
来自今天的爱可可AI前沿推介
[CL] The Wisdom of Hindsight Makes Language Models Better Instruction Followers
T Zhang, F Liu, J Wong, P Abbeel, J E. Gonzalez
[UC Berkeley]
明智的事后标记让语言模型成为更好的指令执行器
要点:
-
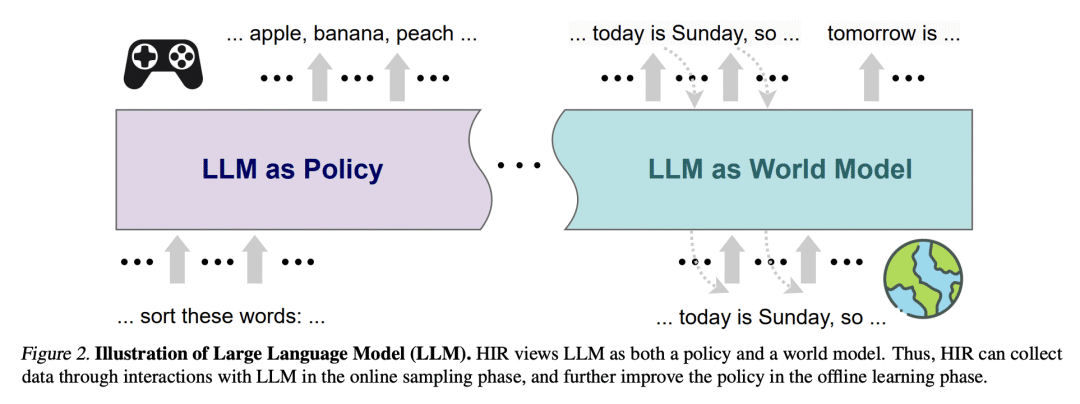
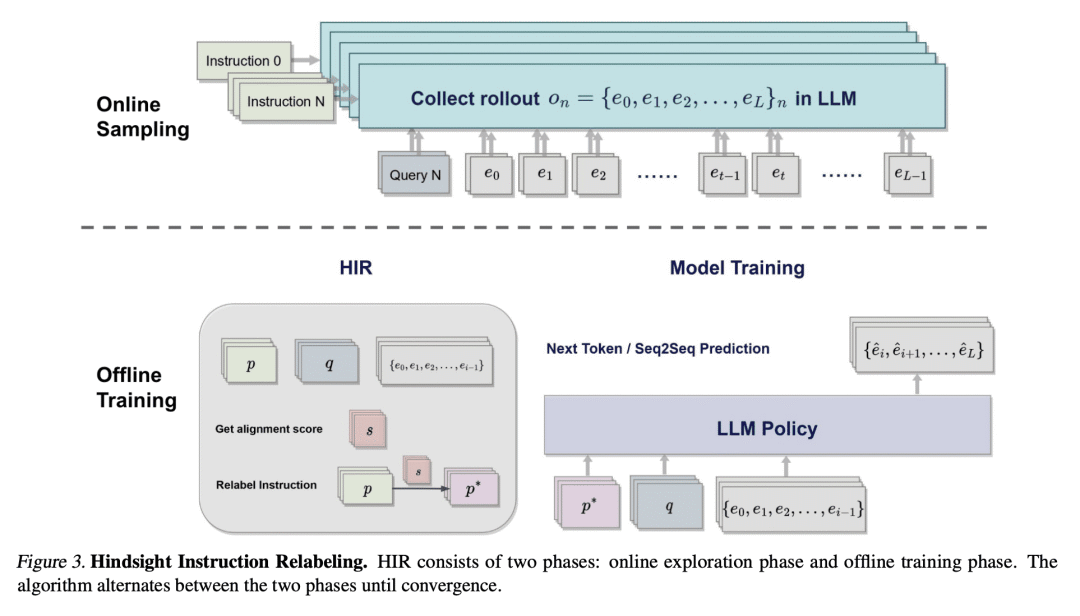
HIR 是一种新算法,将指令对齐和目标条件强化学习联系起来,产生了一种简单的两阶段事后重标记算法; -
HIR 利用成功数据和失败数据来有效地训练语言模型,不需要任何额外的训练管道,使其更具加数据高效; -
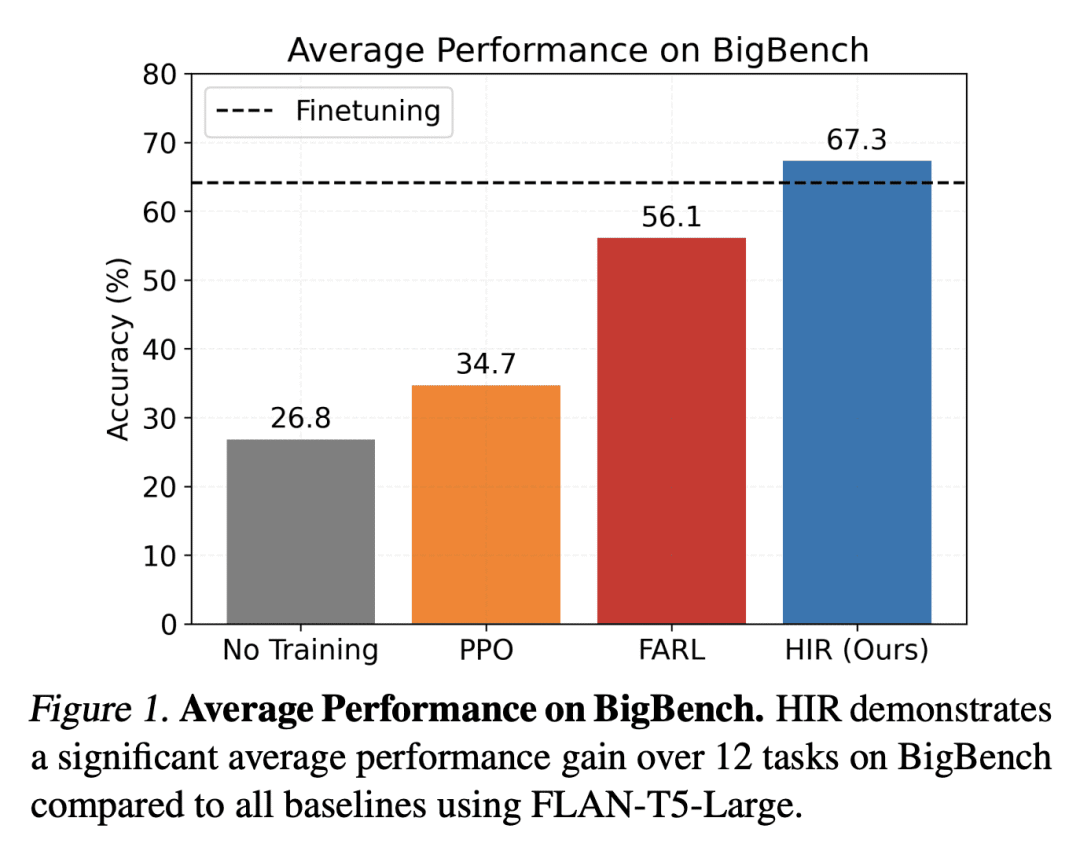
在12个具有挑战性的 BigBench 推理任务上,HIR 明显优于基线算法,与有监督微调(SFT)相当; -
HIR 为通过事后指示重标记从反馈中学习提供了一种新视角,可启发未来研究,即设计更高效和可扩展的算法通过人工反馈训练语言模型。
一句话总结:
提出了一种新算法——事后指令重标记(HIR),改善了语言模型与指令的一致性。HIR 在 BigBench 推理任务上取得了令人印象深刻的结果,是第一个将事后重标记应用于语言模型的算法。
Reinforcement learning has seen wide success in finetuning large language models to better align with instructions via human feedback. The so-called algorithm, Reinforcement Learning with Human Feedback (RLHF) demonstrates impressive performance on the GPT series models. However, the underlying Reinforcement Learning (RL) algorithm is complex and requires an additional training pipeline for reward and value networks. In this paper, we consider an alternative approach: converting feedback to instruction by relabeling the original one and training the model for better alignment in a supervised manner. Such an algorithm doesn't require any additional parameters except for the original language model and maximally reuses the pretraining pipeline. To achieve this, we formulate instruction alignment problem for language models as a goal-reaching problem in decision making. We propose Hindsight Instruction Relabeling (HIR), a novel algorithm for aligning language models with instructions. The resulting two-stage algorithm shed light to a family of reward-free approaches that utilize the hindsightly relabeled instructions based on feedback. We evaluate the performance of HIR extensively on 12 challenging BigBench reasoning tasks and show that HIR outperforms the baseline algorithms and is comparable to or even surpasses supervised finetuning.
论文链接:https://arxiv.org/abs/2302.05206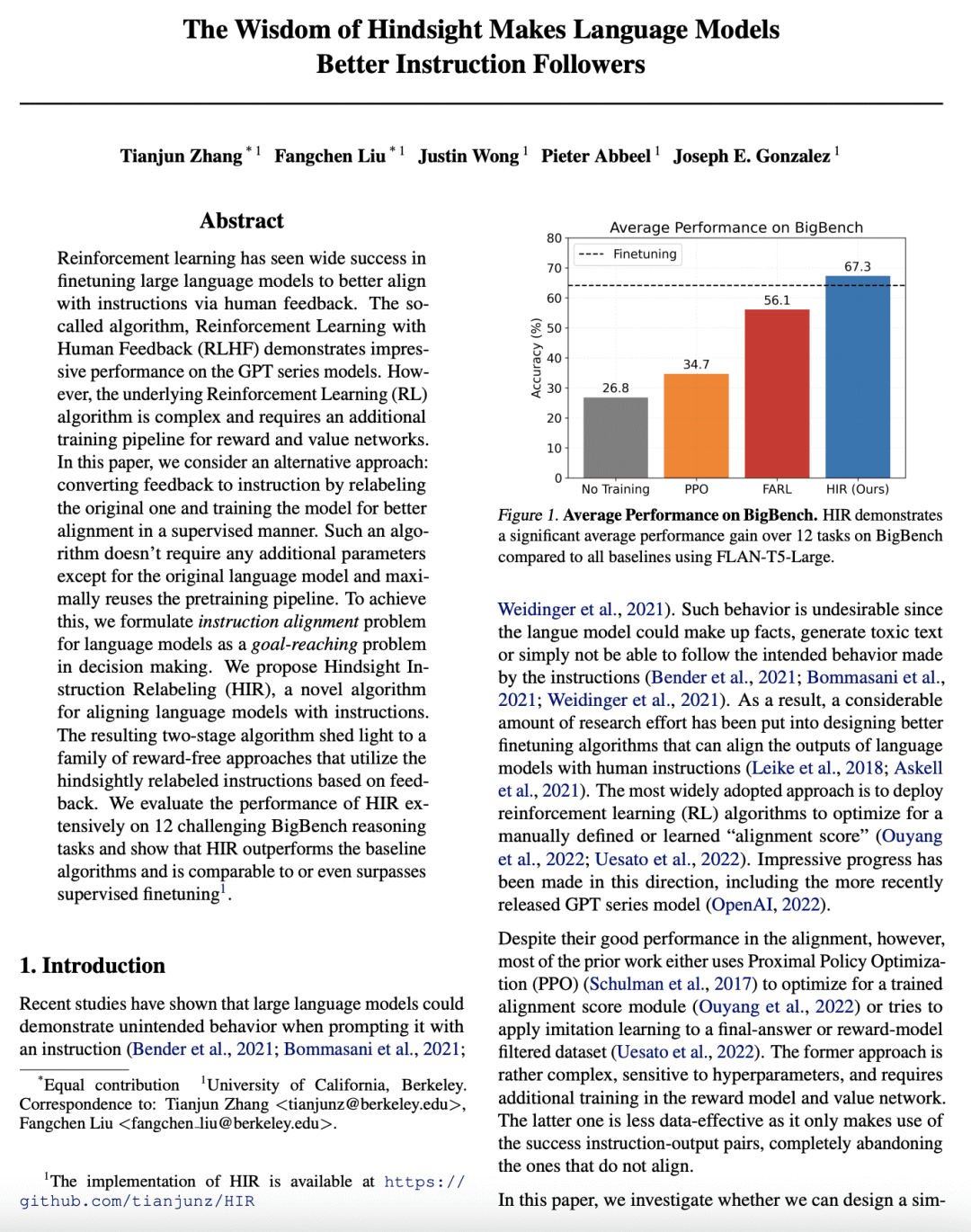
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢