
来自今天的爱可可AI前沿推介
[LG] Cross-Modal Fine-Tuning: Align then Refine
J Shen, L Li, L M. Dery, C Staten, M Khodak, G Neubig, A Talwalkar
[CMU & Hewlett Packard Enterprise]
跨模态微调:先对齐再细化
要点:
-
预训练模型的微调已经在视觉和NLP中取得了进展,但在许多其他模态中却没有; -
ORCA 是一个跨模态微调框架,将最终任务数据与模型的预训练模态相匹配; -
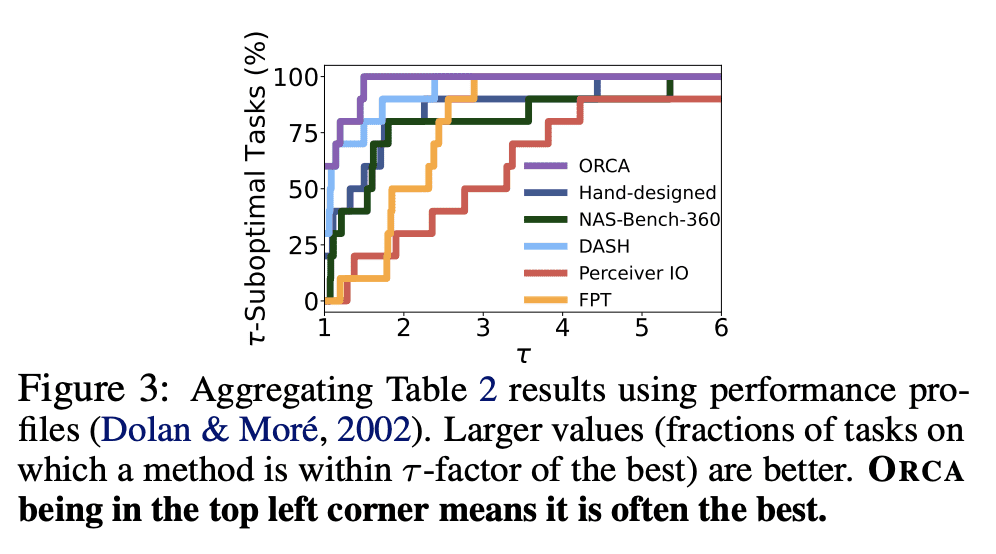
ORCA 在12种模态的60多个数据集的3个基准上的表现,优于手工设计的、AutoML的、通用的和特定任务的方法; -
ORCA 的有效性在广度、深度和与现有工作的比较上得到了验证。
一句话总结:
提出ORCA,一种跨模态微调框架,将任意模态的最终任务数据与模型的预训练模态对齐,以提高微调性能。
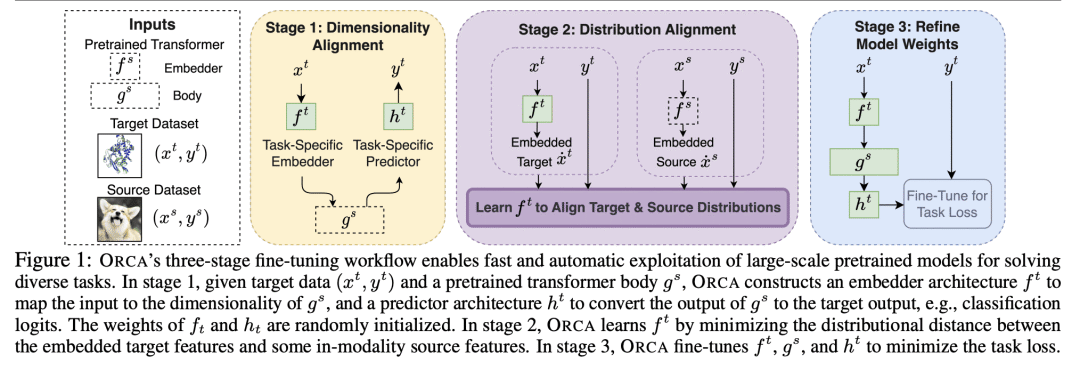
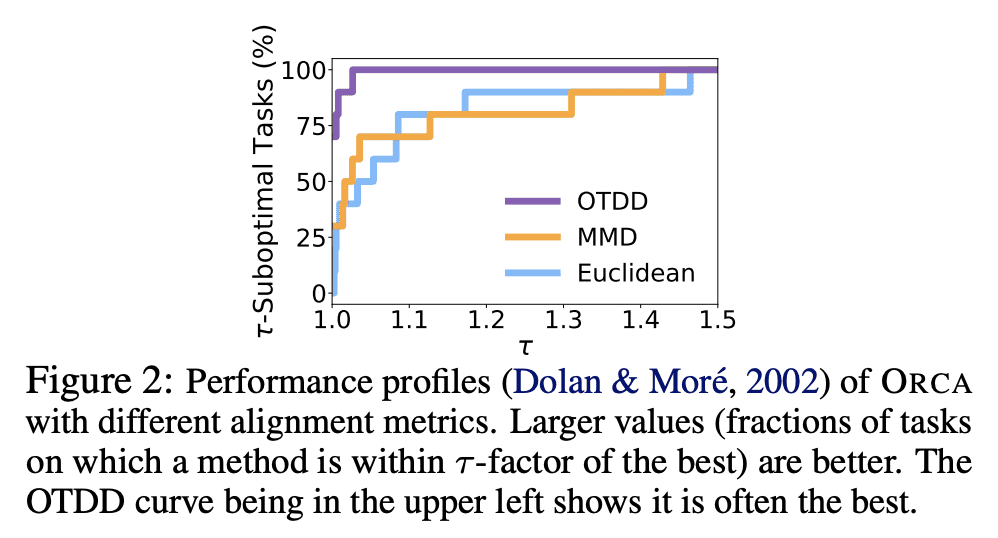
Fine-tuning large-scale pretrained models has led to tremendous progress in well-studied modalities such as vision and NLP. However, similar gains have not been observed in many other modalities due to a lack of relevant pretrained models. In this work, we propose ORCA, a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. Through extensive experiments, we show that ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities, outperforming a wide range of hand-designed, AutoML, general-purpose, and task-specific methods. We highlight the importance of data alignment via a series of ablation studies and demonstrate ORCA's utility in data-limited regimes.
论文链接:https://arxiv.org/abs/2302.05738
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢