
Scaling Vision Transformers to 22 Billion Parameters
M Dehghani, J Djolonga, B Mustafa, P Padlewski, J Heek, J Gilmer, A Steiner…
[Google Research]
将视觉Transformer扩展到22B参数
要点:
-
提出一种高效、稳定地训练 22B 参数 ViT 的方法,也是迄今为止最大的稠密 ViT 模型; -
产生的模型显示了随着规模扩大而不断提高的性能,并在几个基准上取得了最先进的结果; -
当涉及到形状和纹理偏差时,ViT-22B 与人类感知更一致,并在公平性和鲁棒性方面显示出收益; -
该模型可作为蒸馏目标训练一个较小的学生模型,在该规模上达到最先进的性能。
一句话总结:
提出一种高效稳定地训练 22B 参数 ViT(ViT-22B)模型的方法,也是迄今为止最大的稠密 ViT 模型。产生的模型在各种下游任务上进行了评估,显示出随规模扩大,性能也在不断提高,在公平性和性能之间的权衡,与人类视觉感知的一致性,以及鲁棒性。
论文:https://arxiv.org/abs/2302.05442
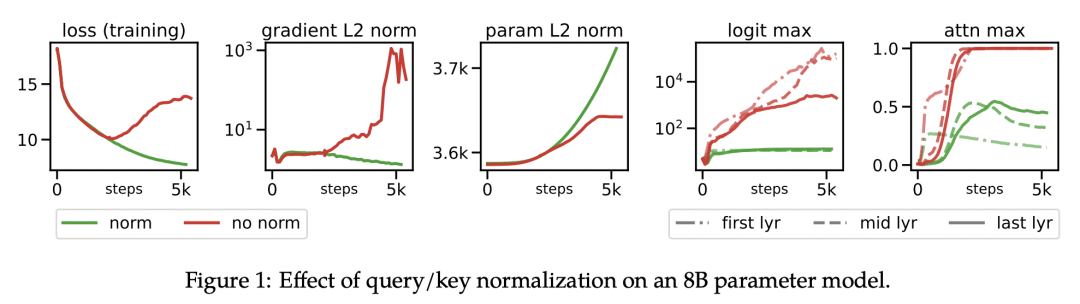
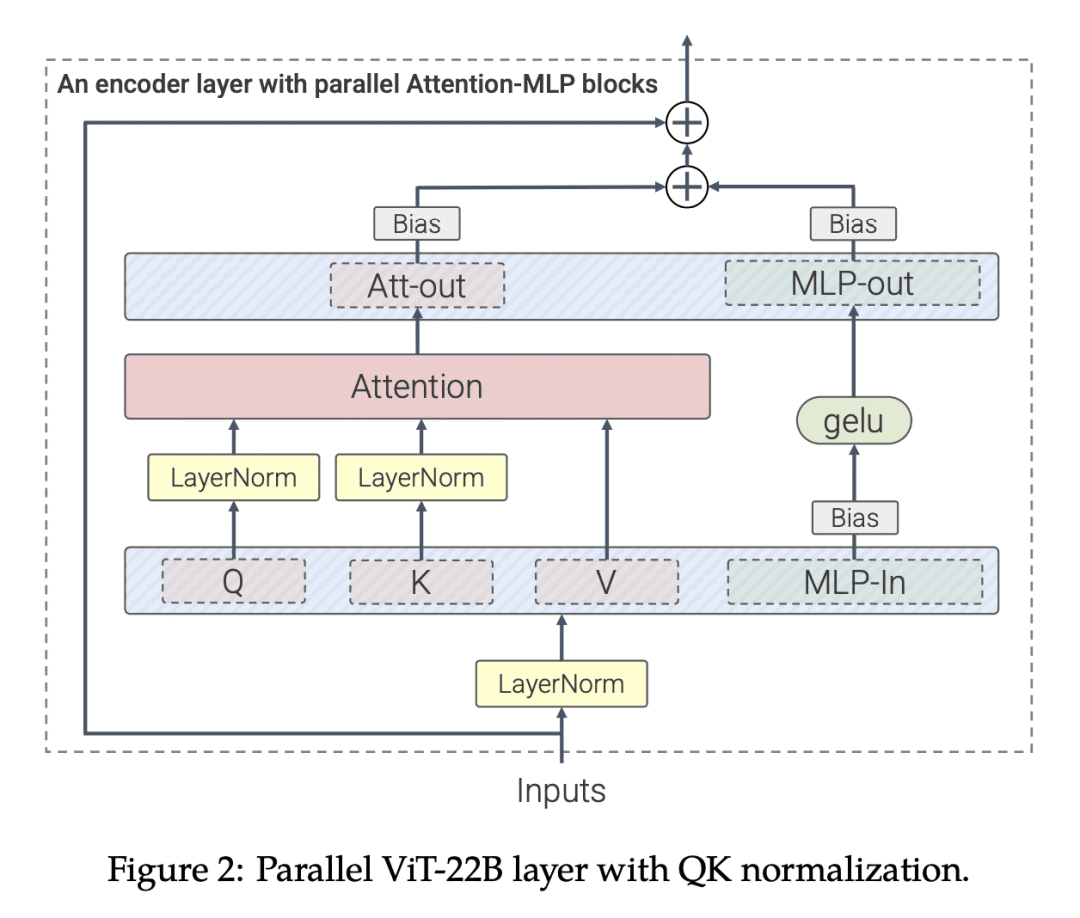
The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢