强化学习(RL)为顺序决策提供了一种数学形式,深度强化学习(DRL)近年来也取得巨大进展。然而,样本效率问题阻碍了在现实世界中广泛应用深度强化学习方法。为了解决这个问题,一种有效的机制是在 DRL 框架中引入归纳偏置。
在深度强化学习中,函数逼近器是非常重要的。然而,与监督学习(SL)中的架构设计相比,DRL 中的架构设计问题仍然很少被研究。大多数关于 RL 架构的现有工作都是由监督学习 / 半监督学习社区推动的。
例如,在 DRL 中处理基于高维图像的输入,常见的做法是引入卷积神经网络(CNN)[LeCun et al., 1998; Mnih et al., 2015];处理部分可观测性(partial observability)图像的常见做法则是引入递归神经网络(RNN) [Hochreiter and Schmidhuber, 1997; Hausknecht and Stone, 2015]。
近年来,Transformer 架构 [Vaswani et al., 2017] 展现出优于 CNN 和 RNN 的性能,成为越来越多 SL 任务中的学习范式 [Devlin et al., 2018; Dosovitskiy et al., 2020; Dong et al., 2018]。Transformer 架构支持对长程(long-range)依赖关系进行建模,并具有优异的可扩展性 [Khan et al., 2022]。受 SL 成功的启发,人们对将 Transformer 应用于强化学习产生了浓厚的兴趣,希望将 Transformer 的优势应用于 RL 领域。
Transformer 在 RL 中的使用可以追溯到 Zambaldi 等人 2018 年的一项研究,其中自注意力(self-attention)机制被用于结构化状态表征的关系推理。随后,许多研究人员寻求将自注意力应用于表征学习,以提取实体之间的关系,从而更好地进行策略学习 [Vinyals et al., 2019; Baker et al., 2019]。
除了利用 Transformer 进行表征学习,之前的工作还使用 Transformer 捕获多时序依赖,以处理部分可观测性问题 [Parisotto et al., 2020; Parisotto and Salakhutdinov, 2021]。离线 RL [Levine et al., 2020] 因其使用离线大规模数据集的能力而受到关注。受离线 RL 的启发,最近的研究表明,Transformer 结构可以直接作为顺序决策的模型 [Chen et al., 2021; Janner et al., 2021] ,并推广到多个任务和领域 [Lee et al., 2022; Carroll et al., 2022]。
实际上,在强化学习中使用 Transformer 做函数逼近器面临一些特殊的挑战,包括:
-
强化学习智能体(agent)的训练数据通常是当前策略的函数,这在学习 Transformer 的时候会导致不平稳性(non-stationarity);
-
现有的 RL 算法通常对训练过程中的设计选择高度敏感,包括模型架构和模型容量 [Henderson et al., 2018];
-
基于 Transformer 的架构经常受制于高性能计算和内存成本,这使得 RL 学习过程中的训练和推理都很昂贵。
例如,在用于视频游戏的 AI 中,样本生成的效率(在很大程度上影响训练性能)取决于 RL 策略网络和估值网络(value network)的计算成本 [Ye et al., 2020a; Berner et al., 2019]。
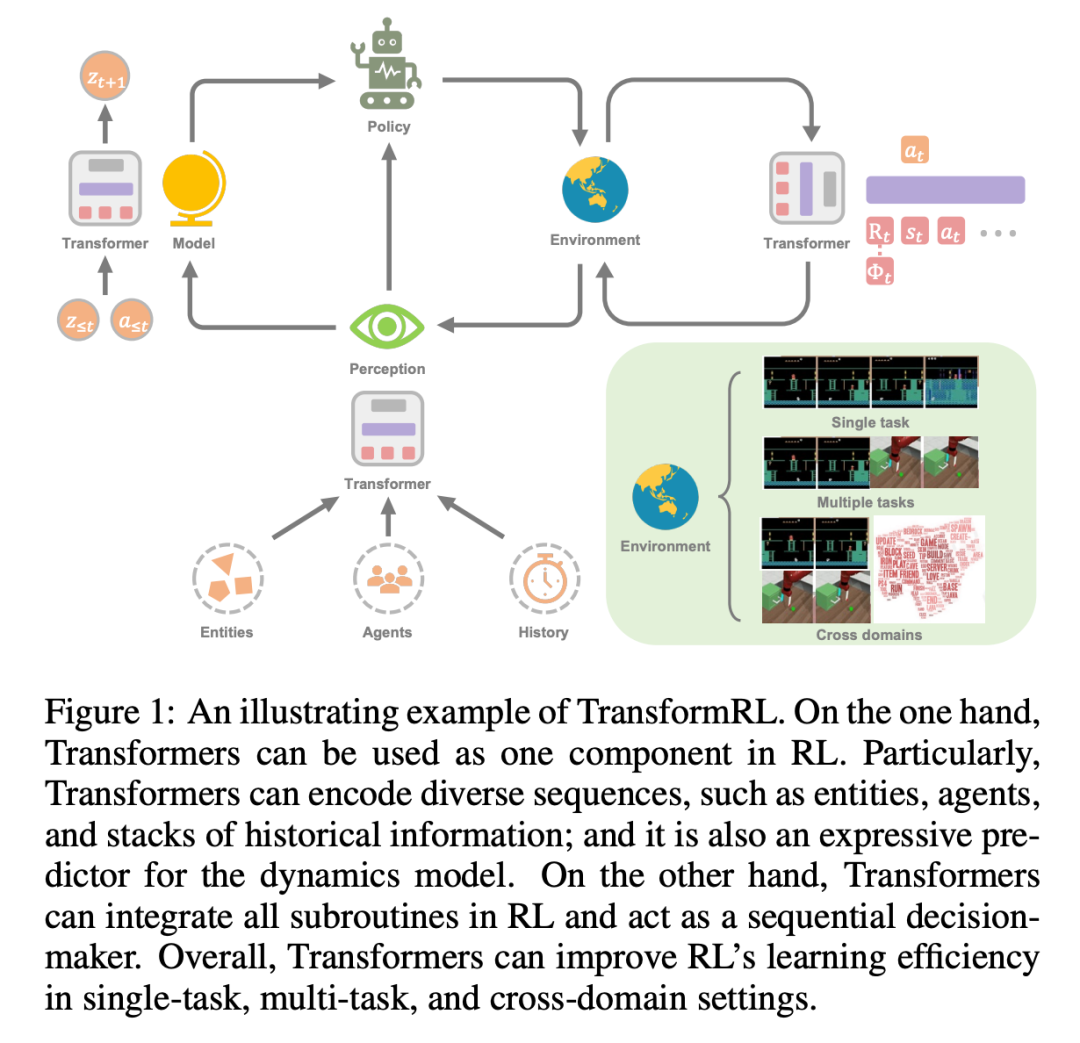
为了更好地推动强化学习领域发展,来自清华大学、北京大学、智源人工智能研究院和腾讯公司的研究者联合发表了一篇关于强化学习中 Transformer(即 TransformRL)的综述论文,归纳总结了当前的已有方法和面临的挑战,并讨论了未来的发展方向,作者认为 TransformRL 将在激发强化学习潜力方面发挥重要作用。
论文标题:
A Survey on Transformers in Reinforcement Learning
https://arxiv.org/pdf/2301.03044.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢