
给出一段文字,人工智能就可以生成音乐,语音,各种音效,甚至是想象的声音,比如黑洞和激光枪。
最近由英国萨里大学和帝国理工学院联合推出的AudioLDM,在发布之后迅速火遍国外,播放次数超过 35.4K 次,被转发了 130 余次。
论文有两位共同一作:刘濠赫(英国萨里大学)和陈泽华(英国帝国理工学院)。
在模型开源第二天,AudioLDM就冲上了 Hugging Face 热搜榜第一名,并在一周内进入了 Hugging Face 最受喜欢的前 40 名应用榜单(共约 25000),也迅速出现了很多基于 AudioLDM 的衍生工作。

AudioLDM 模型亮点:
-
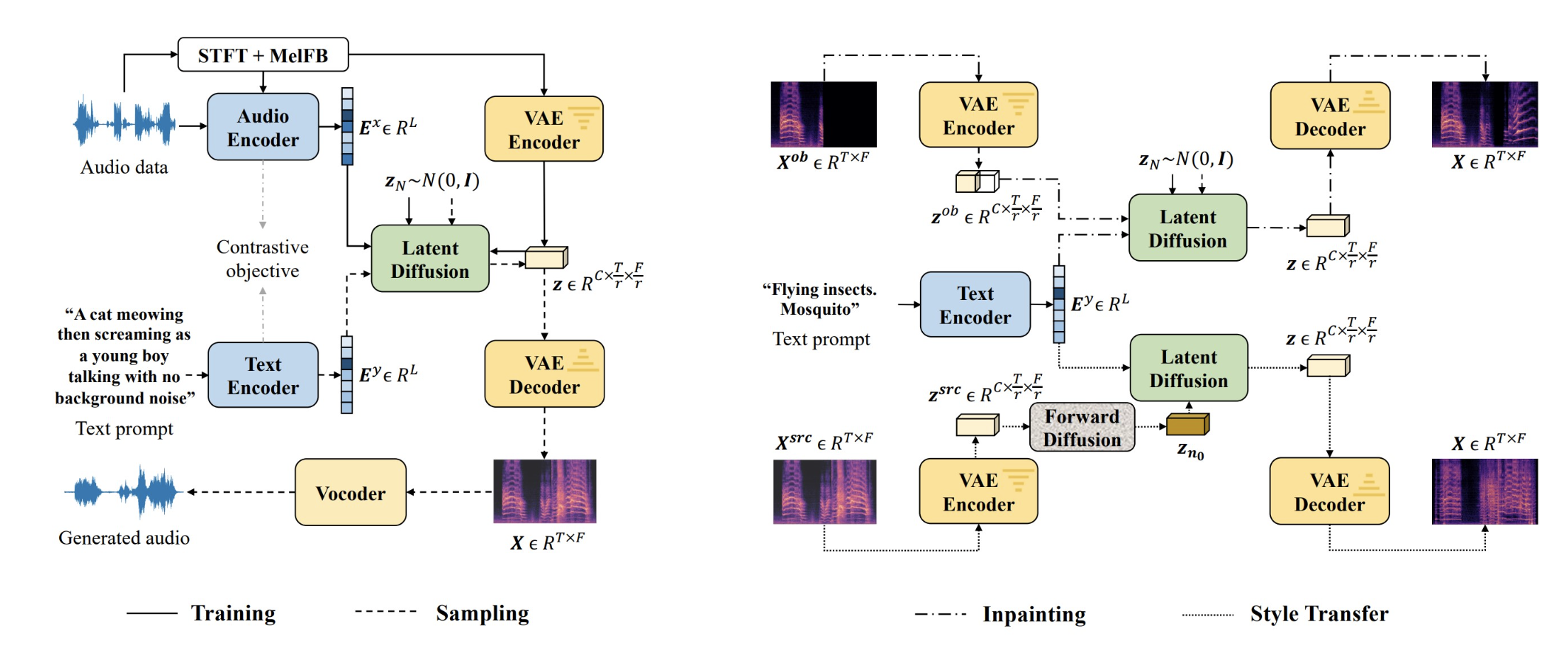
首个同时可以从文本生成音乐,语音和音效的开源模型。
-
由学术界开发,用更少的数据,单个 GPU,以及更小的模型,实现了目前最好的效果。
-
提出用自监督的方式训练生成模型,使文本指导音频生成不再受限于(文本-音频)数据对缺失的问题。
-
模型在不做额外训练的情况下(zero-shot),可以实现音频风格的迁移,音频缺失填充,和音频超分辨率。
-
Hugging Face Space:https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢