
Language Models are Realistic Tabular Data Generators
V Borisov, K Sessler, T Leemann, M Pawelczyk, G Kasneci
University of Tuebingen
基于语言模型的逼真表格数据生成器
要点:
-
GReaT是一种新方法,用 Transformer-解码器网络架构生成现实的异质表格数据,通过文本编码方案连接表格和文本数据模态; -
GReaT提供了任意的调节能力,能对以任意给定的特征子集为条件的数据分布进行建模,并对剩余的特征进行采样; -
实验结果表明,GReaT在各种数据集上获得了最先进的生成性能。
一句话总结:
提出一种方法,GReaT(逼真表格数据生成),用大型语言模型生成高度逼真的合成表格数据,利用自回归生成式LLM对合成表格数据进行采样,同时在许多具有异质特征类型的现实世界数据集中保持最先进的性能。
摘要:
表格数据是最古老和最普遍的数据形式之一。然而,生成具有原始数据特征的合成样本,对于表格数据来说仍然是一个重大挑战。虽然计算机视觉领域的许多生成模型,如自编码器或生成对抗网络,已经被改编为表格数据的生成,但对最近基于 Transformer 的大型语言模型(LLM)的研究较少,这些模型在本质上也是生成的。本文提出GReaT(真实表格数据生成),利用一个自回归生成 LLM 来对合成的但又高度现实的表格数据进行采样。此外,GReaT 可通过对任何特征子集的调节来建立表格数据分布模型;其余的特征被抽样,没有额外的开销。本文在一系列的实验中证明了所提出的方法的有效性,这些实验从多个角度量化了所产生的数据样本的有效性和质量。GReaT 在许多具有不同大小的异质特征类型的真实世界数据集中保持了最先进的性能。
Tabular data is among the oldest and most ubiquitous forms of data. However, the generation of synthetic samples with the original data's characteristics remains a significant challenge for tabular data. While many generative models from the computer vision domain, such as autoencoders or generative adversarial networks, have been adapted for tabular data generation, less research has been directed towards recent transformer-based large language models (LLMs), which are also generative in nature. To this end, we propose GReaT (Generation of Realistic Tabular data), which exploits an auto-regressive generative LLM to sample synthetic and yet highly realistic tabular data. Furthermore, GReaT can model tabular data distributions by conditioning on any subset of features; the remaining features are sampled without additional overhead. We demonstrate the effectiveness of the proposed approach in a series of experiments that quantify the validity and quality of the produced data samples from multiple angles. We find that GReaT maintains state-of-the-art performance across many real-world data sets with heterogeneous feature types coming in various sizes.
https://openreview.net/forum?id=cEygmQNOeI
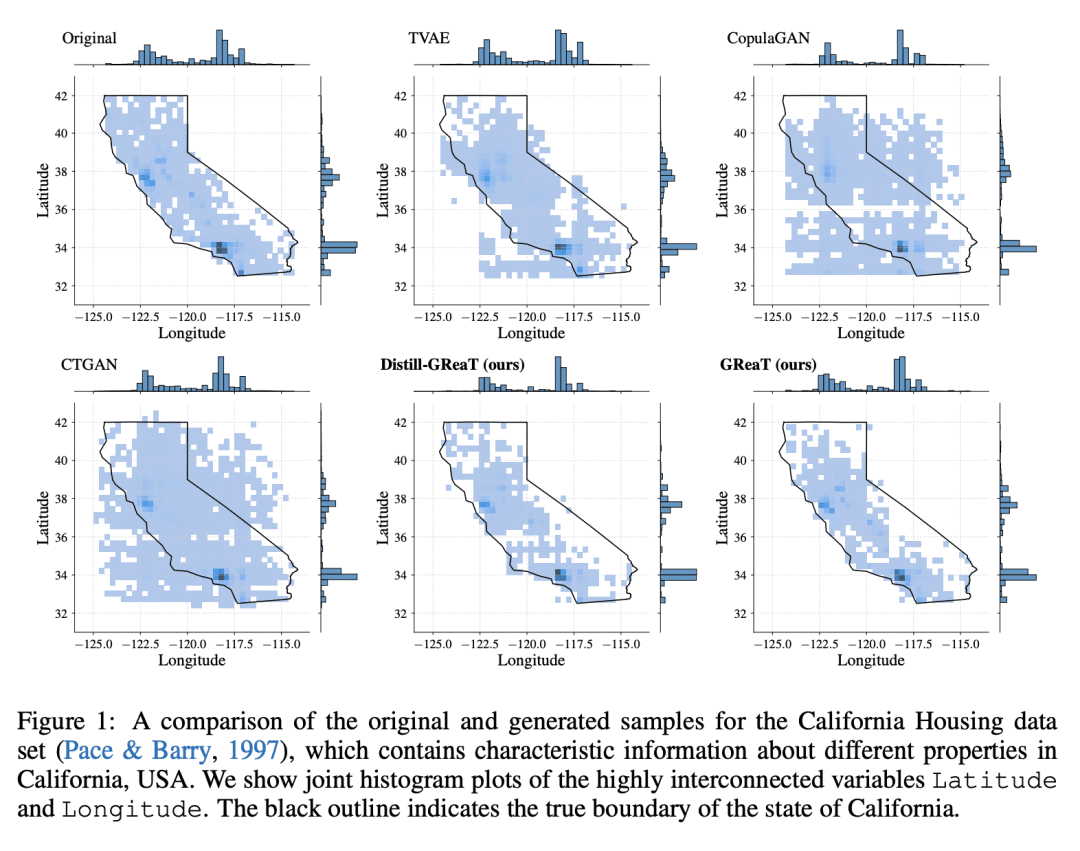
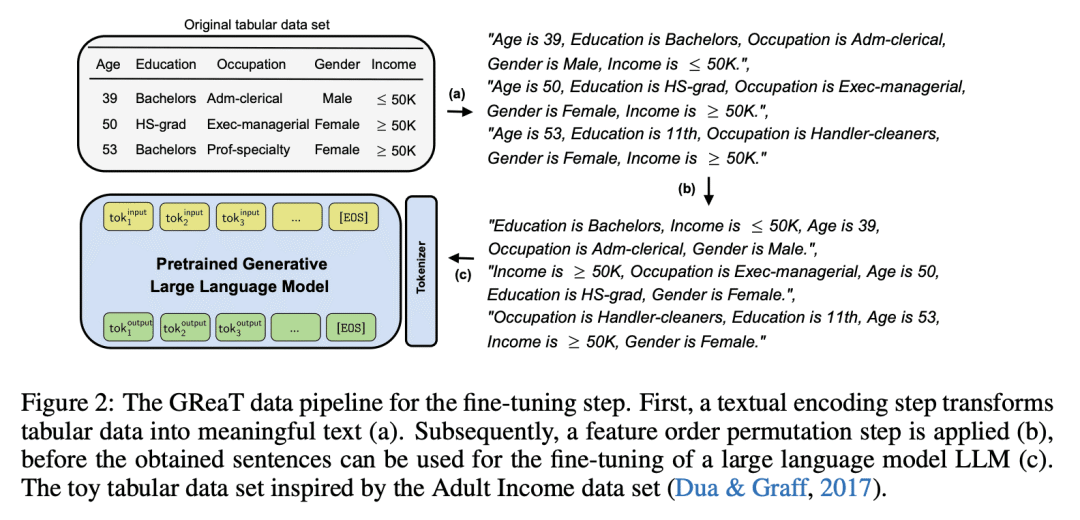
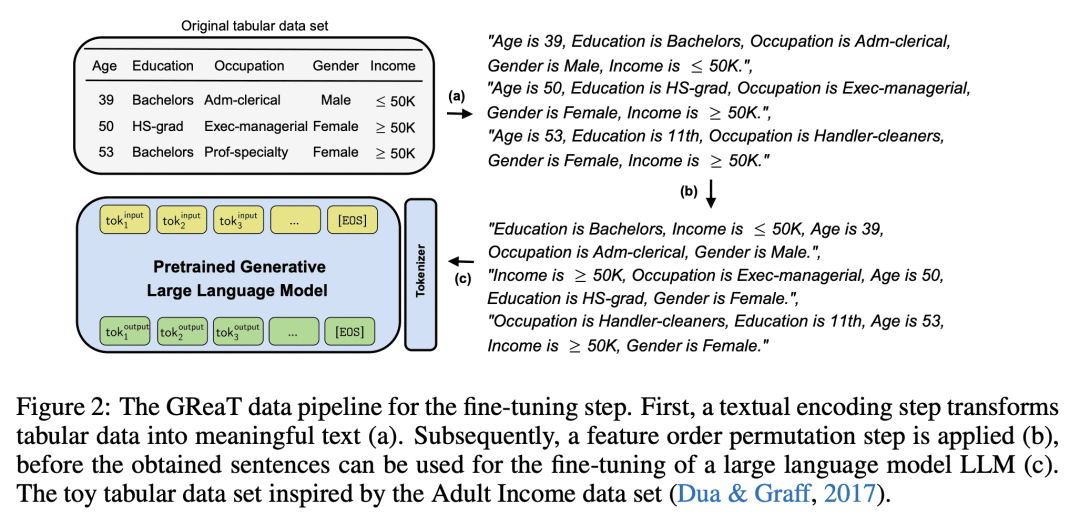
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢