

论文标题:CORE: A Retrieve-then-Edit Framework for Counterfactual Data Generation
论文链接:https://aclanthology.org/2022.findings-emnlp.216/
01
—
方法介绍
1、通过对自然语料检索增强反事实数据生成过程中的多样性
2、借助GPT-3的in-context learning能力,对已有数据与检索到的数据进行编辑(结合)得到增强数据。
下面以文中做的情感分类任务为例进行介绍。
传统基于替换的反事实数据增强,以情感分类任务为例:这中间包括以下步骤:

①待替换词选择,如左上例中的opaque(难懂的)、plain(无聊的),都是导致情感极性为negative的causal term,翻转标签同时需要替换这些词。
②替换:如将opaque(难懂的)替换为delightful(令人愉快的)。
但是这种直接替换的策略会产生大量噪声,生成大量低质量样本。
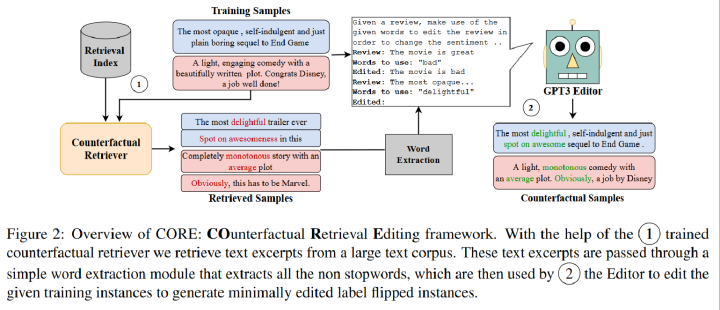
Retrieve阶段的目标:
从大型未标记语料库中检索具有不同标签的相似实例(下图两红框)。

Edit阶段的目标:
将这些具有不同标签的相似实例中的关键词抽取出来,并借助GPT-3的in-context learning能力,将这些关键词编辑到原始样本中。
02
—
方法优劣
文章启发(优点)
1、启发:反事实数据增强要重点关注生成新样本的多样性与可控性。
本文的Retrieve部分体现的是对多样性的关注,Edit部分体现的是对可控性的关注。
2、与直接进行词替换的不同点:
①借助GPT-3 自动选择原样本中的待替换部分。相当于免去了基于替换的反事实数据增强中的找causal term的阶段。得益于GPT-3强大的上下文学习能力,这样可能可以做得更好。
②通过检索相似样本找到更符合原样本上下文语境的替换词。相当于免去了基于替换的反事实数据增强中的过滤阶段(过滤是为了删除那些质量低、噪音大的样本)。这样做可能会减少生成反事实样本中的噪声。
3、对GPT-3的in-context learning在反事实数据生成领域的用法进行了探索
文章缺陷(可改进部分)
Retrieve部分的检索模型、关键词抽取模型都需要额外的训练数据。这种方式会导致与其他模型效果的不公平对比。且如果检索出的具有不同标签的相似实例有误(比如说检索到的实例的标签与原样本标签相同),可能会有负面影响。
总结:本文探索了GPT-3的使用思路,但是需要的额外数据与模型太冗杂,可能也是仅中findings的原因。

关注,定期带来NLP、多模态领域最新解读!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢