
【标题】Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
【作者团队】Chao Yu, Xinyi Yang, Jiaxuan Gao
【发表日期】2023.1.9
【论文链接】https://arxiv.org/pdf/2301.03398.pdf
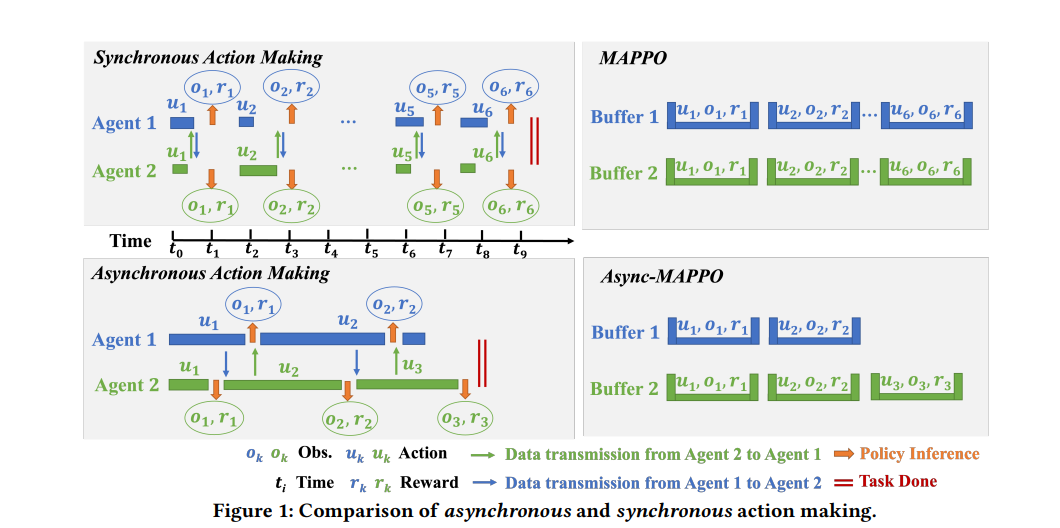
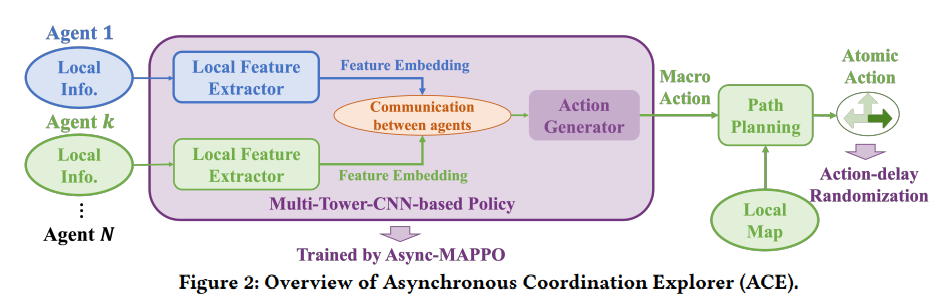
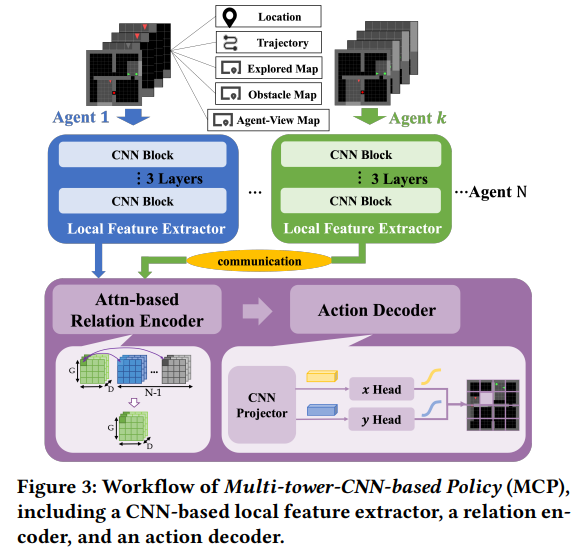
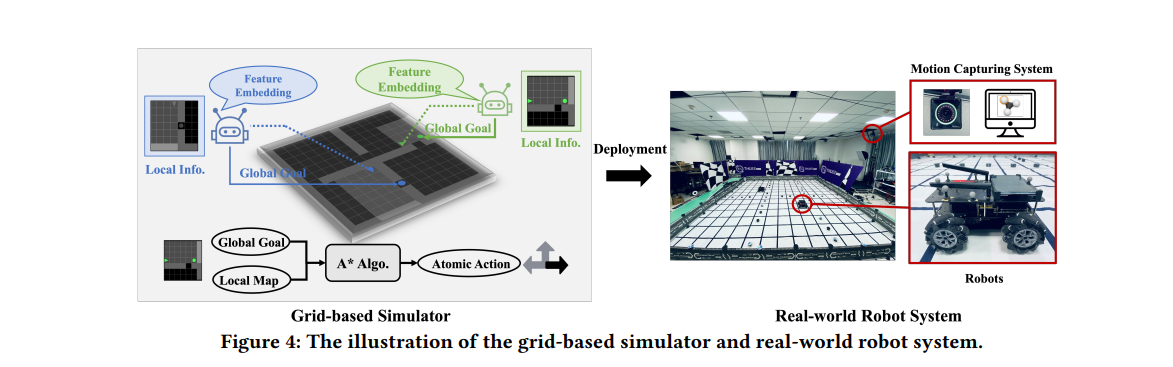
【推荐理由】多智能体强化学习 (MARL) 最近已成为解决多个机器人合作探索问题的趋势范例。 然而,现有的基于 MARL 的方法采用动作制定步骤作为探索效率的指标,假设所有智能体都以完全同步的方式行动。 尽管数学上很简单,但现实世界的通常情况下,不同的机器人可能会花费略微不同的时间来完成原子操作,甚至会由于硬件问题而周期性地迷路。本文提出了一种异步 MARL 解决方案,即异步协调资源管理器 (ACE),以应对这一现实世界的挑战。 作者首先将经典的 MARL 算法、多智能体 PPO (MAPPO) 扩展到异步设置,并另外应用动作延迟随机化来强制执行学习的策略,以更好地泛化到现实世界中不同的动作延迟。 此外,每个导航智能体都表示为团队规模不变的基于 CNN 的策略,这通过处理可能的机器人丢失极大地有利于实际机器人部署,并允许通过低维 CNN 功能进行带宽高效的智能体内通信。仿真和真实机器人结果均表明,与经典方法相比,ACE 减少了超过 10% 的实际探索时间。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢