


论文题目:Domain Adaptation with Adversarial Training on Penultimate Activations
论文链接:https://arxiv.org/pdf/2208.12853.pdf
代码链接:https://github.com/tsun/APA
导读
增强未标记目标域数据的模型预测置信度是无监督域自适应(UDA) 的一个重要目标。在本文中,作者探讨了末层激活(即最后一层线性分类层输入特征)的对抗训练。文章表明,与先前工作中使用的对输入图像或中间特征作对抗训练相比,该策略更有效,并且与提高预测置信度的目标相关性更强。此外,当模型存在激活归一化时,作者提出了两个方法变种,并系统地分析了归一化对方法中对抗训练的影响。这在理论上和实际域自适应任务的实验中都得到了印证。作者考虑了标准设置和无源域数据设置,在常用的UDA数据集上进行了广泛的实验,验证了文中方法的有效性。
背景
虚拟对抗学习(VAT)在未标记数据上作对抗训练,常用于增强半监督学习中模型局部光滑性,其目标是:
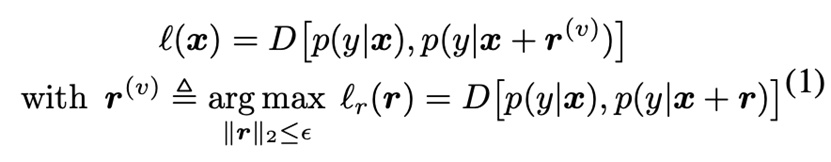
其中 是Kullback-Leibler散度。令上划线表示L2归一化,则 \( r^{(v)} \) 可通过下式近似得到:
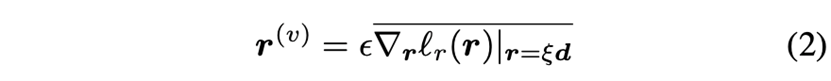
这里的扰动是“虚拟”对抗的,因为它不是通过真实标签得到的。
在域自适应中,虚拟对抗训练(VAT)常被引入以提高模型的局部平滑性,其主要思想是迫使模型在原始的和受扰动的图像上得到相近的预测结果。尽管如此,VAT通常只用作一个辅助损失函数,单独使用VAT无法获得理想的性能。同时,VAT为了获取梯度方向需要对整个网络进行一次额外的反向传播,这增加了计算成本。
这些观察启发了作者寻求更有效的对抗训练方式用于解决UDA问题。在UDA中,训练过程常被划分为源域训练和目标域适应两个阶段。作者发现,由于两个域相关,在第二阶段线性分类层变化缓慢。因为主要目标是增强未标记目标域数据的模型预测置信度,作者提出在末层激活上作对抗训练,这相比于在其他层作对抗训练与上述目标关联更强。针对UDA中经常对激活做L2归一化以减少域间隔,作者提出了两个方法变种,并系统分析了归一化对方法中对抗训练的影响,探讨了对抗损失函数相应梯度的“收缩效应”。文中还分析了对抗扰动、激活相应梯度和实际激活变化量三者在域适应任务中的相关性。
本文的贡献包括:
-
提出了一个基于末层激活作对抗训练的UDA框架;
-
系统地分析了它与先前在输入图像或中间特征上作对抗性训练的关联和优势;
-
通过广泛实验验证了文中方法在标准设置和无源数据设置下的优越性能。
方法
两阶段训练流程:与之前的工作一致,文中将训练过程分为源域训练阶段和目标域适应阶段。在第一阶段,模型仅在源域数据上利用标准交叉熵进行训练;在第二阶段,使用目标域数据(以及可用的源域数据)将获得的源域模型适配到目标域。本文工作旨在第二阶段利用对抗训练增强未标记目标域样本的预测置信度。

图1: 本文方法框架。 \( \text{APA}^u \) 和 \( \text{APA}^n \) 分别对归一化前和归一化后的激活作对抗训练。
方法动机: 由于分类器先用源域数据作初始化,且目标域和源域相关,作者首先探讨了域适应阶段分类器权重的变化情况。图2绘制了Office Home 12项任务上分类器初始权重 \( W^{(0)} \) 和训练过程中权重 之间的平均余弦相似度。这表明权重变化相当缓慢。因此,在较短训练周期内忽略决策边界变化是合理的。有一些工作在域适应过程中冻结了分类器,作者没有选择这么做,但发现冻结分类器对性能影响不大(参见表7)。
为了提高未标记目标域数据的预测置信度,一种自然的方法是将其末层激活从决策边界移开,这可以通过对抗训练实现。对输入图像或中间特征作对抗训练也可以间接地更新末层激活,但其有效性会降低,文中在方法分析部分对此进行了详细讨论。
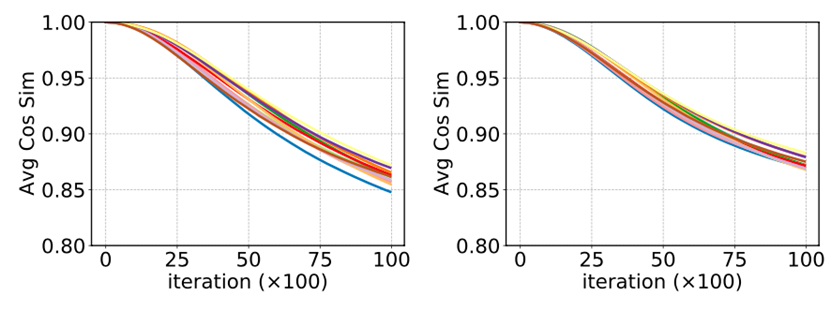
图2: 在(左)标准设置和(右)无源域数据设置下,Office Home 12项任务上初始分类器权重\( W^{(0)} \) 和训练过程中权重 之间的平均余弦相似度。
方法细节:作者对末层激活作对抗训练,以提高域适应阶段目标域数据的预测置信度,目标函数是:
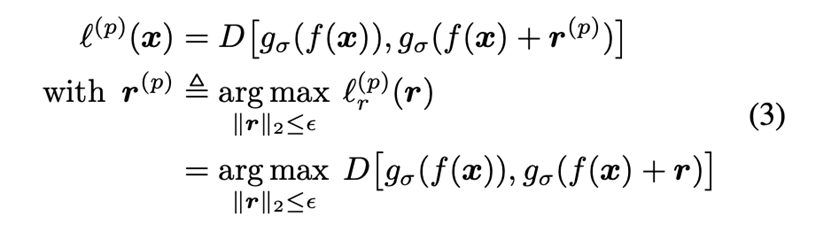
该方法可以很容易地扩展到无源域数据设置。由于源域样本在域适应阶段无法获得,作者使用置信的目标域样本伪标签作为额外的监督项,其目标函数变成:
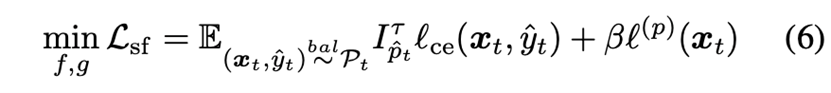
存在激活归一化时的方法变种:在末层激活上使用L2归一化是一种常用的减少域间隔的技巧。如图1所示,文中方法相应地存在两种变体,\( \text{APA}^u \) 和 \( \text{APA}^n \) ,分别对应着对归一化之前和归一化之后的激活作对抗训练。
\( \text{APF}^u \) 的对抗损失函数是:
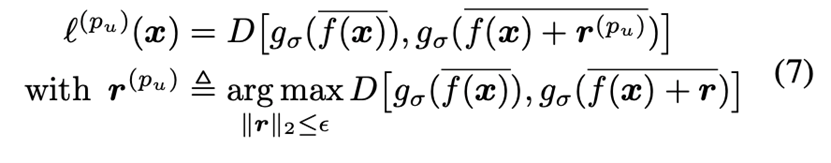
\( \text{APF}^n \) 的对抗损失函数是:
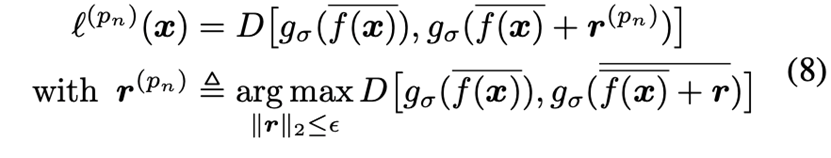
对于后者,作者额外做了一步“扰动投影”,以确保 \( \overline{f({x})}+{r}^{\left(p_{n}\right)} \) 位于单位球上:
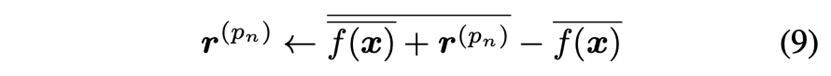
实验
激活归一化的效果:如图7所示,使用激活归一化可以一致地提升所有任务上的性能。当域间隔较大时(例如精度较低的任务),性能增益最显著。这验证了激活归一化可以使源域和目标域数据分布更接近,从而减少自训练中累积误差的影响。
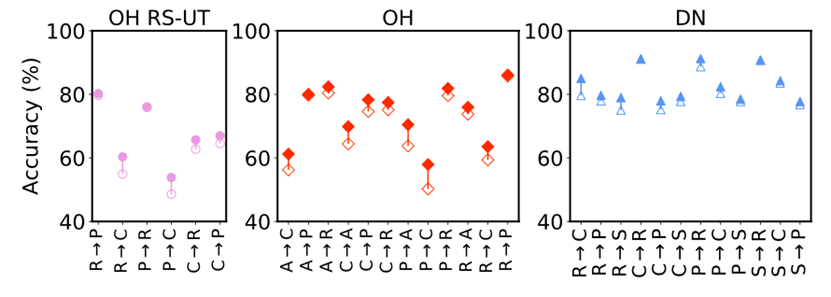
图3:使用激活归一化(实心标记)和不使用归一化(空心标记)的比较。
与其他自训练损失函数的比较:为了公平对比,作者在和APA相同的框架和超参数下进行实验,结果列于表6。其中,FixMatch和SENTRY需要额外的随机目标域样本数据增强。文中的方法在所有数据集上都获得了最佳分数。
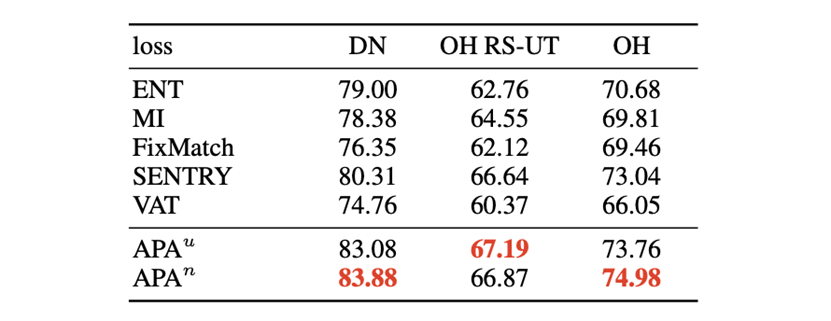
表1:与其他自训练损失函数的比较。
冻结分类器的效果:在之前的实验中,作者允许分类器的参数在自适应阶段进行更新。尽管如此,特征空间中的分类器和相应的决策边界变化通常可忽略。之前的一些工作在自适应阶段选择冻结分类器,表7显示这两种策略在文中的方法中表现相当。

表2: 冻结分类器的效果。
超参数的灵敏性:APA主要涉及两个超参数,扰动大小 和对抗损失函数权重 。注意到归一化前末层激活的平均范数约为30。图6中特意给出了相对大扰动下的结果以显示方法鲁棒性。图8表明本文方法对 不敏感。
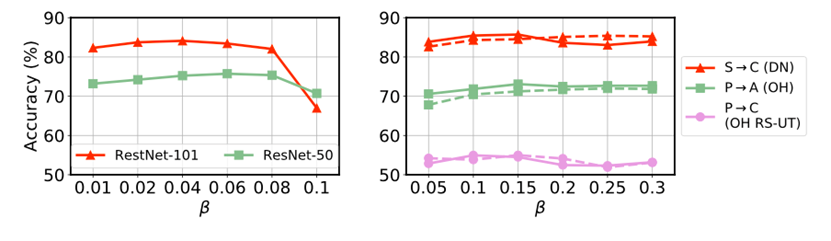
图4: \( \text{APA}^n \) (实线)和 \( \text{APA}^u \)(虚线)中对抗损失函数权重 的敏感性。
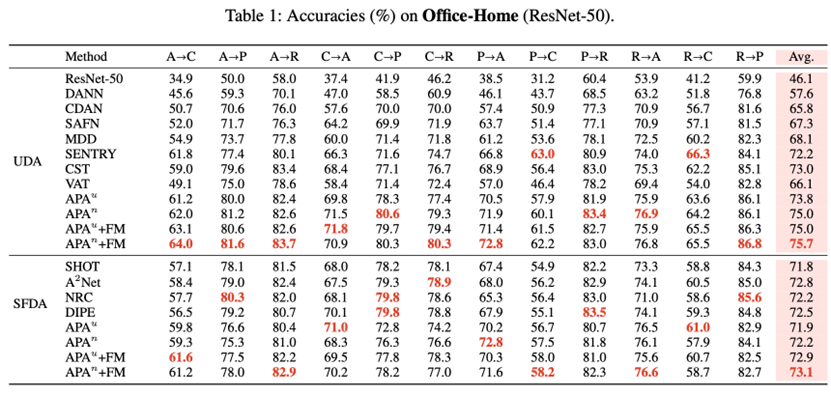
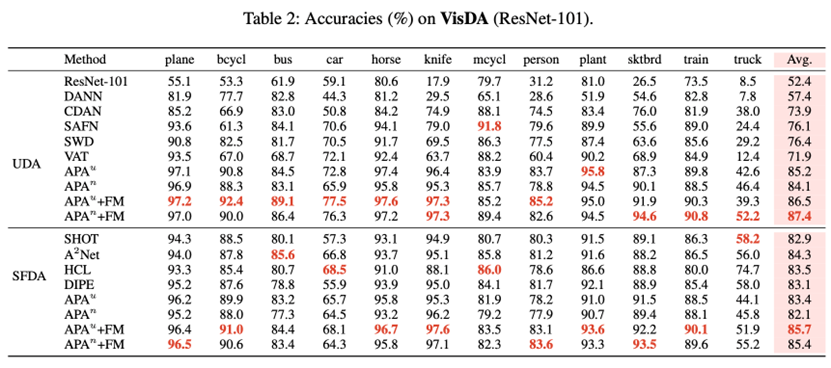
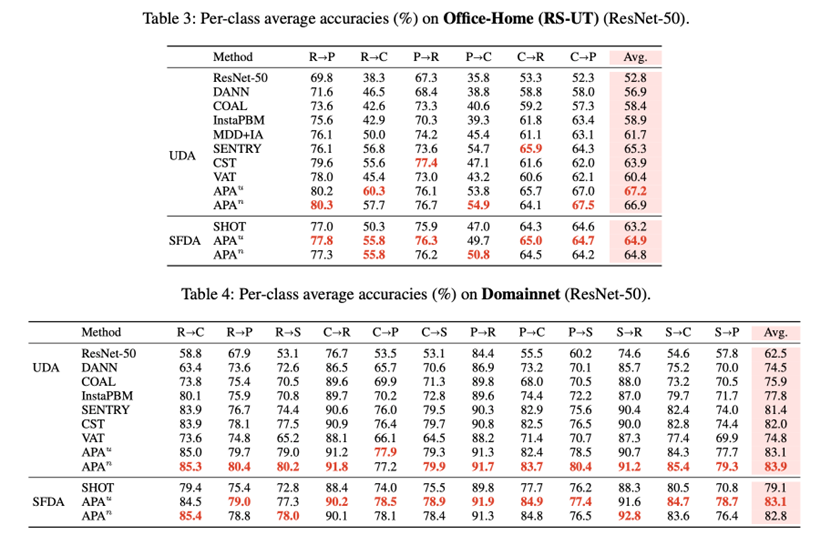
作者使用Office-Home, VisDA-2017,DomainNet等常用UDA数据集,对比标准UDA方法、针对标记分布不一致场景的域适应方法以及无源域数据的域适应方法。文中还对比了熵最小化、互信息最大化(MI)、VAT和FixMatch(FM)等常用的自训练损失函数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢