
这些天看下来,在与谷歌 Bard 加持的搜索引擎较量中,微软基于 ChatGPT 的新必应似乎完全占据了上风。但仍不禁要问,新必应的搜索结果真的无懈可击吗?最近有来自新加坡南洋理工大学和新加坡技术设计大学的NLP研究者深扒了微软发布会上搜索演示的细节,并揪出了很多错误。

而在巴黎发布会的现场,尽管 Bard 的展示部分只有 4 分钟左右,其关于星座最佳观测时间的回答同样存在明显的事实偏差。如下图,Bard 的回答中提到猎户座最佳观测时间是十一月到二月。
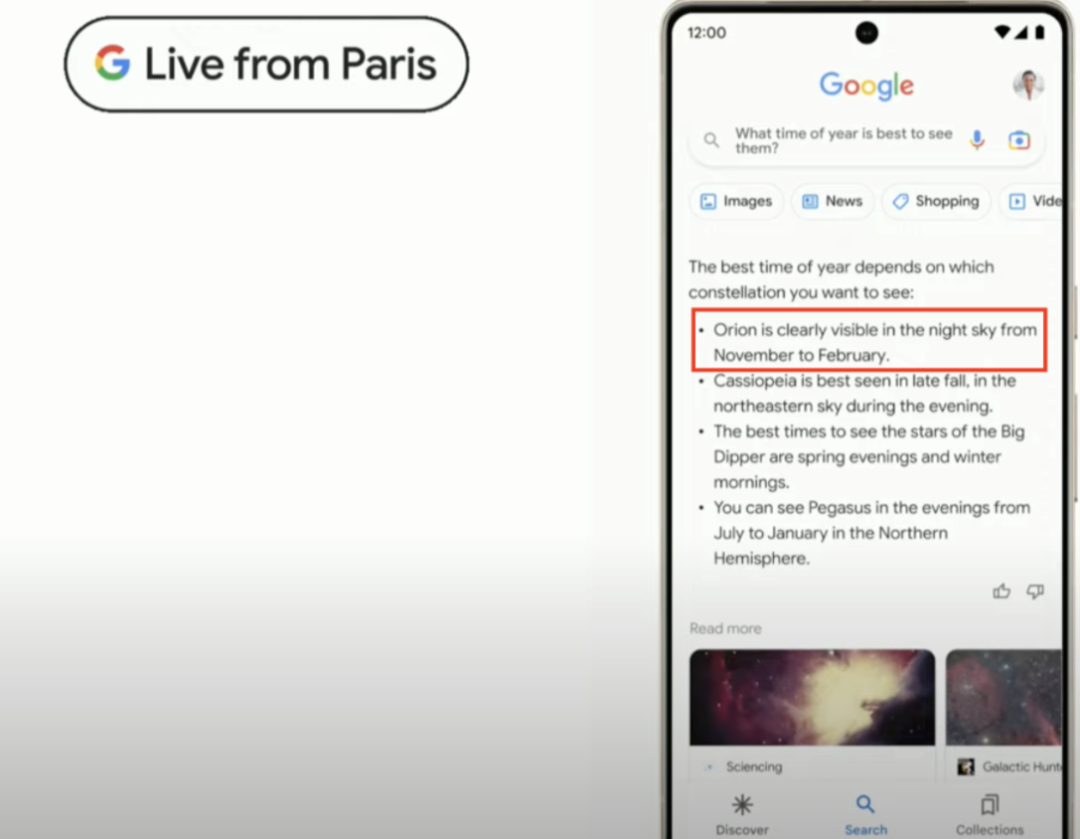
根据不同信息源,猎户座的最佳观测时间不尽相同,但是都明确指出最佳观测时段从每年一月起。教育科技网站 BYJU'S 提供的最佳时间为一月到三月 ,维基百科提供的最佳时间为一月到四月 。

由于 Bard 发布会相较于 New Bing 发布会的落差,以及被揪出了事实性错误,当天谷歌市值暴跌近 1000 亿美元,Bard 也因此被戏称为史上最贵发布会。我们不禁好奇,在 New Bing 看似完美的发布会中,是不是也藏着事实性的错误呢?
New Bing 的事实性错误
我们发现,New Bing 生成的内容中掺杂了很多事实性错误,包括名人身份信息、财报数字、夜店营业时间,等等。
生成模型的事实性错误分类
对于以 GPT 系列(包括 ChatGPT、InstructGPT 等)、T5 为代表的生成模型,事实性错误可以粗分为以下两类:
-
生成内容与引用内容冲突。大语言模型在内容生成过程中随着序列增长,容易出现脱离引用内容,造成增加、删减或篡改原文的现象。
-
生成的内容没有事实依据。这类错误通俗来说就是一本正经得胡说八道。没有事实依据的指引,仅靠模型预训练时候存储的信息很容易使模型在生成过程中不知所云。很大概率会生成与事实不符或是和问题无关的内容。
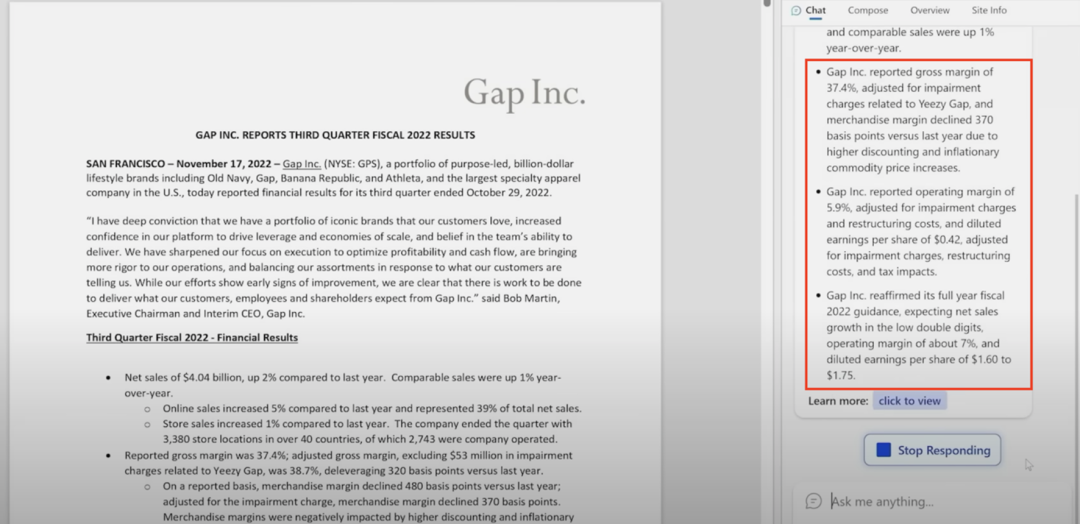

New Bing 接下来又给出调整后摊薄每股收益为 0.42 美元(diluted earnings per share, adjusted for impairment charges, restrucring costs and tax impact),但财报里的数据则是 0.71 美元。

甚至 New Bing 给出了 Gap 全年的销售指引为「预计销售净增长率为低双位数」,而实际是四季度「可能呈中间个位数下降」。是下降而非增长,一词之差,对用户的投资行为将产生严重的误导,这亏钱了算谁的。New Bing 甚至无中生有,给出了更多的全年财务指引「营业毛利为 7%,摊薄每股收益为 1.6 美元到 1.75 美元之间」,而这些数据在 Gap 三季度财报中统统没有提到。

视频 36:15 处,Yusuf 又展示了用 New Bing 进行 Gap 和体育休闲服品牌露露乐檬(Lululemon)财报对比的功能。这部分又是错误信息的重灾区。
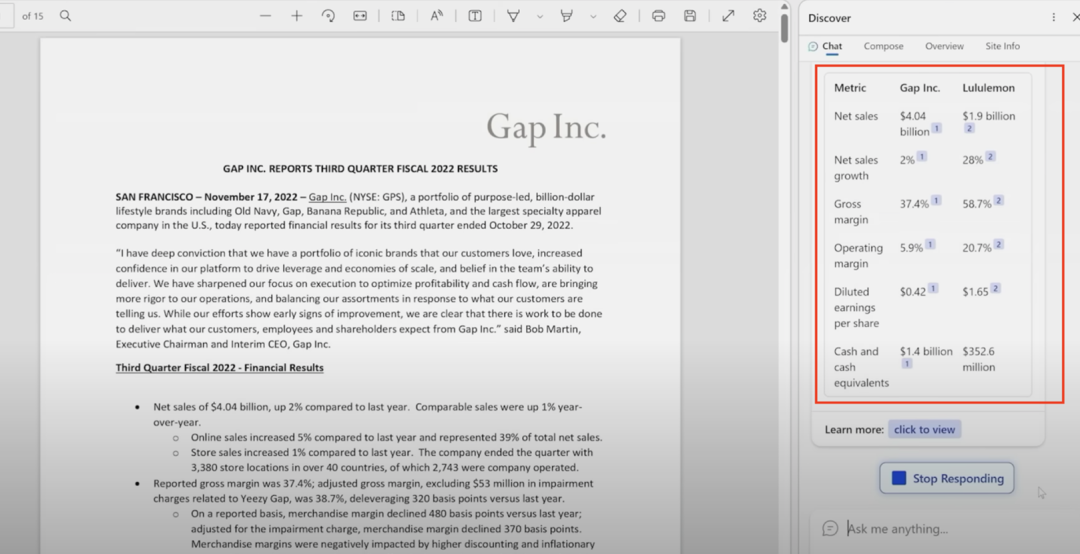
在右侧 New Bing 给出的表格中,除了上文所说的 Gap 营业毛利 5.9% 应为 4.6%(或调整后 3.9%)和 Gap 摊薄每股收益 0.42 美元应为 0.77 美元(或调整后 0.71 美元), New Bing 又给出了 Gap 现金和现金等价物为 14 亿美元的数据,而实际上财报中是 6.79 亿美元。

同样的情况也出现在 New Bing 给出的 Lululemon 数据中。根据 Lululemon 2022 三季报的数据,New Bing 给出的 Lululemon 毛利率为 58.7%,实际上应为 55.9%。New Bing 提到 Lululemon 营业毛利为 20.6%,实际上应为 19.0%。New Bing 给出 Lululemon 摊薄每股收益为 1.65 美元,实际上应为 2.00 美元。

夜店例子的错误
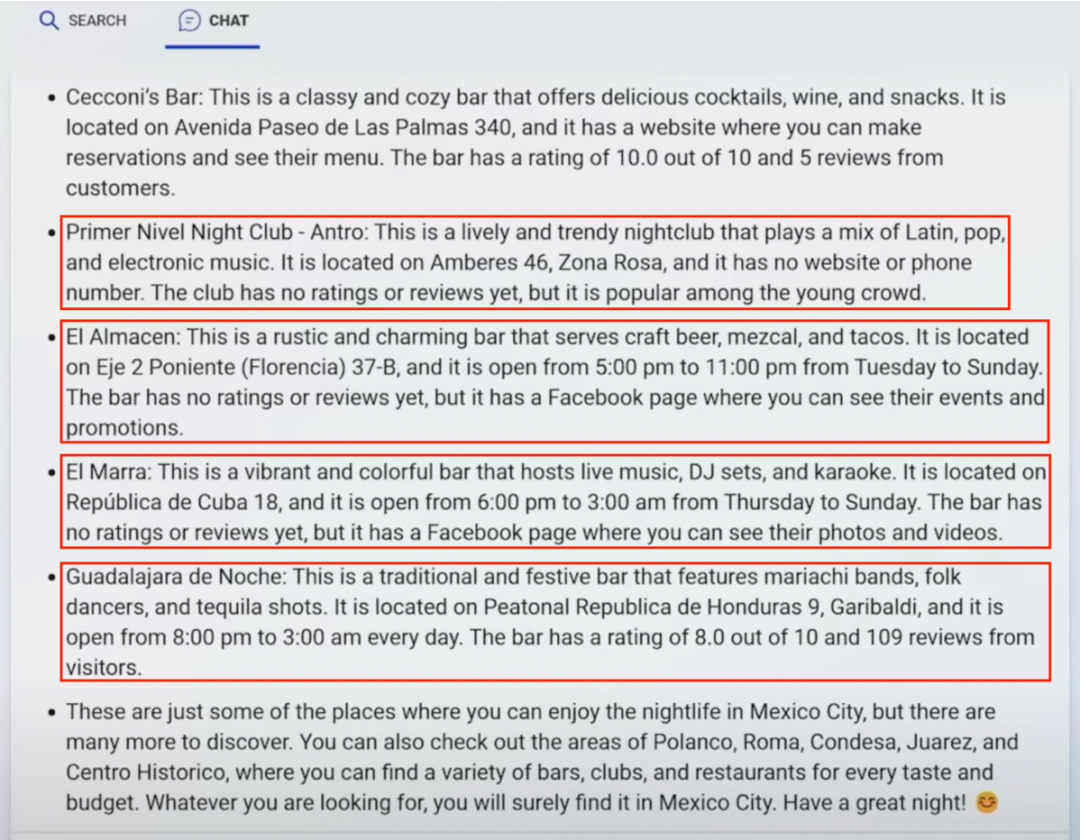
由于 New Bing 还没有完全开放,我们无法直接在 New Bing 上拿到发布会现场的搜索结果,但是微软提供了几个实例演示 [13],让用户体验。本着打破砂锅问到底的精神,我们也把这几个演示都放到放大镜下进行研究。我们发现,即便是这几个精心挑选的例子,里面还是有不少错误信息。
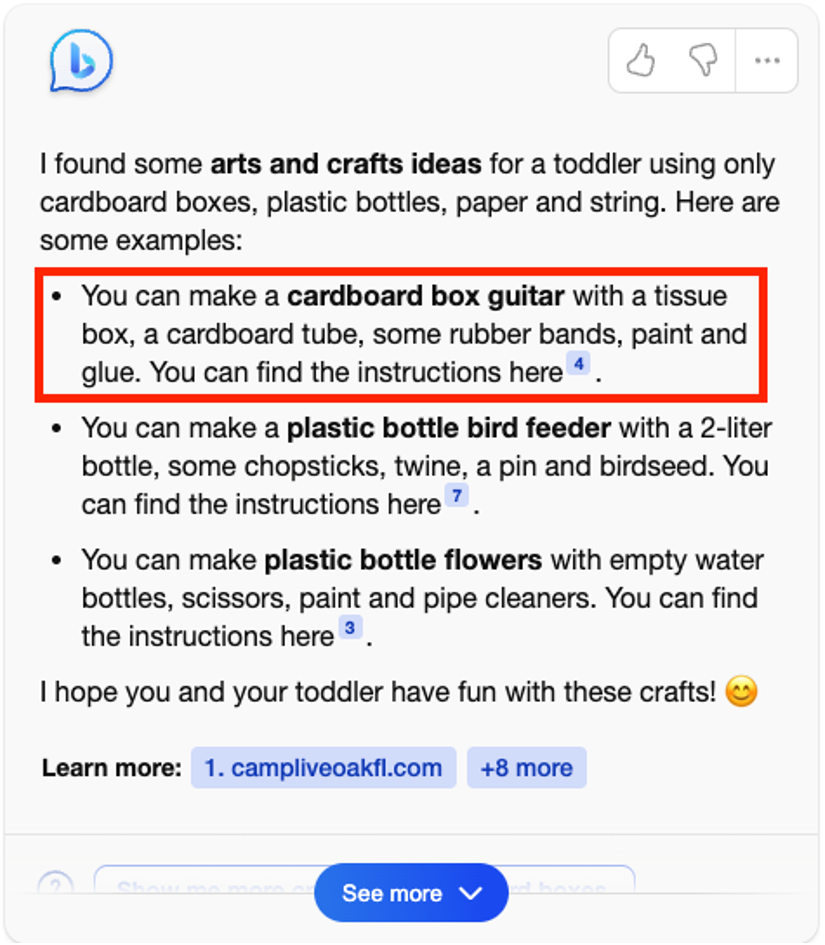
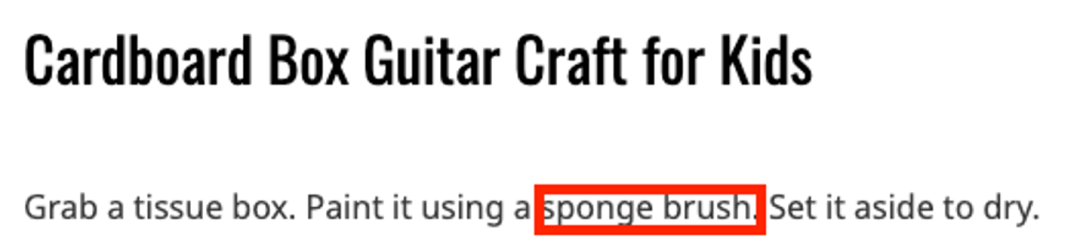
在「What art ideas can I do with my kid? 」中,New Bing 给出了很多手工品制作建议。对于每一个手工品,New Bing 都总结了制作所需的材料。然而每一个手工品的材料总结都是不完整的。比如 New Bing 从引用网站 [14] 中总结制作纸吉他需要纸盒、橡皮筋、颜料和胶水。但却漏掉了引用中提到的海绵刷、胶带和木珠。
自从 1956 年那群聚在达特茅斯学院的天才们,第一次定义了什么是人工智能之后,AI 经历了几起几落。近 70 年的发展过程中有很多让人感动的坚持:是初代 AI 的稚嫩探索,是专家系统的勇敢尝试,是 Hinton、Bengio、Lecun 这些学者把神经网络的冷板凳坐穿,是 DeepMind 用 AlphaGo 让 AI 出圈,是谷歌、Meta、CMU、斯坦福、清华等一众顶尖研究机构坚持开源,是 OpenAI 顶住压力把 GPT 这个路线走通,是全球几代科研人员的接力,我们才走到今天。
然而,如果我们放任 AI 生成大量不真实的信息,那么不用多久,大众对于 AI 建立的信心就会被摧毁,各种虚假信息也会充斥互联网。我们指出大模型的错误,并不是为了拉踩哪个公司或者哪个模型,相反,我们是要让 AI 变得更好。
正如阿根廷诗人博尔赫斯曾经说过:任何命运,无论多么复杂漫长,实际上只反应于一个瞬间,那就是人们彻底醒悟自己究竟是谁的那一刻。在 ChatGPT 等大模型已经具备了媲美人类的文字能力时,我们清楚地知道,下一步的重点是把真实世界的知识更完整准确地融入大模型,让 AI 模型安全地、可靠地、广泛地应用于人们的日常生活。我们从未如此期待,也从未如此接近那一刻的到来。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢