

论文地址:https://arxiv.org/abs/2208.05768
代码地址:https://github.com/winycg/Self-KD-Lib
摘要
传统的知识蒸馏(Knowledge Distillation,KD)需要一个预训练的教师模型来训练一个学生模型,这种模式的缺点是需要设计并训练额外的教师网络,并且两阶段的训练过程提升了流水线开销。自网络知识蒸馏(Self-Knowledge Distillation,Self-KD),顾名思义,则是不依赖额外的教师网络进行指导,利用网络自身的知识来指导自身的学习,从而实现自我提升。
由于Self-KD没有额外的高性能教师模型进行指导,通常性能提升十分有限。最近,我们提出了一种从Mixup图像[1]中进行Self-KD的方法MixSKD,该方法通过从混合图像中挖掘知识,从而提升了模型图像识别效果,进一步在目标检测和语义分割的下游任务上也表明提出的MixSKD能使得backbone网络学习到更好的特征。
引言
由于没有额外的教师模型,现有的Self-KD工作通常使用辅助结构或者数据增强的方式来捕捉到额外的知识,从而指导自身的学习。基于辅助结构的方法[2]通常利用添加的分支来学习主任务,Self-KD引导辅助分支和主干网络之间进行知识迁移。基于数据增强的方法[3]通常在输入端创建来自相同实例的两个不同增强的视角,Self-KD约束两个视角具有一致的输出。先前Self-KD方法的一个共同点是生成的软标签是都是来源于单独的输入样本的。
本文提出将混合图像Mixup和Self-KD融合为一个联合的框架,名为MixSKD。MixSKD整体的思想如图1所示。给定两张输入图像 \( x_i \) 和 \( x_j \) ,可以分别得到概率分布 \( p_i \) 和 \( p_j \) ,之后进行线性插值可得到集成的软标签 \( p_{ij} \) ,之后将 \( p_{ij} \) 与Mixup图像得到的概率分布进行相互蒸馏。直觉上,集成的软标签 \( p_{ij} \) 包含了原始两张图像的预测信息,可以被认为是一个伪教师分布来提供综合的知识。基于Mixup的概率分布可以被认为是一个数据增强分布来微调 \( p_{ij} \) ,从而学习鲁棒的混合预测和避免过拟合。除了在最终输出的概率层面,MixSKD还在中间特征层对插值特征和Mixup特征进行互蒸馏。MixSKD引导网络针对输入图像( \( x_i \) , \( x_j \) )及其插值的Mixup图像之间产生一致的输出信息,从而使得网络具有线性决策行为。
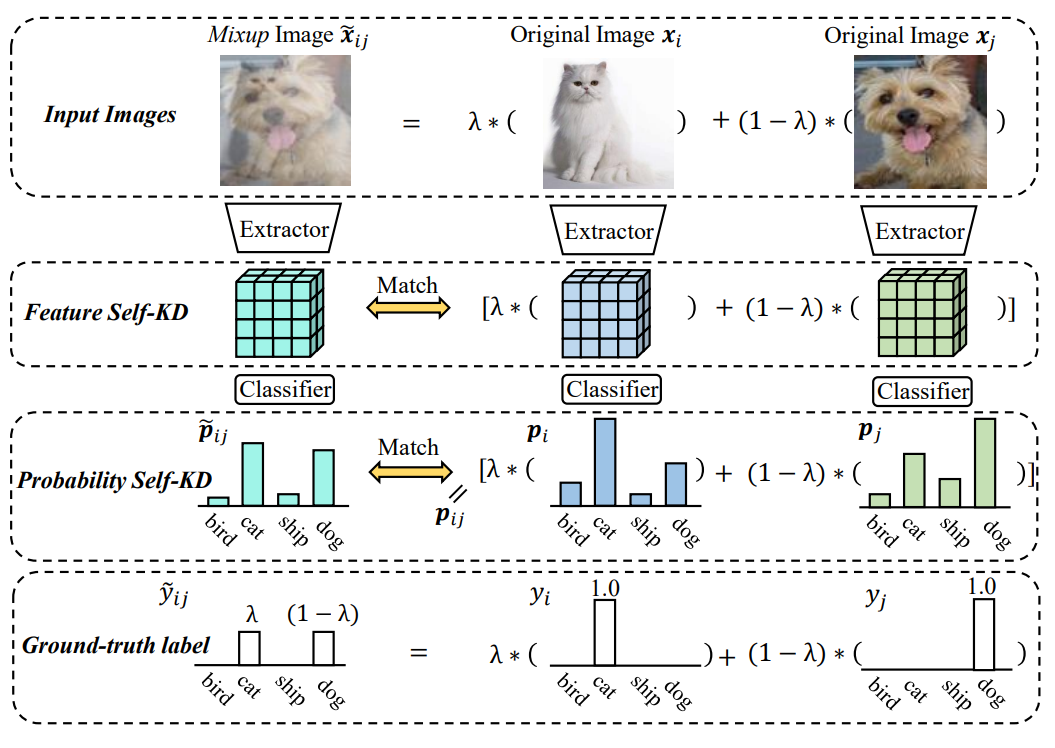
图1. MixSKD基本思想
方法
1 任务引导的分类误差
来自结构源的误差:使用原始的交叉熵任务误差来训练主网络f和K-1个辅助分支,使之获得分类能力和产生语义特征:
\( L_{cls\_b\_f}(x,y)=L_{ce}(\sigma(f(x)),y)+\sum_{k=1}^{K}L_{ce}(\sigma(b_{k}(x)),y), \)
来自数据源的误差:给定输入图像 \( x_i \) , \( x_j \) 和Mixup图像 \( x_{ij} \) ,代入结构源的误差,可以得到任务误差:
\( L_{cls\_mixup}=L_{cls\_b\_f}(x_{i},y_{i})+L_{cls\_b\_f}(x_{j},y_{j}) +L_{cls\_b\_f}(\tilde{x}_{ij},\tilde{y}_{ij}) \)
2 特征图Self-KD
使用L2距离来逼近原始图像插值得到的特征图与Mixup图像生成的特征图:
\( L_{feature}=\sum_{k=1}^{K}\frac{1}{HWC}\parallel \tilde{F}_{k}(x_{i},x_{j}) - F_{k}(\tilde{x}_{ij})\parallel^{2}. \)
受对抗学习思想的启发,本文引入了一个判别器来判别特征来源于插值还是Mixup图像来提升特征逼近的难度,从而使得网络能够学习到有效的语义特征:
\( L_{dis}=-\sum_{k=1}^{K}\log[D_{k}(\tilde{F}_{k}(x_{i},x_{j}))]+\log[1-D_{k}(F_{k}(\tilde{x}_{ij}))]. \)
3 概率分布Self-KD
本方法使用KL散度去逼近原始图像插值得到的概率分布与Mixup图像产生的概率。在K-1辅助分支上使用如下的误差:
\( L_{b\_logit}((x_{i},x_{j}),\tilde{x}_{ij})=\sum_{k=1}^{K-1}[L_{KL}(\sigma(\tilde{b}_{k}(x_{i},x_{j})/T),\sigma(\overline{b_{k}(\tilde{x}_{ij})}/T))+L_{KL}(\sigma(b_{k}(\tilde{x}_{ij})/T),\sigma(\overline{\tilde{b}_{k}(x_{i},x_{j})}/T)]. \)
对于最终的主干网络,本方法进一步构造了一个self-teacher网络来提供高质量的软标签作为监督信号。self-teacher网络聚合网络中间层的特征,然后通过一个线性分类器输出类别概率分布,受到Mixup插值标签的监督:
\( L_{cls\_h}=L_{ce}(\sigma(h(x_{i},x_{j})),\tilde{y}_{ij})+L_{ce}(\sigma(h(\tilde{x}_{ij})),\tilde{y}_{ij}). \)
主干网络最终输出的类别概率分布的监督信号来源于self-teacher网络:
\( L_{f\_logit}((x_{i},x_{j}),\tilde{x}_{ij})=L_{KL}(\sigma(\tilde{f}(x_{i},x_{j})/T),\sigma(h(\tilde{x}_{ij})/T))+L_{KL}(\sigma(f(\tilde{x}_{ij})/T),\sigma(h(x_{i},x_{j})/T)). \)
4 整体误差
将上述误差联合起来作为一个整体误差进行端到端的优化:
\( L_{MixSKD}=\underbrace{L_{cls\_mixup}}_{task\ loss}+\underbrace{\beta L_{feature}+\gamma L_{dis}}_{feature\ Self-KD} +\mu(\underbrace{L_{b\_logit}+L_{cls\_h}+L_{f\_logit}}_{logit\ Self-KD}). \)
MixSKD的整体示意图如图2所示。本方法引导网络在隐层特征和概率分布空间具有线性决策行为。从Occam剃刀原理上讲,线性是一个最直接的行为,因此是一个较好的归纳偏置。此外,线性行为可以在预测离群点时减少震荡。
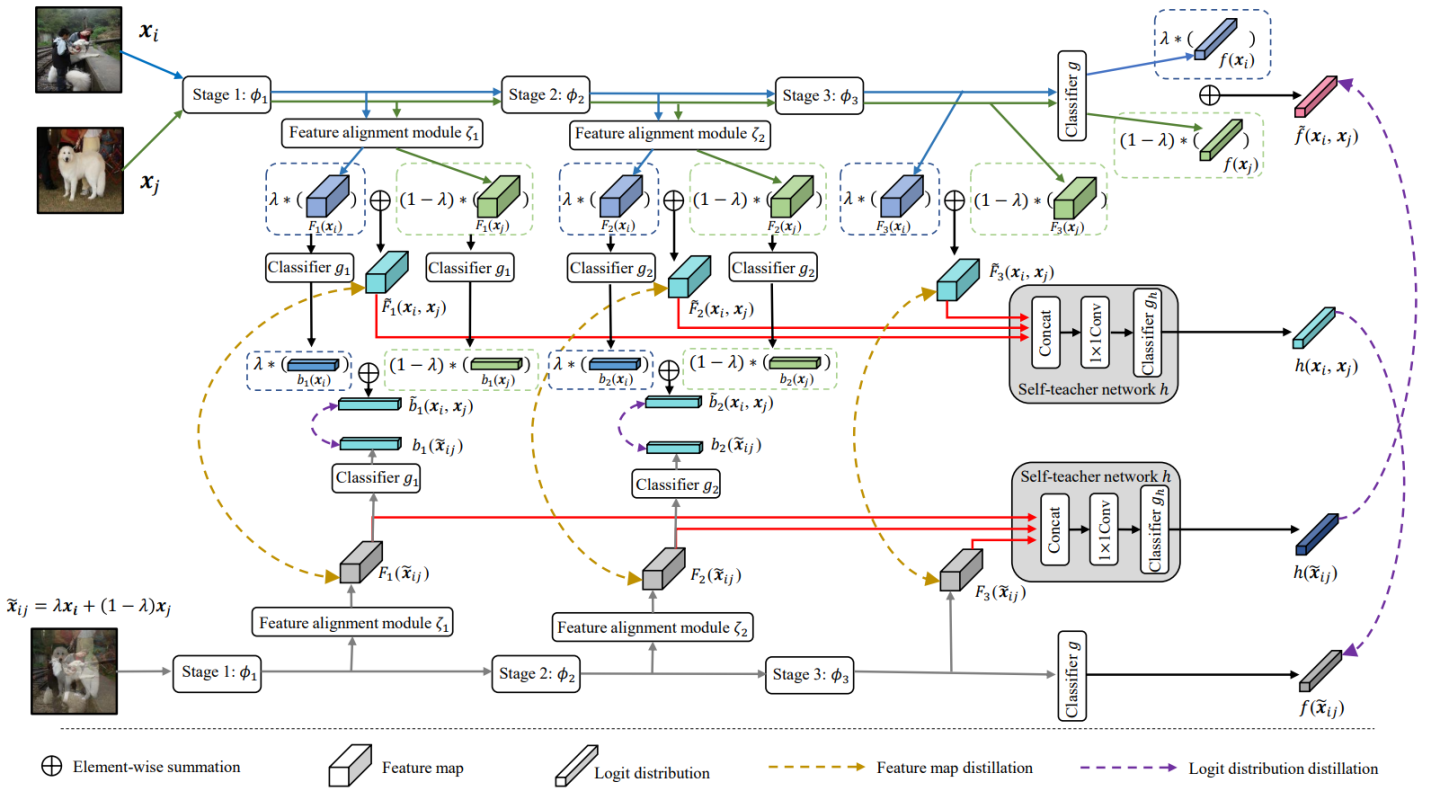
图2.MixSKD整体示意图
实验结果
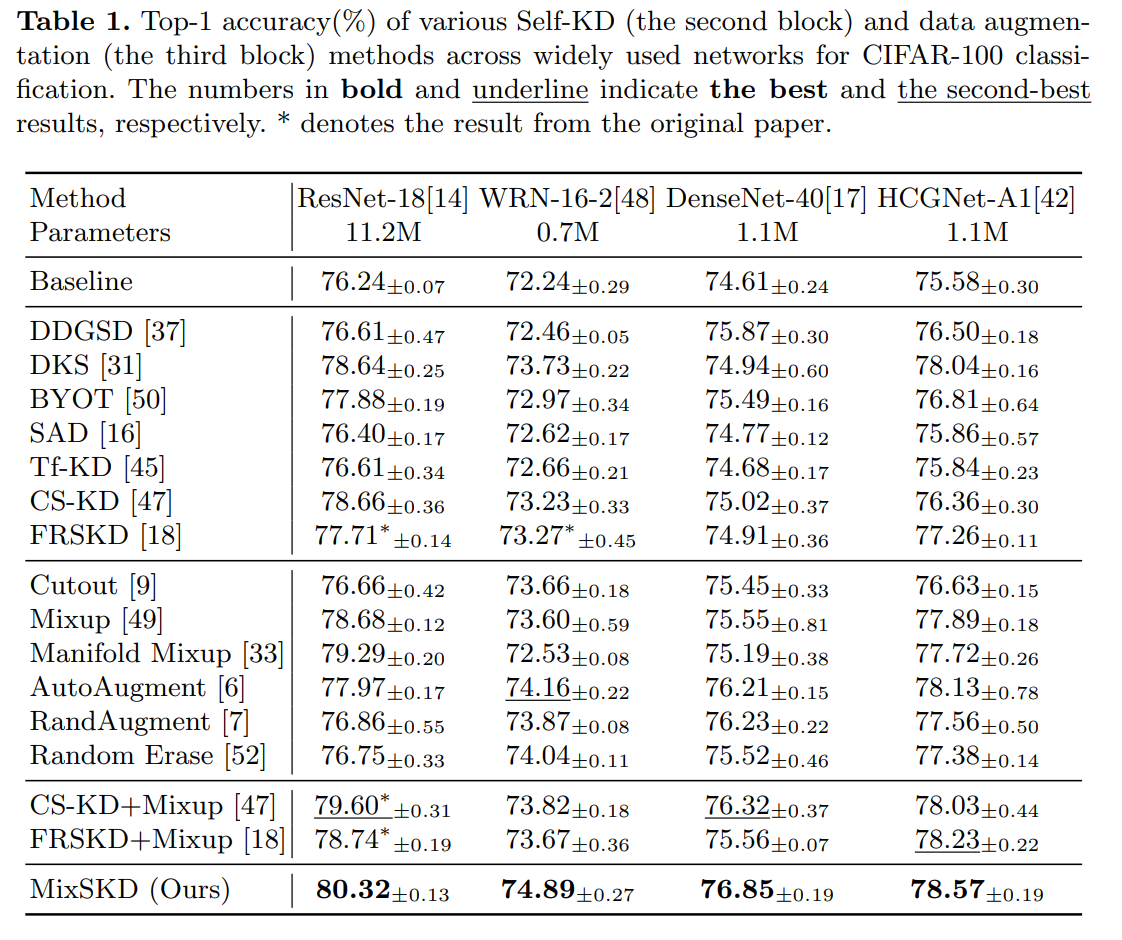
1 MixSKD用于CIFAR-100图像识别
如表所示,MixSKD在不同网络结构上超越了先前的Self-KD与数据增强方法:
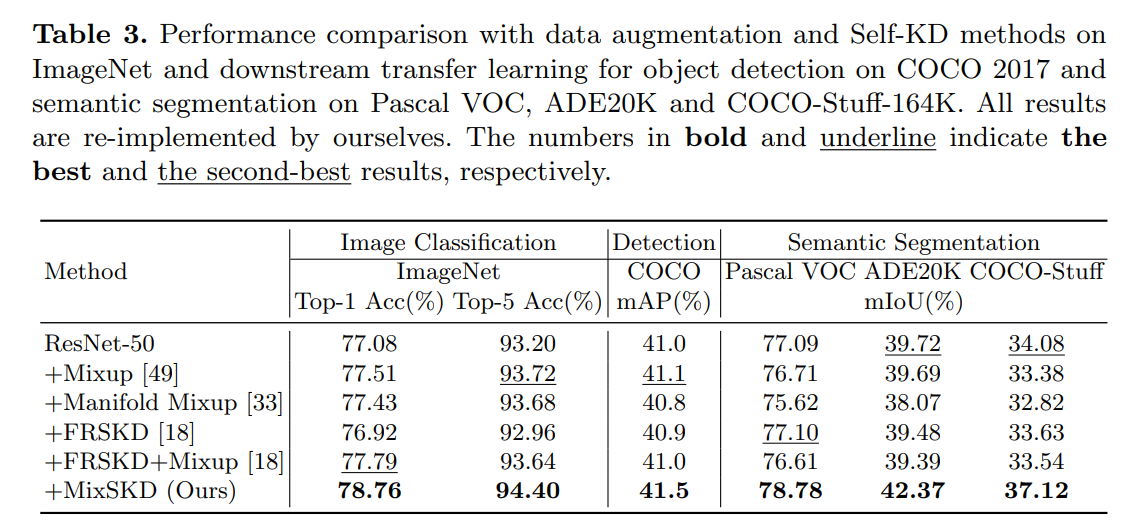
2 MixSKD用于大规模ImageNet图像识别并用于下游的目标检测和语义分割
如表所示,MixSKD用于大规模ImageNet图像识别并用于下游的目标检测和语义分割, 获得了最佳的表现。
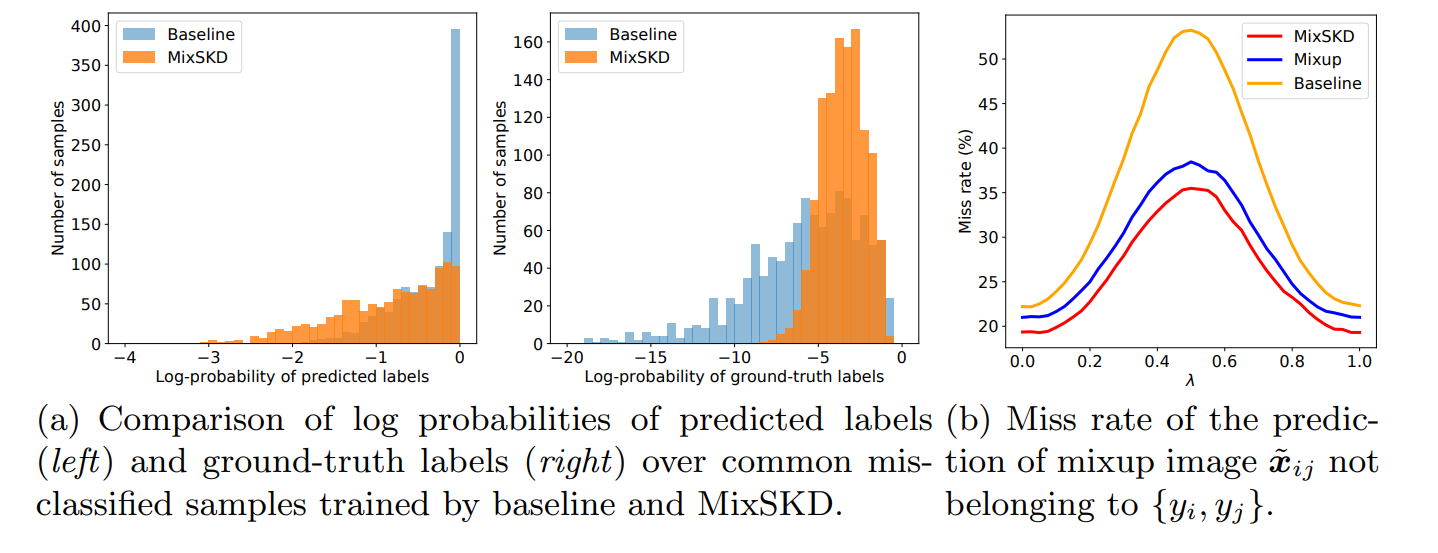
3 预测分布分析
从左边两张图可以看出,MixSKD相比baseline具有更好的预测质量。对于公共分类错误的样本,MixSKD在错误类别概率上值更小,在正确类别概率上值更大。从第三张图上可以看出,在不同混合系数的混合图像下,MixSKD相比Mixup具有更低的错误率。
本篇论文提出了MixSKD,一种Self-KD方法来约束网络在Mixup图像的特征图和类别概率层面上表现出线性行为。此外,本文构建了一个辅助的self-teacher网络来迁移外部的集成知识到主干网络。在计算机视觉基准上,MixSKD方法超越了先前最好的数据集增强和Self-KD方法。本文希望可以启发未来的研究可以从信息混合角度入手提升视觉识别表现。
参考文献:
[1] Zhang et al. Mixup: beyond empirical risk minimization. ICLR-2018.
[2] Zhang et al. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. ICCV-2019.
[3] Xu et al. Data-distortion guided self-distillation for deep neural networks. AAAI-2019.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢