
CFG Labs 从两年前就开始关注并且大量投资GAI 板块,并且将在未来继续助力行业的发展。本文作者Frank 为AI,机器学习,神经网络领域专家,无论在学术以及工作经验方面都获得了惊人的成绩和经验。
在过去十年中,机器学习软件开发的格局经历了重大变化。许多框架层出不穷,但大多数框架都严重依赖利用Nvidia的CUDA,并在Nvidia GPU上表现最佳。然而,随着PyTorch 2.0和OpenAI的Triton的到来,Nvidia在该领域的主导地位(主要是由于其软件护城河)正在被打破。
本报告将触及的主题包括:为什么谷歌的TensorFlow输给了PyTorch,为什么谷歌未能公开利用其在人工智能领域的早期领先地位,机器学习模型训练时间的主要组成部分,内存容量/带宽/成本墙,模型优化。为什么其他人工智能硬件公司到目前为止还不能在Nvidia的主导地位上有所作为,为什么硬件将开始变得更加重要,Nvidia在CUDA上的竞争优势是如何被抹去的,以及Nvidia的一个竞争对手在训练芯片的大型云上的重大胜利。
1,000英尺的总结是,机器学习模型的默认软件栈将不再是Nvidia的闭源CUDA。游戏比赛在Nvidia的法庭上,他们让OpenAI和Meta控制了软件栈。由于Nvidia专有工具的失败,该生态系统建立了自己的工具,现在Nvidia的护城河将被永久地削弱了。

TensorFlow vs. PyTorch
几年前,框架生态系统是相当分散的,但TensorFlow是领先者。谷歌看起来已经准备好控制机器学习行业了。他们拥有最常用的框架TensorFlow,并设计/部署了唯一成功的人工智能特定应用加速器TPU,从而拥有了先发优势。
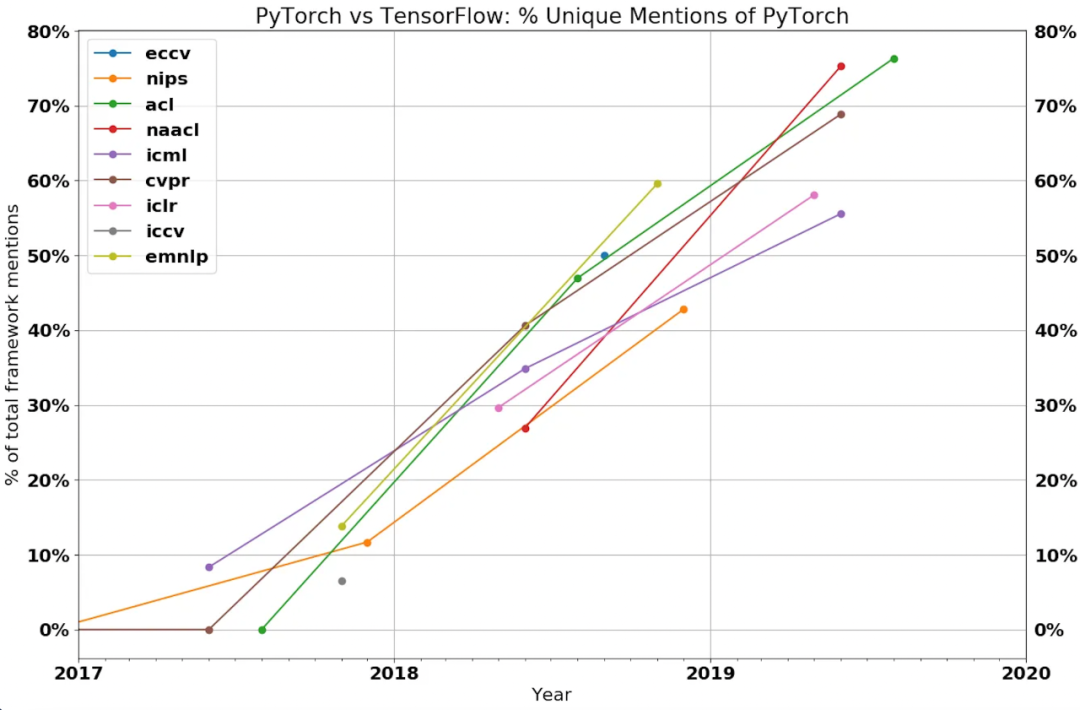
相反,PyTorch赢了。谷歌未能将其先发优势转化为对新生的ML行业的主导地位。如今,谷歌在机器学习界有些孤立,因为它没有使用PyTorch和GPU,而是使用自己的软件栈和硬件。在典型的谷歌风格中,他们甚至有一个名为Jax的第二框架,直接与TensorFlow竞争。
甚至还有人在无休止地谈论谷歌在搜索和自然语言处理方面的主导地位因大型语言模型而减弱,特别是那些来自OpenAI和各种利用OpenAI API或正在建立类似基础模型的初创公司。虽然我们认为这种厄运和忧郁被夸大了,但这是另一个故事了。尽管有这些挑战,谷歌仍然处于最先进的机器学习模型的前沿。他们发明了Transformer,并在许多领域保持最先进的水平(PaLM、LaMBDA、Chinchilla、MUM、TPU)。
回到PyTorch获胜的原因。虽然有从谷歌手中夺取控制权的因素,但主要是由于PyTorch相对于TensorFlow的灵活性和实用性的提高。如果我们把它归结为第一个主要层面,PyTorch与TensorFlow的不同之处在于使用了 "Eager模式 "而不是 "图形模式"。
Eager模式可以被认为是一种标准的脚本执行方法。深度学习框架立即执行每个操作,当它被调用时,逐行执行,就像任何其他的Python代码。这使得调试和理解你的代码更加容易,因为你可以看到中间操作的结果,看到你的模型是如何表现的。
相比之下,图模式有两个阶段。第一阶段是定义一个代表要执行的操作的计算图。计算图是一系列相互连接的节点,代表操作或变量,而节点之间的边代表它们之间的数据流。第二阶段是延迟执行计算图的优化版本。
这种两阶段的方法使得理解和调试你的代码更具挑战性,因为在图的执行结束之前,你无法看到正在发生什么。这类似于 "解释的 "与 "编译的 "语言,如Python与C++。调试Python比较容易,主要是因为它是解释的。
虽然TensorFlow现在默认有Eager模式,但研究界和大多数大型科技公司已经围绕着PyTorch解决。几乎所有上了新闻的生成性人工智能模型都是基于PyTorch的,这就是一个例子。谷歌的生成式人工智能模型是基于Jax的,而不是TensorFlow。
当然,还有一长串使用TensorFlow和Keras等其他框架的图像网络,但新模型开发的计算预算都流向了PyTorch模型。关于PyTorch获胜的更深层次的解释,请看这里。一般来说,如果你在NeurIPS(主要的人工智能会议)的大厅里走动,所有生成性人工智能,非谷歌的工作都是用PyTorch。
机器学习训练组件
如果我们把机器学习模型的训练归结为最简单的形式,那么在机器学习模型的训练时间中,有两个主要的时间组成部分。
-
计算(FLOPS)。在每层内运行密集的矩阵乘法
-
内存(带宽)。等待数据或层权重到达计算资源。受带宽限制的操作的常见例子是各种归一化、点式操作、SoftMax和ReLU。
在过去,机器学习训练时间的主导因素是计算时间,等待矩阵乘法。随着Nvidia的GPU不断发展,这很快就不再是首要关注的问题了。通过利用摩尔定律,Nvidia的FLOPS增加了多个数量级,但主要是架构上的变化,如张量核心和低精度浮点格式。相比之下,内存没有遵循同样的路径。
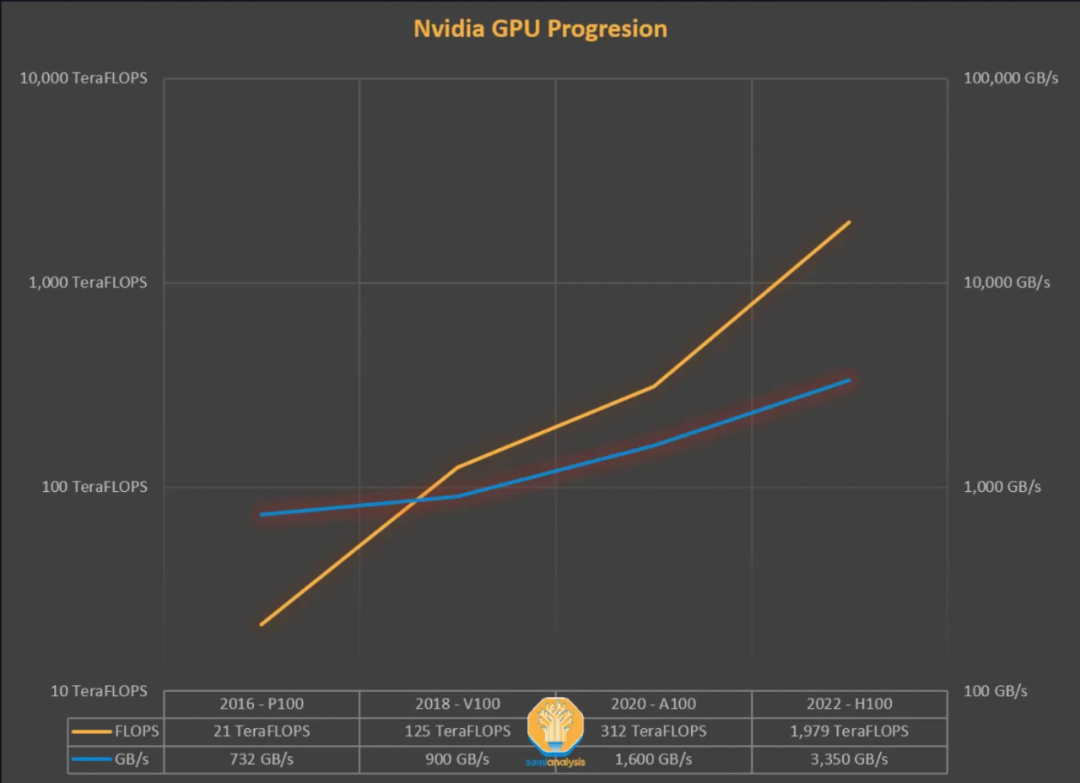
如果我们回到2018年,当BERT模型是最先进的,而Nvidia V100是最先进的GPU时,我们可以看到,矩阵乘法不再是提高模型性能的主要因素。从那时起,最先进的模型在参数数量上增长了3到4个数量级,而最快的GPU在FLOPS上也增长了一个数量级。
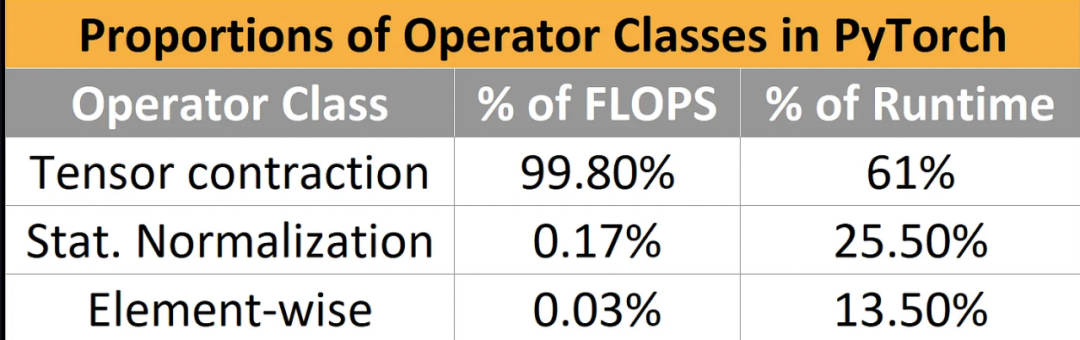
https://arxiv.org/pdf/2007.00072.pdf
即使在2018年,纯粹的计算型工作负载占了99.8%的FLOPS,但只占运行时间的61%。与矩阵乘法相比,归一化和点化操作分别实现了250倍的FLOPS和700倍的FLOPS,但它们却消耗了该模型近40%的运行时间。
内存墙
随着模型规模的不断扩大,大型语言模型仅在模型权重方面就需要几十亿字节,甚至上百万亿字节。由百度和Meta部署的生产型推荐网络需要几十TB的内存,用于其大规模的嵌入表。\在大型模型训练/推理中,很大一部分时间不是用来计算矩阵乘法,而是等待数据到达计算资源。一个明显的问题是,为什么架构师不把更多的内存放在靠近计算的地方。答案是$$$。
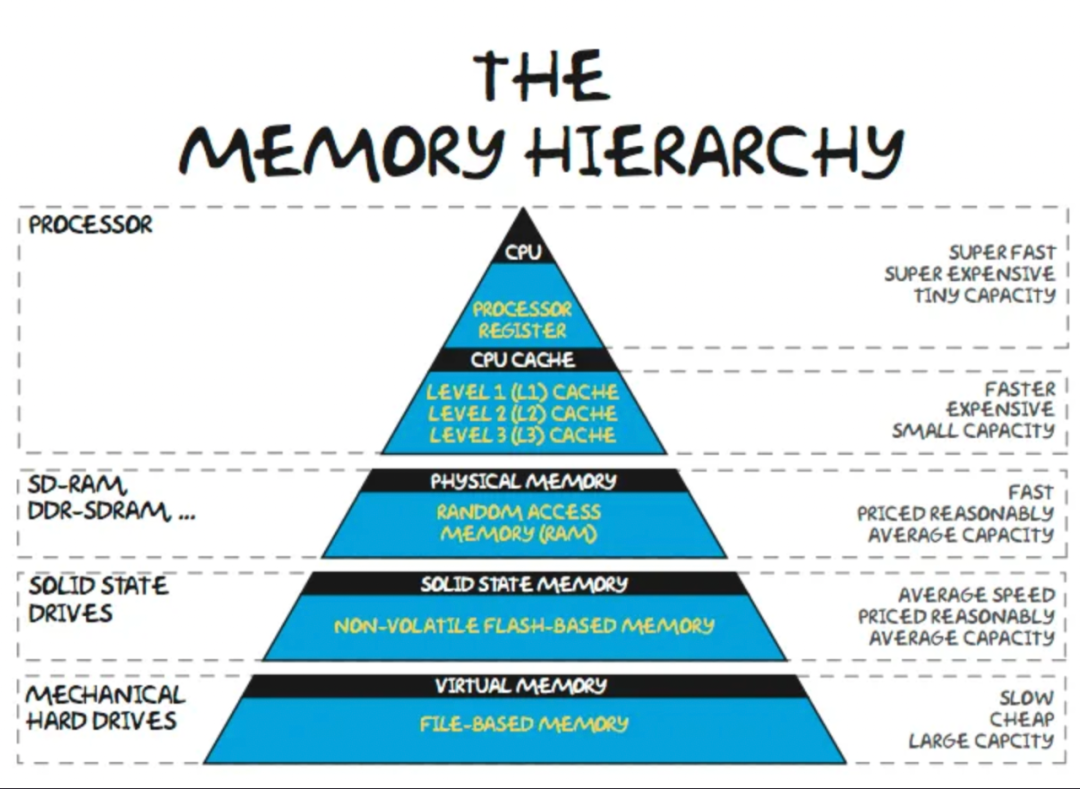
内存遵循一个从近而快到慢而便宜的层次结构。最近的共享内存池在同一个芯片上,一般由SRAM组成。一些机器学习ASIC试图利用巨大的SRAM池来保存模型权重,但这种方法存在一些问题。即使是Cerebras的~250万美元的晶圆规模的芯片也只有40GB的SRAM在芯片上。没有足够的内存容量来容纳100B以上参数模型的权重。
Nvidia的架构一直在芯片上使用小得多的内存。当前一代A100有40MB,下一代H100有50MB。在台积电的5纳米工艺节点上,1GB的SRAM需要大约200mm^2的硅。一旦实现了相关的控制逻辑/结构,这将需要超过400mm^2的硅,或约为Nvidia数据中心GPU总逻辑面积的50%。鉴于A100 GPU的价格为1万多美元,H100的价格为2万多美元,从经济上讲,这是不可行的。即使你忽略了Nvidia在数据中心GPU上约75%的毛利率(约4倍的加价),每GB的SRAM内存的成本仍将在100美元左右,而这是一个完全产出的产品。
此外,片上SRAM存储器的成本不会因为传统的摩尔定律工艺技术的缩减而降低多少。同样的1GB内存在下一代台积电3纳米工艺技术下实际上成本更高。虽然3D SRAM将在一定程度上帮助解决SRAM成本问题,但这只是一个暂时的曲线弯曲。
台积电的3纳米难题,它甚至有意义吗?- N3和N3E工艺技术和成本详解
存储器层次结构的下一步是紧密耦合的片外存储器,即DRAM。DRAM的延迟比SRAM高一个数量级(~>100纳秒对~10纳秒),但它也便宜得多(1美元/GB对100美元/GB)。
几十年来,DRAM一直遵循摩尔定律的路线。当戈登-摩尔创造这个词的时候,英特尔的主要业务是DRAM。他关于晶体管的密度和成本的经济预测在2009年之前对DRAM来说通常是正确的。但自2012年以来,DRAM的成本几乎没有提高。
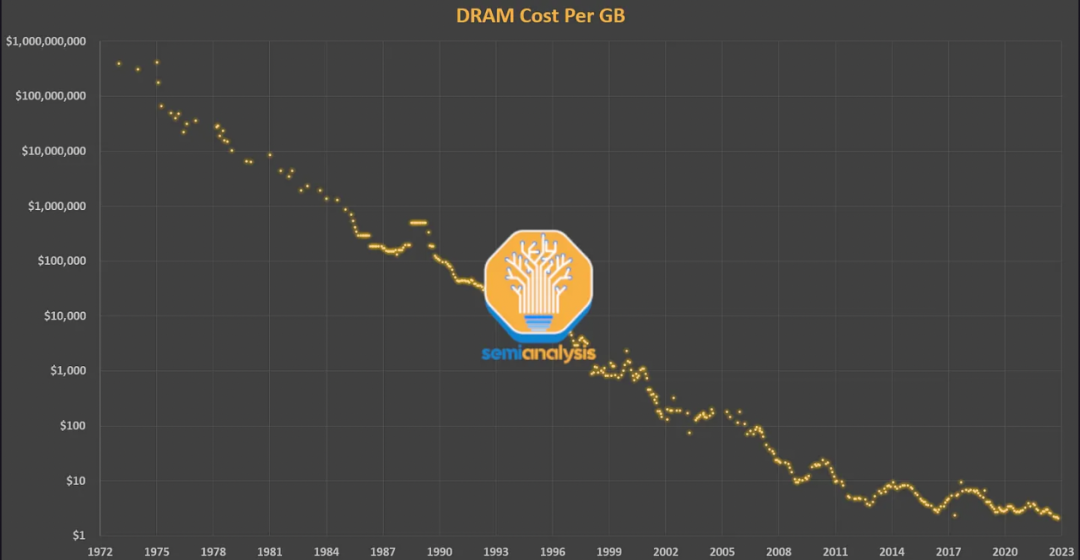
对内存的需求只增不减。DRAM现在占了服务器总成本的50%。这就是内存墙,它已经在产品中显现出来。将Nvidia 2016年的P100 GPU与刚刚开始出货的2022年的H100 GPU相比,内存容量增加了5倍(16GB -> 80GB),但FP16性能却增加了46倍(21.2 TFLOPS -> 989.5 TFLOPS)。
虽然容量是一个重要的瓶颈,但它与另一个主要瓶颈--带宽密切相关。增加内存带宽通常是通过并行化获得的。虽然现在标准的DRAM每GB只需几美元,但为了获得机器学习所需的巨大带宽,Nvidia使用了HBM内存,这是一种由3D堆叠的DRAM层组成的设备,需要更昂贵的包装。HBM的价格在每GB 10到20美元之间,包括包装和产量成本。
内存带宽和容量的成本限制在Nvidia的A100 GPU中不断显现出来。A100在没有进行大量优化的情况下,FLOPS的利用率往往非常低。FLOPS利用率衡量的是训练一个模型所需的总计算FLOPS与GPU在模型训练时间内可计算的理论FLOPS。
即使领先的研究人员进行了大量优化,60%的FLOPS利用率也被认为是大型语言模型训练的一个非常高的利用率。剩下的是时间开销,即等待另一个计算/内存的数据的空闲时间,或重新计算结果,正好减少内存瓶颈。
从当前一代A100到下一代H100,FLOPS增长了6倍多,但内存带宽只增长了1.65倍。这导致了许多人对H100的低利用率的担心。A100需要很多技巧来绕过内存墙,而H100则需要实现更多的技巧。
H100为Hopper带来了分布式共享内存和二级组播。这个想法是,不同的SM(认为是核心)可以直接写到另一个SM的SRAM(共享内存/L1缓存)。这有效地增加了缓存的大小,减少了DRAM读/写的所需带宽。未来的架构将依靠向内存发送更少的操作来减少内存墙的影响。应该注意的是,较大的模型倾向于实现更高的利用率,因为FLOPS的需求更多的是以指数形式/扩展,而内存带宽和容量的需求更多的是以线性形式扩展。
操作符融合--解决方法
就像训练ML模型一样,了解你所处的状态可以让你缩小优化的范围,这很重要。例如,如果你把所有的时间都花在了内存传输上(也就是说,你处于一个内存带宽受限的状态),那么增加GPU的FLOPS是没有用的。另一方面,如果你把所有的时间都花在执行大的chonky matmuls上(即计算约束制度),那么把你的模型逻辑改写成C++来减少开销也没有用。https://horace.io/brrr_intro.html
回到PyTorch获胜的原因,是Eager模式带来的灵活性和可用性的提高,但转到Eager模式并不全是阳光和彩虹。在Eager模式下执行时,每个操作都要从内存中读取、计算,然后在处理下一个操作之前发送到内存。如果不进行大量的优化,这将大大增加对内存带宽的需求。
因此,在Eager模式下执行的模型的主要优化方法之一被称为运算器融合。操作符融合,而不是把每个中间结果写到内存中,所以多个函数在一次计算中被计算,以尽量减少内存的读/写。操作符融合改善了操作符调度、内存带宽和内存大小的成本。
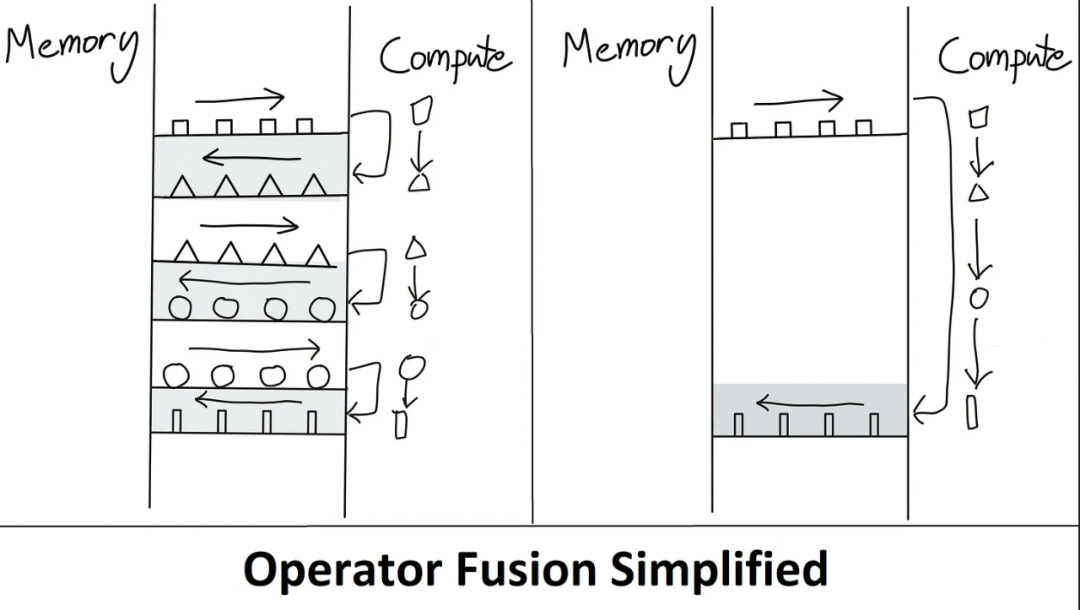
https://horace.io/brrr_intro.html
这种优化通常涉及到编写定制的CUDA内核,但这比使用简单的python脚本要困难得多。作为一种内在的妥协,随着时间的推移,PyTorch在其内部稳定地实现了越来越多的运算符。其中许多运算符只是将多个常用的操作融合到一个更复杂的函数中。
操作符的增加使得在PyTorch中创建模型变得更加容易,而且由于内存读写次数减少,Eager模型的执行速度也更快。缺点是,PyTorch在几年内就膨胀到了2000多个运算符。
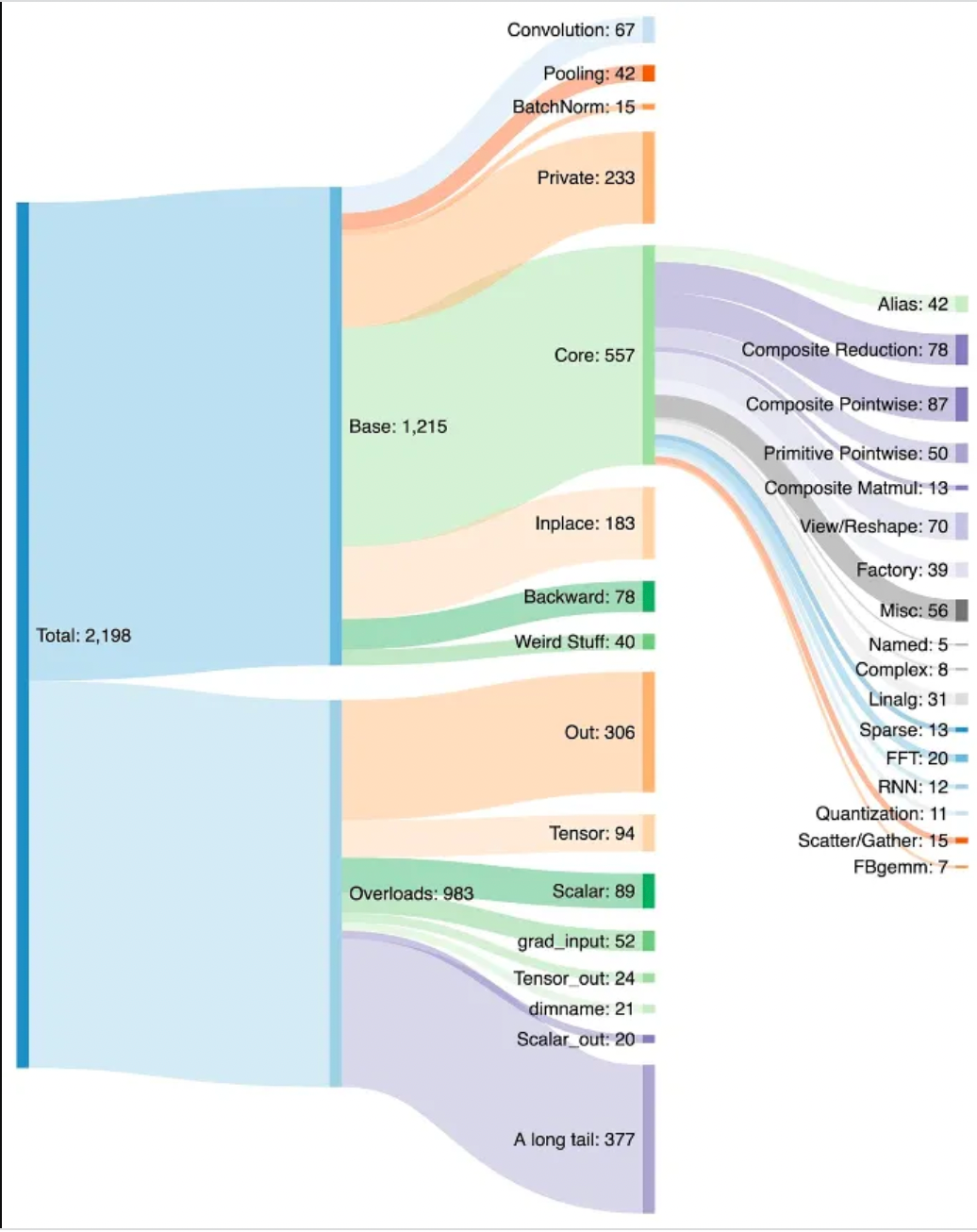
我们会说软件开发人员很懒,但说实话,几乎所有的人都很懒。如果他们习惯了PyTorch中的某个新运算符,他们就会继续使用该运算符。开发者甚至可能没有认识到性能的提高,而是使用那个运算符,因为这意味着写更少的代码。
此外,并不是所有的操作都能被融合。通常需要花费大量的时间来决定哪些操作需要融合,哪些操作需要分配给芯片和集群层面的特定计算资源。融合哪些操作的策略,虽然一般来说是相似的,但根据架构的不同,确实有很大的不同。
Nvidia是国王
运营商的增长和作为默认的地位帮助了Nvidia,因为每个运营商都很快为他们的架构进行了优化,但没有为任何其他硬件优化。如果一家人工智能硬件创业公司想要完全实现PyTorch,那就意味着要以高性能支持不断增长的2000个运算器的原生列表。
在GPU上训练一个高FLOPS利用率的大规模模型所需的人才水平越来越高,因为需要所有的技巧来提取最大的性能。Eager模式执行加上运算器融合意味着所开发的软件、技术和模型被推到了当前一代GPU所具有的计算和内存的比例范围内。
每个开发机器学习芯片的人都要面对同样的内存墙。ASICs必须支持最常用的框架。ASIC受制于默认的开发方法,GPU优化的PyTorch代码与Nvidia和外部库的混合。在这种情况下,放弃GPU的各种非计算包袱而选择更多的FLOPS和更严格的编程模型的架构是非常没有意义的。易用性是王道。
打破恶性循环的唯一方法是让在Nvidia GPU上运行模型的软件以尽可能少的努力无缝转移到其他硬件。随着模型架构的稳定和来自PyTorch 2.0、OpenAI Triton和MLOps公司(如MosaicML)的抽象成为默认,芯片解决方案的架构和经济性开始成为购买的最大驱动力,而不是Nvidia的卓越软件所提供的易用性。
PyTorch 2.0
几个月前,PyTorch基金会成立,并从Meta的羽翼下退出。在向开放式开发和管理模式转变的同时,2.0版本已经发布,用于早期测试,并在3月全面上市。PyTorch 2.0带来了许多变化,但最主要的区别是,它增加了一个支持图执行模型的编译解决方案。这一转变将使正确利用各种硬件资源变得更加容易。就在几个月前。伴随着这种向开放式开发和管理模式的转变,2.0已经发布,用于早期测试,并在3月全面上市。
PyTorch 2.0在Nvidia的A100上为训练带来了86%的性能提升,在CPU上为推理带来了26%的性能提升! 这极大地减少了训练模型所需的计算时间和成本。这些好处可以扩展到其他GPU和加速器上,从! 这极大地减少了训练一个模型所需的计算时间和成本。这些好处可以扩展到其他GPU和加速器,如AMD、英特尔、Tenstorrent、Luminous Computing、Luminous Computing、Tesla、谷歌、亚马逊、微软、Marvell、Meta、Graphcore、Cerebras、SambaNova等。
对于目前未优化的硬件,PyTorch 2.0的性能改进将更大。Meta和其他公司对PyTorch的大量贡献源于他们希望在他们由GPU组成的价值数十亿美元的训练集群上更容易实现更高的FLOPS利用率。他们也有动力使他们的软件堆栈更容易移植到其他硬件上,为机器学习领域引入竞争。
PyTorch 2.0还为分布式训练带来了进步,它对数据并行有更好的API支持,对数据并行、分片、管道并行和张量并行有更好的API支持。此外,它通过整个堆栈原生支持动态形状,在许多其他的例子中,这使得LLM的不同序列长度更容易得到支持。这是第一次有一个主要的编译器支持从训练到推理的动态形状。
PrimTorch
为PyTorch编写一个完全支持所有2000多个运算符的高性能后端,对于除Nvidia GPU之外的所有机器学习ASIC来说都是困难的。PrimTorch将运算符的数量降至约250个原始运算符,同时也为PyTorch的终端用户保持了可用性。PrimTorch使PyTorch的不同的、非Nvidia的后端实现得更简单和更容易。定制硬件和系统供应商可以更容易地提出他们的软件堆栈。
TorchDynamo
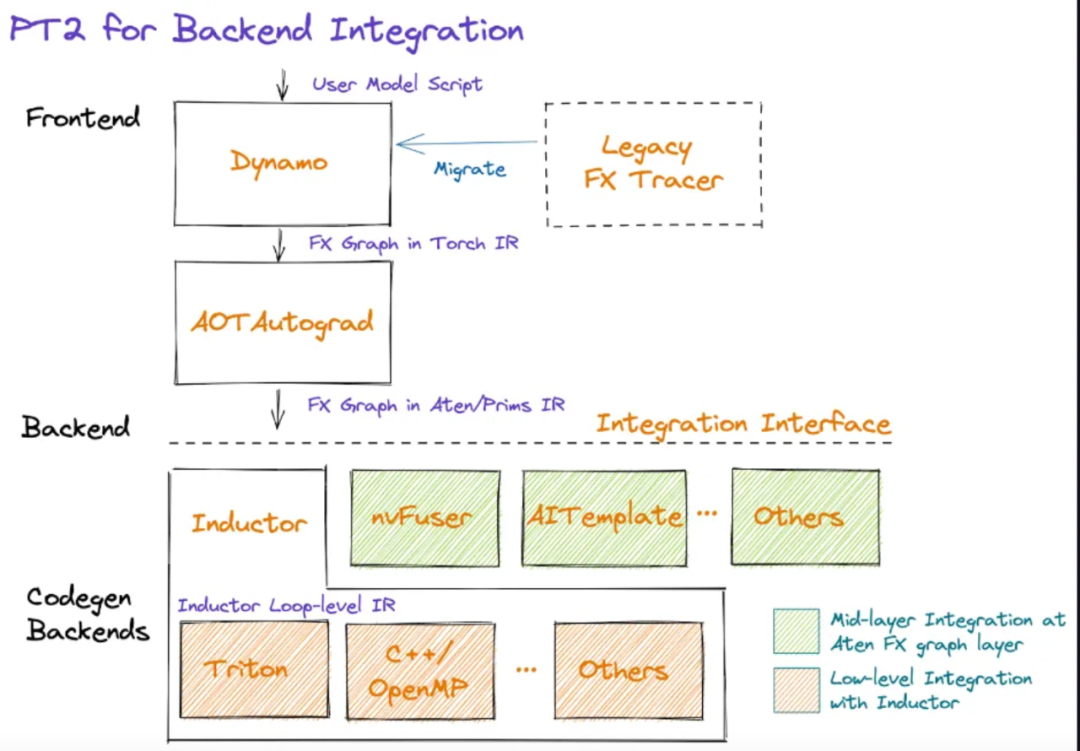
转向图形模式需要一个强大的图形定义。Meta和PyTorch在过去5年中一直试图实现这一目标,但他们提出的每个解决方案都有很大的缺陷。他们最终用TorchDynamo破解了这个难题。TorchDynamo将接收任何PyTorch用户脚本,包括那些调用外部第三方库的脚本,并生成一个FX图。
Dynamo将所有复杂的操作降低到PrimTorch的约250个原始操作。一旦图形成,未使用的操作就会被丢弃,图决定了哪些中间操作需要存储或写入内存,哪些有可能被融合。这极大地减少了模型内的开销,同时对用户来说也是无缝的。
在测试的7000个PyTorch模型中,TorchDynamo已经对超过99%的模型起作用,包括来自OpenAI、HuggingFace、Meta、Nvidia、Stability.AI等的模型,而无需对原始代码进行任何修改。测试的7000个模型是从GitHub上使用PyTorch的最受欢迎的项目中不加选择地挑选出来的。
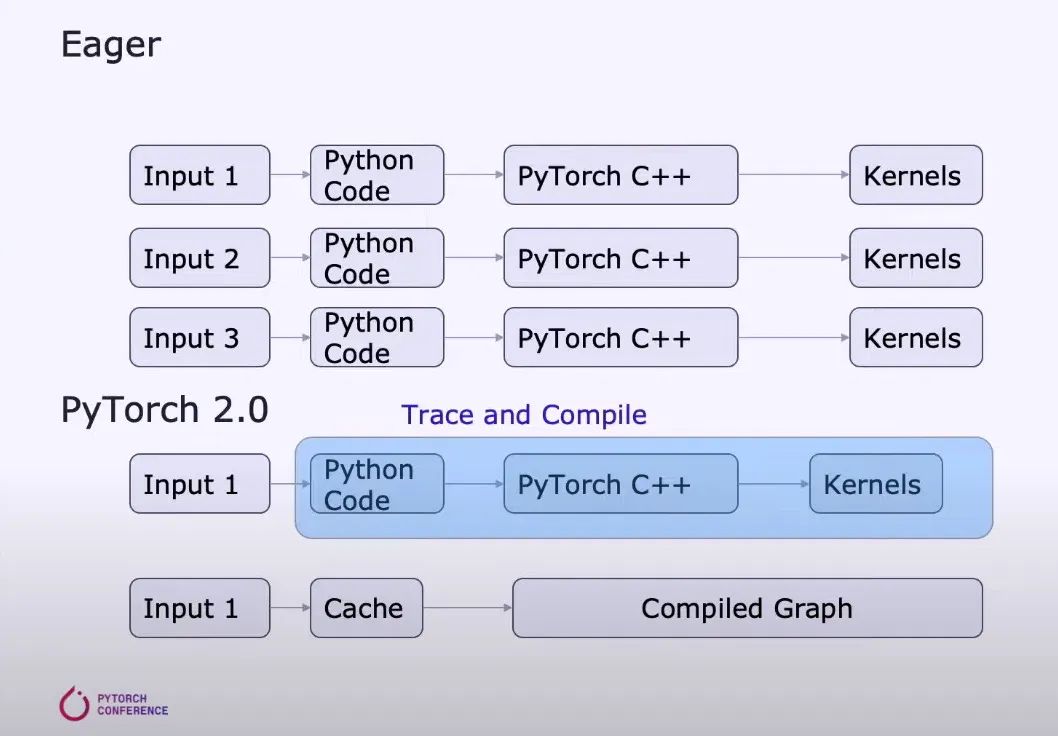
谷歌的TensorFlow/Jax和其他图形模式的执行管道通常要求用户确保他们的模型适合编译器的架构,以便可以捕获图形。谷歌的TensorFlow/Jax和其他图形模式的执行管道通常要求用户确保他们的模型适合编译器的架构,以便可以捕获图形,Dynamo通过启用部分图形捕获、受保护的图形捕获和及时重新捕获来改变这种情况。
部分图捕获允许模型包括不支持的/非python结构。当模型的那一部分不能生成图时,就会插入一个图断点,不支持的构造将在部分图之间以急切的模式执行。
守护的图形捕获检查捕获的图形是否有效,以便执行。守护是指需要重新编译的变化。这一点很重要,因为多次运行相同的代码不会多次重新编译。
Just-in-time recapture允许在捕获的图形无效的情况下重新捕获图形进行执行。
PyTorch的目标是创建一个统一的前端,具有流畅的用户体验,利用Dynamo来生成图形。这个解决方案的用户体验将保持不变,但性能可以得到显著提高。捕获图形意味着可以在大型计算资源基础上更有效地并行执行。
Dynamo和AOT Autograd然后将优化的FX图形传递给PyTorch本地编译器水平,TorchInductor。硬件公司也可以把这个图形输入到他们自己的后端编译器中。
TorchInductor
TorchInductor是一个python原生深度学习编译器,可以为多个加速器和后端生成快速代码。Inductor会把有大约250个运算符的FX图,降低到大约50个运算符。然后Inductor进入调度阶段,将运算符融合,并确定内存规划。
然后,Inductor进入 "封装代码 "阶段,生成代码,在CPU、GPU或其他人工智能加速器上运行。包装器代码生成器取代了编译器堆栈的解释器部分,可以调用内核并分配内存。后端代码生成部分利用OpenAI Triton用于GPU并输出PTX代码。对于CPU,英特尔编译器生成C++(也会在非英特尔CPU上工作)。
今后将支持更多的硬件,但关键是Inductor极大地减少了编译器团队为其AI硬件加速器制作编译器时必须做的工作。此外,代码的性能更加优化。对内存带宽和容量的要求也大大降低。
我们不希望建立一个只支持GPU的编译器。我们想要的是可以扩展到支持各种硬件后端,而拥有C++以及[OpenAI]Triton则迫使我们具有这种通用性。
OpenAI Triton
OpenAI的Triton对Nvidia的机器学习闭源软件护城河来说是非常具有破坏性。Triton直接接受Python或通过PyTorch Inductor堆栈进行反馈。后者将是最常见的使用情况。然后,Triton将输入转换为LLVM的中间表示,然后生成代码。在Nvidia GPU的情况下,它直接生成PTX代码,跳过Nvidia的闭源CUDA库,如cuBLAS,而选择开源库,如cutlass。
CUDA通常被那些专门从事加速计算的人使用,但它在机器学习研究人员和数据科学家中却不太出名。它在高效使用方面有一定的挑战性,需要对硬件架构有深入的了解,这可能会拖慢开发过程。因此,机器学习专家可能要依靠CUDA专家来修改、优化和并行化他们的代码。
Triton弥补了这一差距,使高级语言能够达到与使用低级语言的人相当的性能。Triton内核本身对于典型的ML研究人员来说是相当可读的,这对于可用性来说是非常重要的。Triton将内存凝聚、共享内存管理和SM内的调度自动化。Triton对于元素-明智的矩阵乘法没有特别大的帮助,这些已经被非常有效地完成。Triton对于昂贵的逐点操作和减少更复杂的操作(如Flash关注)的开销非常有用,这些操作涉及矩阵乘法,是一个更大的融合操作的一部分。
OpenAI Triton今天只正式支持Nvidia的GPU,但这在不久的将来会发生变化。未来还将支持其他多个硬件供应商,这个开源项目正在获得令人难以置信的动力。其他硬件加速器能够直接集成到作为Triton一部分的LLVM IR中,这大大减少了为新硬件建立AI编译器栈的时间。
Nvidia庞大的软件组织缺乏远见,没有利用他们在ML硬件和软件方面的巨大优势,成为机器学习的默认编译器。他们缺乏对可用性的关注,这使得OpenAI和Meta的外部人员能够创建一个可以移植到其他硬件的软件栈。为什么他们不为ML研究人员建立一个像Triton一样的 "简化 "CUDA?像Flash注意力这样的东西,为什么是出自博士生而不是Nvidia?
本报告的其余部分将指出在微软大获全胜的具体硬件加速器,以及多个公司的硬件正迅速被整合到PyTorch 2.0/OpenAI Trion软件栈中。此外,它将分享相反的观点,作为对Nvidia在人工智能培训市场的护城河/实力的辩护。
首先,关于将与OpenAI Triton整合的硬件。AMD和Tenstorrent正积极地要深度整合到软件栈中。AMD已经有很多公开的GitHub提交。Luminous Computing的AI超级计算机正在PyTorch Dynamo层面上整合其软件栈。
据称,硬件方面的大赢家是在微软,AMD的MI300系列CPU/GPU。微软显然仍将购买Nvidia,但MI300的体面规模将有助于开始打破护城河。AMD在这里的强项是其硬件工程。AMD的下一代MI300是一个工程的奇迹。AMD对每瓦特性能的要求是非常高的。虽然英特尔和Nvidia有将GPU和CPU结合在一起的设想,但AMD将在2023年下半年开始将它们安装到下一代HPC中。此外,AMD正在用真正统一的HBM内存在1个包中完成这一切。

该芯片是可配置的,可以有各种数量的CPU或GPU瓦片。上面的渲染图是4个6纳米的瓦片,上面有9个5纳米的瓦片。3个5纳米的Zen 4个CPU芯片在其中一个6纳米的瓦片上,2个5纳米的GPU芯片在另外3个6纳米的瓦片上。这可以重新配置,以拥有更多的CPU或GPU芯片,尽管我们不确定他们是否同时运送这些其他变体。
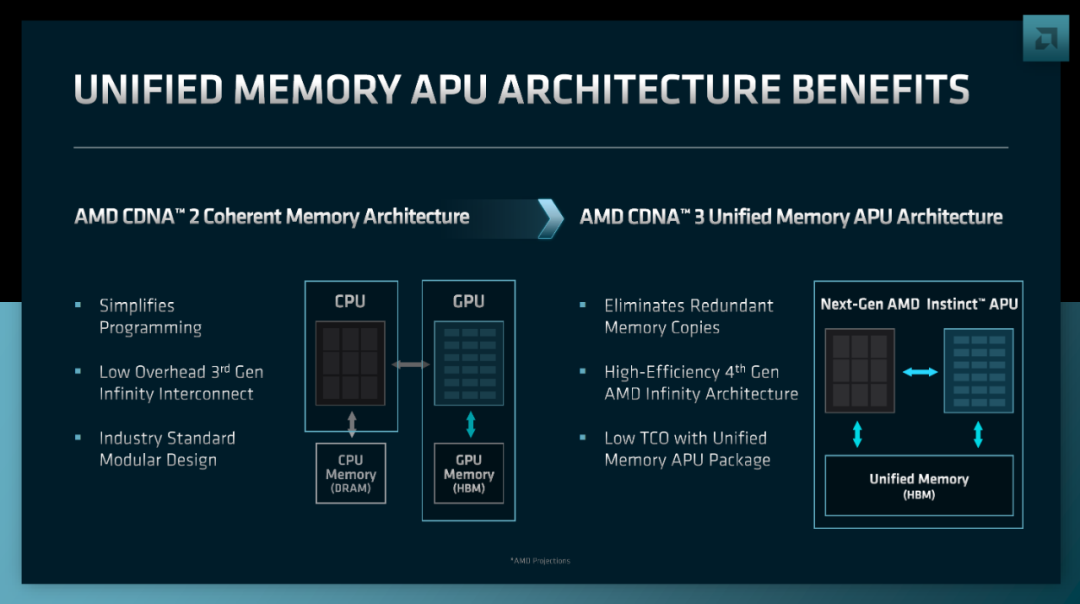
性能要求似乎很高,特别是当你看了AMD的一些脚注。例如,8倍的人工智能性能,5倍的人工智能性能/W,这简直是疯了! AMD测量了MI250X在560W TDP下的FP16性能为306.4 TFLOPS。这是其理论峰值性能的80%。AMD声称MI300的性能使用FP8,所以考虑到不同的数字格式,这种比较有点虚伪。不管怎么说,使用AMD的说法,MI300在900W TDP下的FP8性能为2400 TFLOPS,实现了5倍的性能/W和8倍的性能,与MI250X相比。Nvidia的Hopper GPU在700W的条件下可以达到FP8的~2000 TFLOPS,但它缺少CPU组件。
一旦包括Grace CPU组件,功率将上升到约900W,但它也将从CPU核心获得温和的性能提升。原始TFLOPS/W是相似的。Nvidia的Grace Hopper比MI300略早地批量出货。由于在封装、制造成本和NVLink网络方面的差异,它也是一个可以扩展到更高容量的设计。主要的缺点是,它仍然必须将数据从封装中传输出来,在CPU和GPU之间进行传输。虽然这使用的是NVLink,一个相对高带宽、低延迟的链接,但在每比特的功率、延迟和带宽方面,没有什么能与封装上的传输相比。
对上述报告的辩护是,Triton目前大量使用了Nvidia的开源库,如Cutlass。这些库对于第三方来说,几乎不存在可以插入AMD硬件的情况。当然,Nvidia开源了许多东西,这些东西很快被第三方供应商采用,包括Megatron等框架,该框架已经被亚马逊的内部培训硬件所支持。
在人工智能培训中,硬件公司的关键之处在于,尽可能简单地将正确的控制水平暴露给人们。人们会想要调整并试图理解为什么他们编写的模型表现不佳,但同时,进入硬件的挂钩不能太低级。Nvidia今天提供了这样的服务。
此外,我们跳过了对融合策略的整个讨论。不是每件硬件都以相同的方式融合相同的行动。这是一个必须做出的有意识的决定,而且融合策略应该在各代硬件之间进行调整。
谷歌的XLA为不同版本的TPU做了这个工作。今天,PyTorch和Triton中的默认会针对Nvidia硬件进行优化。这需要时间来为其他硬件调整这一策略。
我们还跳过了分布式硬件的整个故事。何时、何地以及如何拆分网络、张量、管道、数据等,都是由模型培训师明确地完成。他们更喜欢Nvidia的各种分布式训练库,如NCCL,来做这件事。竞争对手的库,如AMD的RCCL,都非常落后。Meta公司讨论人工智能硬件和联合封装光学器件。
需要注意的是,Nvidia有他们的NVSwitch盒子在发货。上面讨论得比较多,但Nvidia在某种程度上过度构建了网络。此外,他们正在进行一些计算操作,如在交换机中进行全还原,这是其他公司没有尝试过的。这将使扩展到数以千计的加速器变得更加容易。
简而言之,Nvidia拥有网络、软件和先发优势。这些优势在未来仍将保持强劲,Nvidia将保持90%以上的商户销售额。重要的威胁是,超大规模的公司将能够达到计算成本和内存的正确组合,而不需要Nvidia对许多工作负载的巨大加价。
缺乏一种为人工智能租用Nvidia GPU的方法,而没有云服务提供商的利润率x Nvidia的利润率,这是Nvidia的一个主要问题。我们预计Nvidia未来将开始提供更多的管理培训服务,以应对这一保证金堆积问题。否则,内部硬件将开始通过更低的成本击败他们。Nvidia已经提供了云游戏服务(GeForce Now)和创意云服务(Omniverse),所以这并不离谱。
本文为以下链接的编译版本
https://www.semianalysis.com/p/nvidiaopenaitritonpytorch
背景图和第一张图为Stable Diffusion制作。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢