于训练,3,796,010场比赛数据用于验证,相比之下,synthetic数据集要大得多,其包含了随机且符合游戏规则的落子信息。
作者以自回归方式训练了一个8层GPT模型,其中attention head数量为8,隐藏层维度为512,对于每组游戏数据 \( \left\{y_{t}\right\}_{t=0}^{T-1} \) ,计算过程从一个由60个向量组成的可训练词嵌入开始,每个向量代表一个棋盘方块,得到 \( \left\{x_{t}^{0}\right\}_{t=0}^{T-1} \) ,其中从第 层之后到第 个层的中间特征表示为 \( x_{t}^{l} \) 。最后,\( x_{T-1}^{8} \) 通过一个线性分类器来预测 \( \hat{y}_{T} \) 的logits,并通过交叉熵损失进行优化。
2 Othello-GPT的内部表征并不是表面统计
在模型训练结束后,作者对Othello-GPT进行了落子预测评估,评价指标使用top-1错误率,在synthetic数据集上训练的Othello-GPT的错误率为0.01%,在championship数据集上训练的Othello-GPT的错误率为 5.17%。而未经任何训练的Othello-GPT的错误率为 93.29%。这表明,通过棋盘数据的训练,Othello-GPT基本上可以作出正确的落子预测。但是并不排除其将整个训练数据集记忆的可能,为了测试这种可能性,作者采样了一个由2000万盘棋构成的有偏数据集来替换synthetic数据集进行训练。具体表现为,在每盘游戏的开始,先手玩家有四种可能的开局位置,在这个有偏数据集中,作者截断了其中一个开局位置,相当于删除了整个搜索空间的四分之一,结果这样训练得到的Othello-GPT仍然获得了0.02%的错误率,这可以证明Othello-GPT的预测能力并不是来源于对棋盘数据的记忆。
实验
使用探针探索Othello-GPT的内部表示
为了对Othello-GPT的模型内部进行分析,作者引入了一系列探针,探针本质上是一个分类器或回归器,其输入由网络的内部激活组成,它被训练来预测一个具有具有代表性的模型特征,例如可以预测一段语音中的部分片段。如果仅通过网络的激活值就能训练出一个准确无误的探针,这表明该特征的表示被编码在网络的激活连接中。
作者从神经网络的特性出发,设计了两种探针,分别是线性探针和非线性探针,其中线性探针的函数可以写成\( p_{\theta}\left(x_{t}^{l}\right) = \text{softmax}\left(W x_{t}^{l}\right) \)其中 \( \theta=\left\{W \in \mathbb{R}^{F \times 3}\right\} \) , 是输入 \( x_{t}^{l} \) 的维数。实验结果表明,线性探针的错误率很高,具体如下表所示,线性探针在三个数据集上的错误率都不低于20%,这表明Othello-GPT针对棋盘状态的内部表示并不是简单的线性形式。
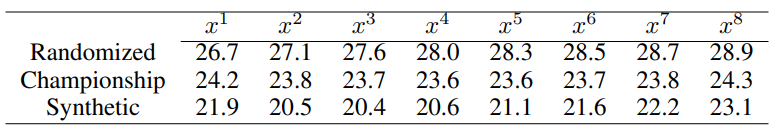
进而作者发现,非线性探针的错误率较低,非线性探针的结构为两层MLP,其函数可以写成 \( p_{\theta}\left(x_{t}^{l}\right)=\text{softmax}\left(W_{1} \text{ReLU}\left(W_{2} x_{t}^{l}\right)\right) \),其中 \( \theta=\left\{W_{1} \in \mathbb{R}^{H \times 3}, W_{2} \in \mathbb{R}^{F \times H}\right\} \)。 是非线性探针的隐藏维数。

如上表所示,非线性探针的性能在绝对值上明显优于线性探针。
因果干预实验
虽然Othello-GPT的内部表征呈现非线性的特点,但是其对模型的预测是否具有因果关系尚不明确,因而作者进行了一组干预性实验,来确定模型预测与棋盘世界表征之间的因果关系。整体的干预过程如下图所示,为了对棋盘状态 干预为版本 ,首先需要确定(a)在哪些层中修改激活,以及 (b) 如何修改这些激活。这里作者选择了网络中的一个初始层 ,然后修改它和以及它后续的激活状态,如下图(c)所示。
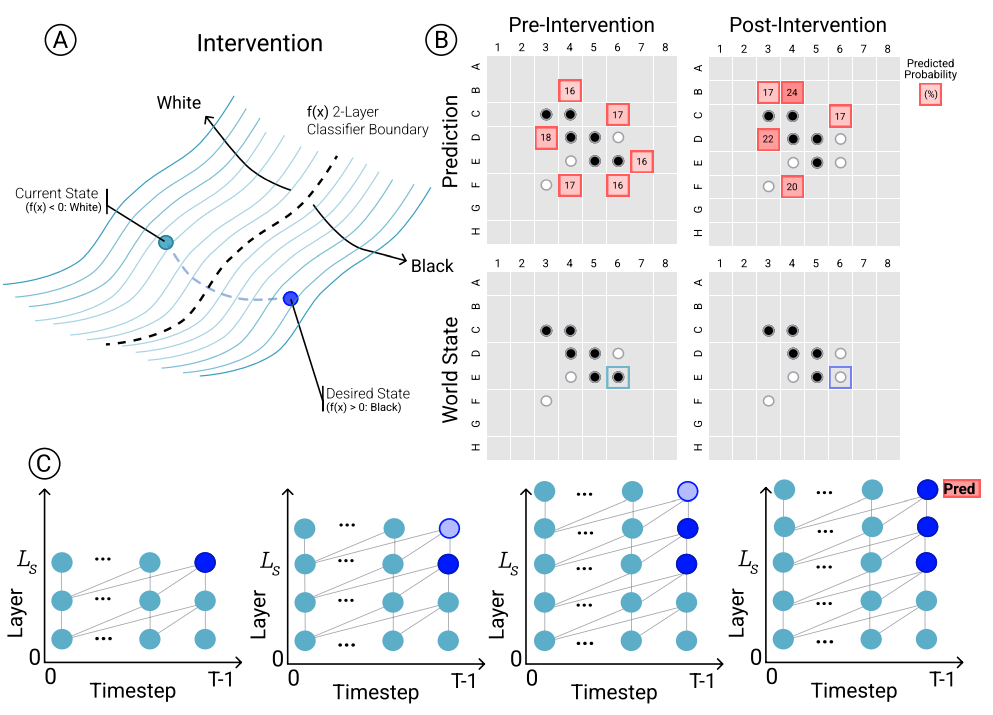
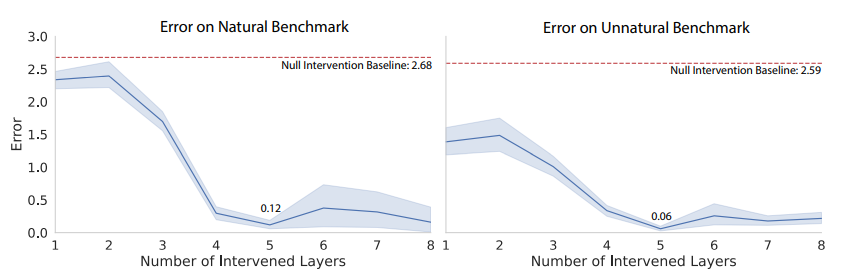
作者专门创建了一个因果评估测试集,其由两个子集构成,分别表示“自然”和“不自然”的测试样例,自然子集由合法落子位置组成,而不自然子集中包含了非法的落子位置,总样本量为1000。随后将每组测试样例交给Othello-GPT,并进行上述的干预操作,在计算过程中提取模型的激活值,对其进行修改,将目标棋子的表征改为目标状态,并将修改后的棋盘世界表征重新送入模型,让模型用这个新的世界状态进行预测。随后将模型原本预测与干预后的预测之间的一致性作为一个多标签分类问题进行评估,对于两个子集,模型在干预 L_s=4 时得到了最好的结果,平均误差分别为0.12和0.06,与基线误差(2.68和2.59)相比,如下图所示,本文的因果干预技术起到了明显的作用,这表明Othello-GPT的内部表征对模型预测有因果关系。
 使用嵌入显著性图进行可视化
使用嵌入显著性图进行可视化
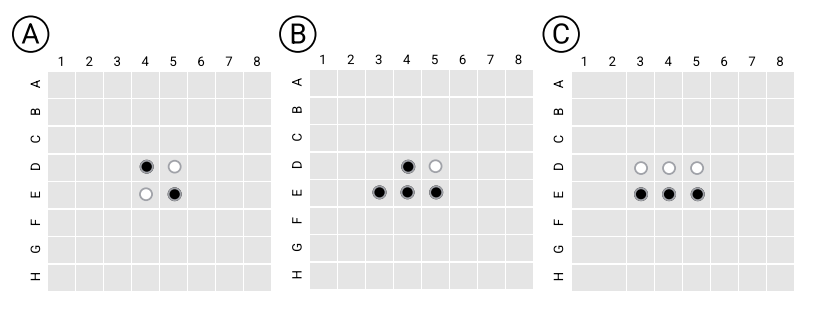
作者随后进行了可视化实验,即将Othello-GPT的预测与棋盘状态结合起来,对于棋盘上的每个棋子,使用上一节介绍的干预技术来改变该棋子的状态表示,并且记录网络对当前棋子的预测概率变化值,然后创建一个棋盘可视化图,根据变化显着性对相应位置进行着色,就生成了显著性图,因为这个图的构成是基于网络的嵌入空间,因此作者称它为嵌入显著性图。
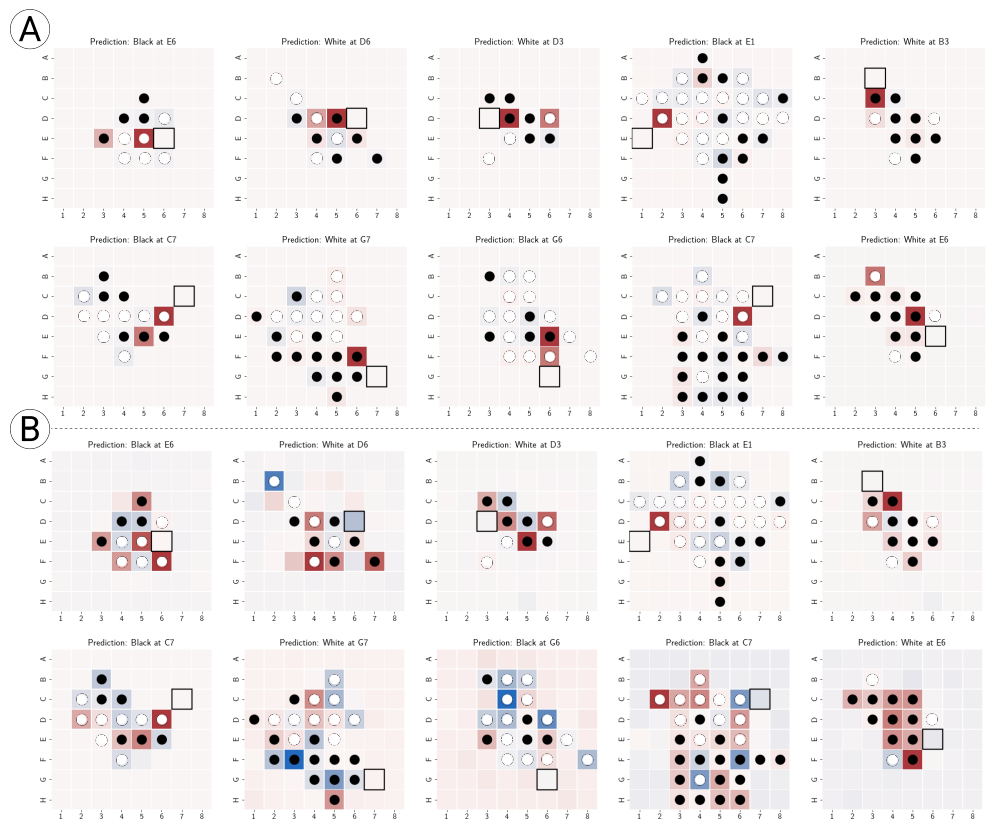
上图分别展示了在synthetic(图A)和championship(图B)数据集上训练的Othello-GPT的top-1预测的嵌入显著性图。可以观察到,在合成数据集synthetic上训练的Othello-GPT对那些合法移动的棋子表现出了高度的显著性。然而,在championship上训练Othello-GPT具有更复杂的嵌入显著性图。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢