
Single Motion Diffusion
S Raab, I Leibovitch, G Tevet, M Arar, A H. Bermano, D Cohen-Or
[Tel-Aviv University]
单运动扩散模型
要点:
-
单运动扩散模型(SinMDM)是一个旨在学习单个运动序列的内部模式并合成忠实于它的任意长度运动的模型,在可用数据实例有限的领域特别有用; -
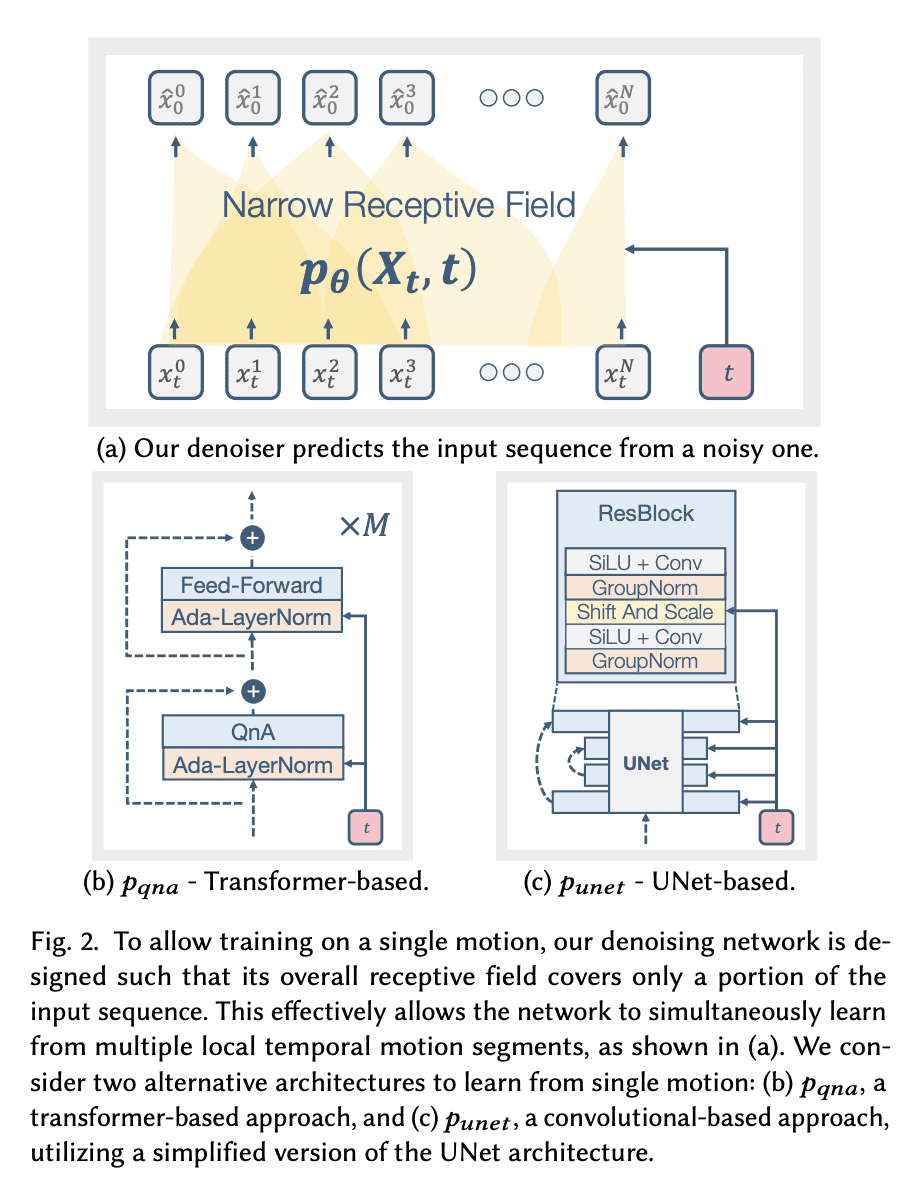
使用扩散模型和专门为从单一输入运动中学习的任务而设计的去噪网络,其基于 Transformer 的架构可避免过拟合并鼓励运动多样性; -
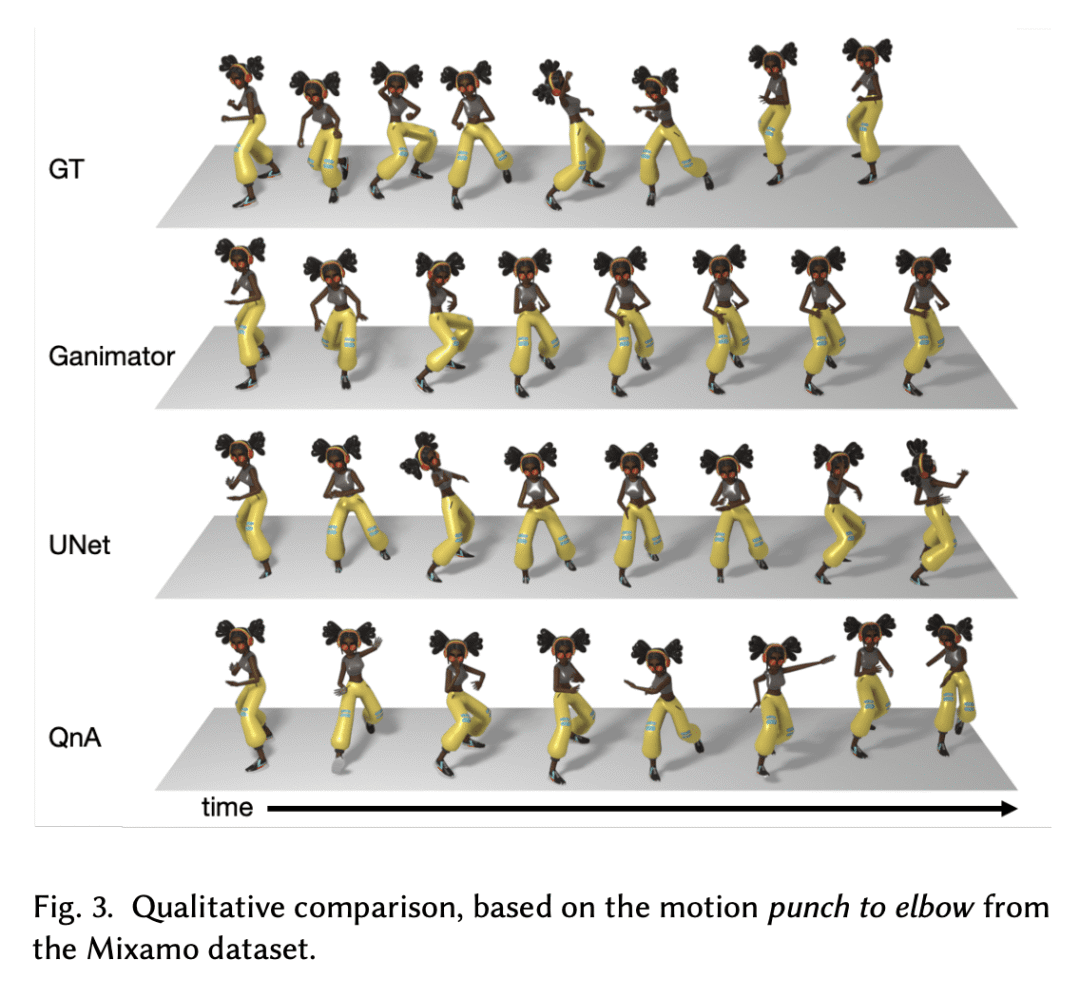
SinMDM 可用于各种情况,包括空间和时间上的夹杂、运动扩展、风格迁移和人群动画,并且在质量和时空效率上都优于现有方法。 -
该模型的先天局限性,是所有学习单个实例模型所共有的,即合成分布外的能力有限,而基于扩散的方法的主要局限是推理时间相对较长。
一句话总结:
单运动扩散模型(SinMDM)利用扩散模型和去噪网络,以有限数据合成生物的逼真动画,性能优于现有方法,并能完成各种运动操作任务。
论文地址:https://arxiv.org/abs/2302.05905
Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at this https URL.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢