
【标题】A Categorical Archive of ChatGPT Failures
【作者团队】Ali Borji
【发表时间】2023/02/10
【机 构】Quintic AI
【论文链接】https://arxiv.org/pdf/2302.03494v2.pdf
大型语言模型已被证明在不同领域具有价值。由OpenAI开发的ChatGPT已经使用海量数据进行了训练,并通过理解上下文来模拟人类对话。由于它能够有效地大范围回答地人类询问,其流畅和全面的回答在安全性和实用性方面都超过了之前的聊天机器人,因此它获得了极大的关注。然而,目前还缺乏对ChatGPT失败的全面分析,这也是本研究的重点。本报告提出并讨论了十类失败,包括推理、事实错误、数学、编码和偏见。还强调了ChatGPT的风险、限制和社会影响。本研究的目的是协助研究人员和开发人员加强未来的语言模型和聊天机器人。
本文展示了一些ChatGPT失败的例子,分为十个类别:
1. 推理:
ChatGPT这样的模型缺乏一个世界模型,这意味着它们不具备对物理和社会世界的完整理解,也不具备推理概念和实体之间联系的能力,只能根据它们在训练期间学到的模式来生成文本。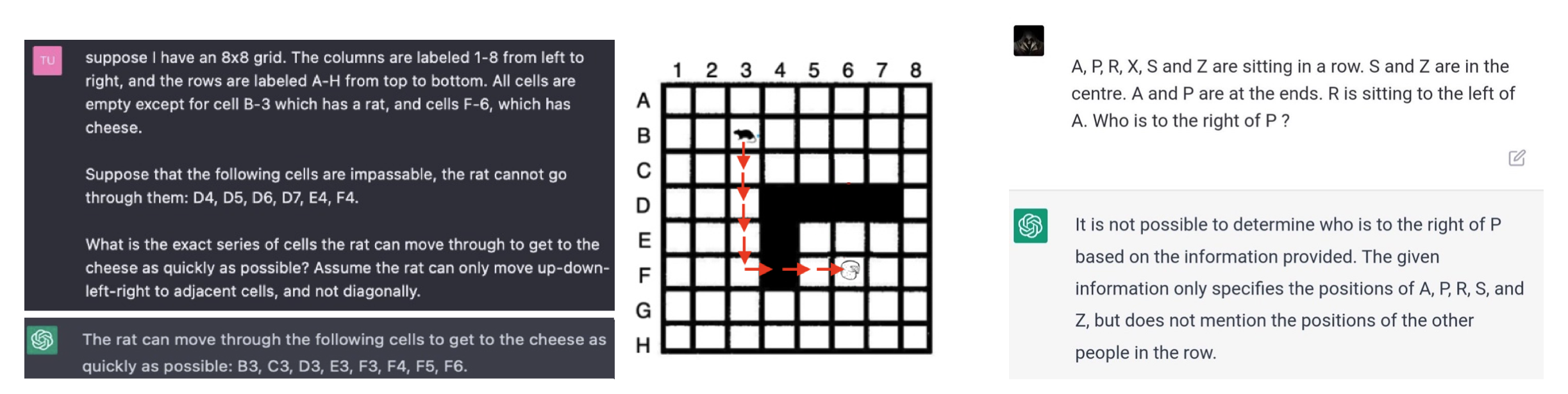
上图展示了作者进行的空间推理的操作,空间推理是指理解和处理周围物理空间中物体、人和地方之间关系的能力。它涉及到将二维或三维空间中的物体形象化并在头脑中进行转换,以及识别物体之间的模式、转换和关系。空间推理能力对许多任务和活动都很重要,如导航、解决问题、在头脑中想象物体和结构,从上图可以看到ChatGPT确实拥有某种程度的空间理解能力。
另外作者也分析了其他推理能力,展示了ChatGPT在时间推理和心理推理上的失败,物理推理在老版本失败了但是在新版本成功了。
2. 逻辑
逻辑是数学和哲学的一个分支,研究推理的原则。它涉及正确推理的规则和方法,如对偶论、归纳法和演绎法。逻辑学关注的是确保论证是有效的、一致的、没有矛盾的。虽然推理是一个自然和直观的过程,但逻辑提供了一个系统和正式的推理方法,可以帮助避免错误并提高决策质量。
作者表示,ChatGPT在逻辑推理和上下文理解方面似乎有局限性,导致它在处理那些容易被人类回答的问题时很吃力。使用特定的的 "神奇 "短语,如在CoT中用的很多的"让我们一步一步地思考",有时可以提高答案的质量。
3. 数学和算数
算术推理是指利用数学概念和逻辑来解决算术问题的能力。ChatGPT在计算数学表达式方面的能力有限。像大多数大型语言模型一样,它在处理诸如大数相乘、寻根、计算幂以及无理数的加减法等任务时很困难。具体测试可参见Frieder的文章:Mathematical capabilities of chatgpt。
4. 事实错误

上图展示了吴恩达测试的到的一个关于深度学习计算的事实错误,事实错误指的是信息或声明中的不准确,与现实或真相不符之处。ChatGPT的输出在科学事实方面缺乏准确性。这些信息有时候可能看起来很可信,但是却与简单的谷歌搜索矛盾。由于这些程序根据统计模式生成图像和文本,而不是获得对世界的真正理解,而且它们容易捏造事实,重复可憎和有偏见的言论例如。
5. 偏见和歧视
人工智能的偏见指的是生成的语言输出中的系统性不准确或刻板印象,它受到训练数据中的社会和文化偏见。这其中的典型案例是2016的微软聊天机器人,对此ChatGPT进行了针对性改进,适用人类注释来消除偏见,但是却因为给注释工人工资太低和心理伤害引入了争议。
一个典型的案例是询问一个人是否是会成为好的科学家,以前的ChatGPT会倾向于白人男性,现在则保持中立,这表明ChatGPT正在努力减少语言模型中的偏见。
6. 诙谐幽默
幽默是一种有趣或滑稽的品质,其含义可以因文化背景和个人品味的不同而大相径庭,通常涉及到使用幽默技巧,如双关语、文字游戏和荒诞性,以唤起观众的反应,因为期复杂性对AI是一个重大挑战。
作者通过整理的一些资料和失败案例,表示ChatGPT对幽默有一定程度的理解,一些例子诸如:
但是对此他的标准回答是,"作为一个人工智能语言模型,我没有能力体验情感或主观经验,如幽默感。我可以生成意在幽默或旨在让人发笑的文本,但我没有能力实际体验幽默或享受生成意在搞笑的文本的过程。我的目标是提供相关的和准确的信息,或者生成与我从训练的数据中了解到的模式相一致的文本。"。
7. 编程
ChatGPT它有编写代码的能力,但它不能完全替代人类开发者,它只能协助完成一些任务,如生成通用函数或重复性代码,但对程序员的需求将持续存在。
8. 句法结构、拼写和语法
句法结构和语法指的是根据特定语言的规则,形成一个明确的、有意义的语言结构,是语言学的核心问题之一。
ChatGPT在语言理解方面表现出色,但偶尔还是会犯错。例如,当向ChatGPT提出这个问题时,"在'Jon想成为一名吉他手,因为他认为这是一种美丽的乐器'这个句子中,'它'指的是什么?",它回答 "代词'它'指的是'一种美丽的乐器'"。当要求构建一个第四个词以'y'开头的句子时,ChatGPT未能产生有效的回答。
9. 自我意识

自我意识是指认识到自己是一个独立于他人的个体,并对自己的思想、情感、个性和身份有意识的能力。
ChatGPT不知道自己架构的细节,包括其模型的层次和参数。这种不了解可能是OpenAI故意施加的,以保护模型的信息。另外如果询问他是否有自我意识,他会回答否。尽管如此,如上图所示,ChatGPT还是提出了确定语言模型是否具有自我意识的方法。
10. 其他
-
ChatGPT难以使用成语,通过其短语的使用暴露了其非人类的身份。
-
由于ChatGPT缺乏真实的情感和思想,它无法像人类那样创造出能与人们产生情感共鸣的内容。
-
ChatGPT浓缩了主题,但没有对其提供一个独特的视角。
-
ChatGPT倾向于过于全面和冗长,从多个角度切入一个话题,这可能导致在需要直接回答时出现不恰当的答案,不过这种过度详细的性质被OpenAI认为是一种限制。
-
ChatGPT缺乏类似人类的分歧,并且倾向于过度的字面意思,在某些情况下会导致失误。例如,它的回答通常严格限制在所问的问题上,而人类的回答往往会发散并转移到其他主题。
-
ChatGPT努力保持中立的立场,而人类在表达意见时往往会偏袒一方。
-
ChatGPT的回答往往是正式的,因为它的编程避免了非正式语言。相比之下,人类在回答时倾向于使用更随意和熟悉的表达方式。
-
如果ChatGPT被告知其答案不正确,它会通过道歉、承认其潜在的不准确或混乱、纠正其答案或保持其原始反应来回应。
结论
1. ChatGPT拥有常识的程度和获得常识的方法都不确定。
2. ChatGPT在多大程度上记忆与理解他们产生的东西,完全捕捉人类的思想,仍然是未知的。
3. ChatGPT没有办法评估它的答案的不确定性。有时,它可能会因为太过自信而给出不正确的答案。有必要进一步改进,以帮助ChatGPT表明其回答的自信程度。
4. 后续研究必须考虑到使用这些模型的道德和社会后果,如工作转移以及偏见和操纵的风险。此外,必须探讨ChatGPT被用于传播错误信息、宣传或用于身份盗窃等有害目的的可能性。
5. ChatGPT这类语言模型有可能被有效地利用于小样本、零样本学习。
6. 本文概述的失败案例集可以作为创建典型问题综合数据集的基础,以评估未来的语言模型和ChatGPT迭代。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢