
作者:杨靖锋,现任亚马逊科学家,本科毕业于北大,硕士毕业于佐治亚理工学院,师从 Stanford 杨笛一教授。杨昊桐译,王骁修订,感谢靳弘业对第一版稿件的建议,感谢陈三星,符尧的讨论和建议。
原文:https://jingfengyang.github.io/gpt
推特:https://twitter.com/JingfengY/status/1625003999387881472
智源回放地址:
https://event.baai.ac.cn/activities/654
PPT下载地址:
https://event-cdn.baai.ac.cn/file/file-browser/WAEd5nENGH6SMmRiPhxtkatjBBmBH8jK.pdf
在这篇文章中,在一堆论文中仔细检查了细节后,我会写下一些摘要和我自己对上述两个问题的想法,包括GPT-3、PaLM、BLOOM、OPT、FLAN-T5/PaLM、HELM等。如果有人有更实际的经验或其他更可靠的参考资料,请随时纠正我。
对于那些想要复制自己的GPT-3/GhatGPT的人来说,第一个问题是一个关键问题。第二个问题对于那些想使用GPT-3/ChatGPT的人来说很重要。(当我说GPT-3时,它主要指的是GPT-3.5/Instruct GPT的最新版本,除了一些案例指的是原始的GPT3论文)。

为什么所有公开复制GPT-3都失败了?
在这里,我把“失败”定义为与原始GPT-3论文中报告的性能不匹配,型号尺寸相似甚至更大。根据这一标准,GPT-3和PaLM(540B)是成功的,但这两个模型都不是公开的,而所有公共模型(例如OPT-175B和BLOOM-176B)在某种程度上是“失败”。但是,我们仍然可以从这样的“失败”中吸取许多教训。请注意,如果我们多次尝试不同的设置,公共社区最终可能会复制GPT-3。但到目前为止,费用仍然太高,无法训练另一个版本的OPT-175B。因为训练这样一个大型型号的一次通行证需要在~1000 80G A100 GPU上运行至少2个月。
尽管OPT-175B和GLM-130B等一些论文声称,它们在某些任务中匹配甚至优于原始的GPT-3,但在GPT-3评估的更广泛的任务中,它仍然值得怀疑。此外,根据大多数用户在更广泛的任务和HELM评估方面的经验,最近的OpenAI GPT3 API结果仍然比这些开源模型好得多。虽然底层模型可能会使用指令调优(InstructGPT),但OPT(OPT-IML)和BLOOM(BLOOMZ)的类似指令调优版本仍然比InstructGPT和FLAN-PaLM(指令调优PaLM)差得多。
根据论文细节,与成功的GPT-3和PaLM相比,OPT-175B和BLOOM-176B失败有多种可能的原因。我把它们分为两部分:训练前数据和训练策略。
训练前数据
让我们先看看GPT-3如何准备和使用训练前数据。GPT-3在300B令牌上进行训练,其中60%来自过滤的Common Crawl,其他组件包括webtext2(训练GPT2的语料库)、Books1、Books2和Wikipidia。GPT-3的后续版本也接受了代码数据训练(例如Github代码)。每个部分的部分与原始数据集大小不成正比。相反,更频繁地对高质量数据进行采样。有三个谜团可能会使开源社区难以收集类似的数据,导致OPT-175B和BLOOM-176B的“失败”:
- 第一个是性能良好的分类器,用于过滤低质量数据,用于构建GPT-3和PaLM的预训练语料库。但此步骤不是由OPT或BLOOM进行的。一些论文表明,对数据质量较低的模型进行预训练可能会优于数据质量参差得多的模型。但正如第三点所述,数据多样性也非常重要。因此,人们应该非常小心数据多样性和质量之间的权衡。
- 第二个是预训练数据重复数据删除。重复数据删除可以防止预训练的模型多次看到相同的数据点,并过度拟合/记忆它们,从而使其更好地概括。GPT-3和PaLM进行了文档级重复数据删除,OPT也使用。但正如OPT论文所示,OPT在这一步骤后使用的堆语料库中仍然存在许多重复,这可能会导致其性能不佳。
- 第三是训练前数据多样性。这包括领域多样性、形式多样性(例如文本、代码、表格)和语言多样性。OPT-175B使用的堆语料库声称具有更好的多样性,但BLOOM使用的ROOTS语料库有太多的学术数据集,这缺乏Common Crawl数据的多样性,并可能导致BLOOM的性能不佳。相比之下,GPT3来自Common Crawl的多样化和通用域数据比例要高得多,这可能也是GPT-3是导致通用公认的聊天机器人ChatGPT的第一个基本模型的原因之一。
- 注意:虽然不同的数据通常对训练通用LLM很重要,但特定的预训练数据分发实际上对LLM在特定下游任务上的性能有很大影响。例如,BLOOM和PaLM拥有更多的多语言数据,从而在一些多语言任务和机器翻译中具有更好的性能。OPT有许多对话预置数据(例如reddit),这可能会导致其在对话中的良好表现。PaLM有很大一部分社交媒体对话,这可能会导致其在各种问答任务和数据集上的出色表现。此外,PaLM和更高版本的GPT-3拥有很大一部分代码数据,这增加了它们编码任务的能力,可能还有思想链(CoT)能力。一个有趣的现象是,尽管BLOOM在预训练期间使用了代码数据,但其编码和CoT能力仍然很差,这可能表明仅编码数据无法保证模型的编码和CoT能力。
总之,一些论文表明了上述三点的重要性,即重复数据删除以避免记忆/过度拟合,数据过滤以获得更高质量的数据,以及数据多样性以确保LLM的可推广性。但不幸的是,PaLM和GPT-3如何预处理数据或原始训练前数据的细节尚未披露,这使得公共社区难以复制它们。
训练策略
在这里,训练策略包括训练框架、训练持续时间、模型架构/训练设置、训练过程中的修改,以便在训练非常大的模型时提高稳定性和收敛性。一般来说,在训练前过程中,损失峰值和差异在原因不明的情况下被广泛观察到,因此建议对训练设置和模型架构进行许多修改来缓解这种情况。但OPT和BLOOM中的一些不是最佳解决方案,这可能会导致它们表现不佳。GPT-3没有明确提到他们是如何解决这个问题的。
- 训练框架:大于175B的模型通常需要ZeRO模式数据并行(分布式优化器)和模型并行(包括张量并行、管道并行,有时需要序列并行)。OPT使用ZeRO的FSDP实现和Megatron-LM模型并行实现。BLOOM使用ZeRO的Deepspeed实现和Megatron-LM模型并行实现。PaLM使用Pathways,这是一个基于TPU的模型并行和数据并行系统。GPT-3训练系统的细节仍然未知,但他们至少以某种方式使用平行模型(有些人说它使用Ray)。不同的训练系统和硬件实际上会导致训练期间的一些不同现象。显然,PaLM论文中包含的一些TPU训练设置可能不适合所有其他型号的GPU训练。硬件和训练框架的一个重要含义是,人们是否可以使用bfloat16来存储模型权重、激活等。这已被证明是稳定训练的一个非常重要的因素,因为bfloat16可以代表更大的浮动数字范围,在训练损失峰值期间处理大值。在TPU中,bfloat16是默认选项,这可能是PaLM成功的一个秘密。但在GPU中,人们以前主要使用float16,这是V100混合精度训练的唯一选择。OPT使用float16,这可能是其不稳定的一个因素。BLOOM发现了这个问题,并最终在A100 GPU上使用了bfloat16,但它没有意识到这种设置的重要性,因此在第一次嵌入后应用了额外的层归一化,这用于解决使用float16的初步实验中的不稳定性。然而,这种层归一化已被证明会导致更糟糕的零点推广,这可能是BLOOM失败的一个因素。
- 训练过程中的修改:OPT从最近的检查站进行了大量飞行中调整并重新启动了训练,包括更改剪辑梯度规范和学习率,切换到香草SGD,然后切换回亚当,重置动态损失标量,切换到较新版本的Megatron。这种飞行中调整可能是OPT失败的原因之一。相比之下,PaLM几乎没有做任何飞行中调。在峰值开始前大约100步,它刚刚从检查站重新开始训练,并跳过了大约200-500个数据批次。这种简单的重新启动可以在PaLM中神奇地成功,因为它的Bitwise决定性,即在训练前数据构建期间完成采样,并且由于对模型架构和训练设置进行了许多修改,以提高稳定性。PaLM中的此类修改将在下一点显示。
- 模型架构/训练设置:为了使训练更加稳定,PaLM对模型架构和训练设置进行了几次调整,包括使用修改后的Adafactor作为优化器,缩放前softmax输出日志,使用辅助损失来鼓励softmax归一化器接近0,对内核权重和嵌入使用不同的初始化,在密集内核和布局规范中没有偏见,以及在预交易期间不使用辍学。请注意,GLM-130B中还有更多关于如何稳定训练非常大型模型的宝贵课程,例如使用基于DeepNorm的Post-LN而不是Pre-LN,以及嵌入层梯度收缩。大多数模型修改没有在OPT和BLOOM中采用,这可能会导致它们的不稳定和失败。
- 训练持续时间:如下表所示,原始GPT3预训练流程看到的令牌数量与OPT和BLOOM相似,而PaLM在预训练期间看到的代币要多得多。此外,PaLM和GPT3预训练语料都比BLOOM和OPT预训练语料库大。因此,用更大的高质量语料库预先交易更多代币可能是GPT3和PaLM成功的一个重要因素。
| 预训练语料库代币 | 训练前看到的代币 | |
|---|---|---|
| 手掌 | 780B | 770B |
| GPT3 | 500B | 300B |
| 选择 | 180B | 300B |
| 花 | 380B | 336B |
还有一些其他因素,这些因素对稳定的训练可能不那么重要,但仍然可能影响最终的表现。首先,PaLM和GPT-3在训练过程中都逐渐增加(从小到大)批次大小,这已被证明可以有效地训练更好的LLM,而OPT和BLOOM使用恒定的批次大小。其次,OPT使用ReLU激活,而PaLM使用SwiGLU激活,GPT-3/BLOOM使用GeLU激活,这通常会导致更好的训练LLM。最后,为了更好地建模更长的序列,PaLM使用RoPE嵌入,BLOOM使用ALiBi嵌入,而原始的GPT-3和OPT使用学习的位置嵌入,这可能会影响长序列的性能。
在哪些任务中,我们应该使用GPT-3.5/ChatGPT?
为了解释我们应该或不应该使用GPT-3的任务/应用程序,我主要将提示GPT-3与微调较小的模型(有时是专门设计)进行比较,看看GPT-3是否适合特定任务。鉴于最近更小且可调谐型号FLAN-T5的良好性能,这一点更加重要。在理想情况下,如果微调GPT-3是负担得起的,它可能会导致进一步的改进。然而,在某些任务上微调PaLM-540B所表明的有限改进使人们怀疑它是否应该在某些任务中微调GPT-3。从科学的角度来看,将微调GPT-3与提示GPT3进行比较更公平。然而,要使用GPT3,人们可能更关心将微调较小的模型与提示GPT3进行比较。请注意,我主要关心准确性作为指标,但在决定是否使用GPT3时,还应该考虑许多其他重要维度(例如毒性、公平性等),如HELM论文所示。下图总结了粗略的决策流程。希望这能作为一个有用的实用指南,无论是现有任务还是新任务。
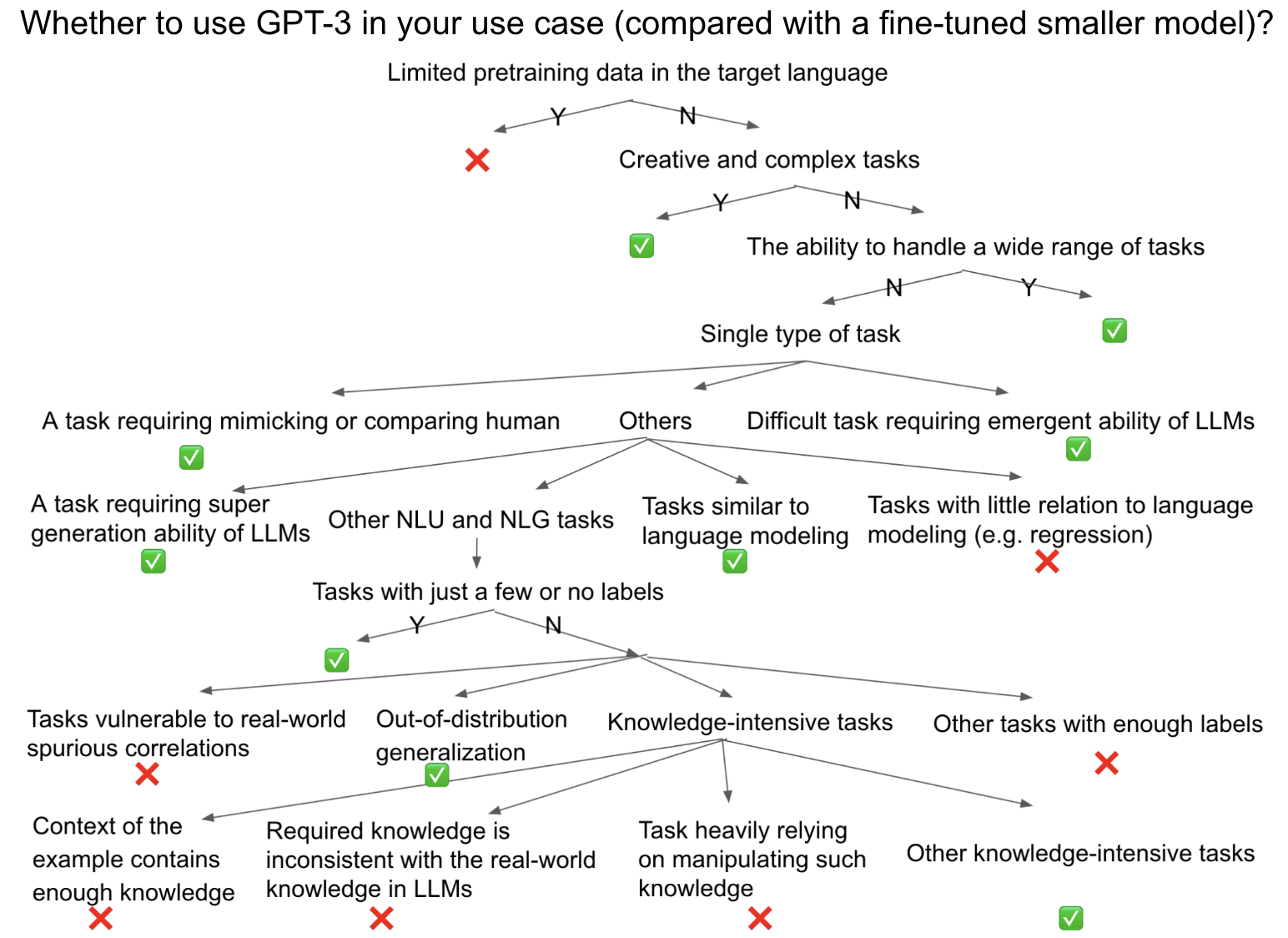
- 注1:由于其在对话设置中保持一致性好,ChatGPT作为聊天机器人表现良好。但我们通常会使用GPT-3 / InstructGPT(GPT-3.5)/Codex基础ChatGPT作为更多任务和用例的一般模型。
- 注2:本节的结论基于当前模型的一些发现,这些发现可能不适合将来更强大的模型。由于有更多与目标数据集相似的训练前数据,学术数据集指令调优(例如,提示FLAN-PaLM可能会提供更强的性能,这尚未公开),或RLHF可以更好地与目标任务保持一致,因此模型在目标任务中可能更好,甚至有时会牺牲其他环境中的某些能力(例如InstructGPT的对齐税)。在这种情况下,很难看出GPT是在做泛化、交叉任务概括,还是只是在训练前记住了测试数据点,还是在训练前看到了那些所谓的“看不见”任务。然而,记忆在实践中是否真的是一个严重问题仍然值得怀疑,因为与研究人员不同,如果用户发现GPT在测试数据上已经表现良好,他们可能不在乎GPT在训练前是否看到了相同或相似的数据。无论如何,为了最大限度地提高本节在当前世界的实际价值,我试图比较微调公共小型模型(T5、FALN-T5、一些带有特殊设计的微调SOTA等)的最佳性能和最近GPT-3(GPT-3.5/InstructGPT)/PaLM(或FLAN-PaLM)的最佳性能(如果有的话)。
一般来说,在一些情况下,应该更好地使用GPT-3(如果我们回顾GPT3论文的引入,那就太神奇了,其中许多最初的设计目标涵盖了这些任务,这意味着这些模棱两可的目标已经部分实现):
- 创意和复杂的任务,包括编码(代码完成、代码的自然语言说明、代码翻译、错误修复)、总结、翻译、创意写作(例如写作故事、文章、电子邮件、报告、写作改进等)等。正如原始的GPT3论文所示,GPT3是为那些困难/“无法标记”的任务设计的。在某种程度上,这些任务不可能在之前微调模型的现实世界应用程序中使用,而GPT3使它们成为可能。例如,最近的论文表明,之前的人类标记总结已被LLM生成的总结所超越。提示PaLM 540B甚至可以在某些机器翻译任务中超过微调模型,这需要从低/中资源语言翻译成英语。在BLOOM-176B中也观察到类似的方式。这是因为英语数据通常在训练前语料库中占很大比例,因此法学硕士擅长生成英语句子。请注意,为了在编码任务中获得良好的性能,尽管Codex/PaLM的总体性能比以前的型号好得多,但我们仍然应该允许LLM采样多次(k)次才能通过测试用例(使用pass@k作为指标)。
- 任务只有几个标签或没有标签。如原始的GPT3所示,GPT3专为那些“标签昂贵”的任务而设计。在这种情况下,微调较小的模型通常无法匹配GPT3的零/一/几发性能。
- 分布外(OOD)泛化。鉴于一些训练数据,传统的微调可能过于适合训练集,并且OOD可推广性差,而少量的上下文学习可以具有更好的分布外概括性。例如,提示PaLM在对抗性自然语言推理(ANLI)上的表现可能优于微调SOTA,而在正常NLI(RTE数据集)上仍然表现不佳微调SOTA。另一个例子是,提示LLM比微调模型在成分上表现出更好的OD推广。OOD可推广性更好,要么是因为在上下文学习期间不需要更新参数,避免过度拟合,要么是因为之前的OOD示例是LLM的分布式示例。这个用例是GPT3的初始设计目标之一:“微调模型在特定基准上的性能,即使名义上是人类层面的,也可能夸大基础任务的实际性能,因为训练数据中的虚假相关性,以及模型过度拟合到狭窄分布。”
- 处理各种任务的能力,而不仅仅是专注于特定任务的卓越性能。Chatbot就是这种情况之一,用户希望机器人正确响应各种任务。这可能就是为什么ChatGPT是GPT3最成功的用例之一。
- 无法检索的知识密集型任务。存储在LLM中的知识可以极大地帮助提高知识密集型任务的性能,如封闭式问题解答和MMLU(一个基准数据集,包括来自STEM、人文学科、社会科学等57个科目的多项选择题,测试LLM的世界知识和解决问题的能力)。但是,如果可以添加检索步骤(检索增强生成),则微调较小的模型(例如Atlas模型)甚至可以具有更好的性能(Atlas在封闭式书籍NaturalQuestions和TrivialQA数据集中都优于PaLM和最新的InstructGPT)。在将GPT-3/ChatGPT集成到搜索引擎时,检索/传统搜索也是必要的步骤,这可以提高生成准确性,并提供更多参考来提高说服力。但我们应该承认,在某些情况下,检索是不允许或不容易的,比如参加USMLE(美国医疗许可考试)测试,谷歌已经表明,基于FLAN-PaLM的方法可以做得很好。此外,在MMLU基准测试中,PaLM-540B的性能比任何微调型号都好,即使结合了检索,尽管最新版本的InstructGPT仍然比带有检索步骤的微调SOTA更糟糕。请注意,较小的模型的指令调谐也可以实现与缩放到LLM类似的效果,FLAN-T5已经表明了这一点。
- 一些需要LLM紧急能力的困难任务,如与CoT进行推理和BIG-Bench中的复杂任务(包括逻辑推理、翻译、问题回答、数学任务)。例如,PaLM表明,在包括算术和常识推理在内的7个多步骤推理任务中,8发CoT在4个任务上优于微调SOTA,并且可以在剩余的3个任务中几乎匹配fintuned-SOTA。这种成功来自缩放和CoT。PaLM还显示了从8B到62B到540B模型的BIG-B台任务的不连续改进,这超出了缩放定律,被称为LLM的紧急能力。在Big-Bench的58项常见任务中,有44项,5发提示PaLM-540B的表现优于之前(几发)SOTA。PaLM-540B的总表现也优于人类的平均表现。
- 一些需要模仿人类的场景,或者其目标是制作具有人类水平表现的AGI。同样,Chatbot就是这种情况之一,ChatGPT使自己更像人类,从而取得了非凡的成功。这是GPT3的初始设计目标之一:“人类不需要大型受监督的数据集来学习大多数语言任务。人类最多可以通过几个例子无缝地混合或切换许多任务和技能。因此,传统的微调方法导致与人类的不公平比较,尽管他们在许多基准数据集中声称具有人类水平的性能。”
- 在一些类似于语言建模的传统NLP任务上,很少有弹弓的PaLM 540B大致匹配甚至超过微调的SOTA,例如结束句子/单词关闭和anaphora分辨率。但是,在这种情况下,零发LLM就足够了,而一/几个镜头的例子通常帮助较小。
还有几种情况下,不需要提示GPT-3尺寸的型号:
- 调用OpenAI GPT3 API超出了预算(例如,对于没有太多钱的新初创公司)。
- 调用OpenAI GPT3 API可能会引发一些安全问题(例如,数据泄露给OpenAI,或可能生成有害内容)。
- 没有足够的工程或硬件资源来托管类似尺寸的模型,并消除推断延迟问题。例如,如果没有最先进的80G A100或工程资源来优化推理速度,在16个40G A100 GPU上天真地使用Alpa托管A100需要10秒才能完成单实例推理,这对大多数现实世界的在线应用程序来说都是不可接受的延迟。
- 如果我们想用GPT3取代性能良好的高精度微调模块,或者想在某些特定任务和用例中开发NLU/NLG模型,我们需要三思而后行,它是否值得。
- 对于一些传统自然语言理解(NLU)任务,如分类,我建议先微调FLAN-T5-11B,而不是提示GPT3。例如,在SuperGLUE中,一个困难的NLU基准,包括阅读理解、文本蕴涵、单词感消歧义、核心参考分辨率和因果推理任务,PaLM(540B)的所有少量提示结果仍然比微调T5-11B更糟糕,大多数任务存在显著差距。使用原始的GPT3,其提示结果和微调SOTA结果之间的差距甚至更大。有趣的是,即使是微调的PaLM也只会导致对Fintuned T5-11B的有限改进,微调PaLM甚至比微调编码器解码器32B MoE模型更糟糕。这表明,无论微调还是提示,使用更合适的架构(例如编码器-解码器)微调较小的模型仍然是一个更好的解决方案,而不是使用非常大的解码器模型。根据最近的一篇论文,即使是最传统的NLU分类任务-情绪分析,ChatGPT仍然比微调的小型模型更糟糕。
- 一些不基于现实世界数据的困难任务。例如,BigBench中仍然有很多难题任务。具体来说,在35%的BigBench任务中,人的平均性能仍然高于PaLM 540B,还有一些任务甚至缩放甚至无济于事,例如导航和数学归纳。在数学归纳中,当提示符中的假设不正确时,PaLM会犯许多错误(例如“2是一个奇数”)。在反向缩放定律挑战中也观察到类似的趋势,例如重新定义数学(例如,提示可能“将π重新定义为462”)。在这种情况下,LLM中的现实世界先验太强,不能被提示覆盖,而微调较小的模型可能会更好地适应反事实知识。
- 在许多多语言任务和机器翻译(MT)任务中,使用少量提示GPT仍然比Fintuned较小模型更糟糕,这很可能是因为英语以外的语言的预训练数据比例较少。
- 在从英语翻译成其他语言以及将高资源语言翻译成英语时,PaLM和ChatGPT仍然比MTfinetuned较小的模型更糟糕
- 少量的PaLM 540B和微调的小型模型之间仍然存在很大差距,用于多语言问题回答
- 对于多语言文本生成(包括摘要和数据到文本生成),少量照片PaLM 540B和微调较小的模型之间仍然存在巨大差距。在大多数任务中,即使是微调PaLM-540B也只会比微调T5-11B带来有限的改进,并且比微调SOTA更糟糕。
- 对于常识推理任务,与更好的性能数学推理相比,最好的少数镜头提示LLM和微调SOTA(如OpenbookQA、ARC(Easy和Challenge版本)和CommonsenseQA(甚至使用CoT提示)之间仍然存在很大差距。
- 对于机器阅读理解任务,最好的少数镜头提示LLM和微调SOTA之间仍然存在很大差距。在大多数数据集中,差距非常大。这可能是因为回答问题所需的所有知识在给定的段落中已经可用,并且不需要LLM的额外知识。
总而言之,上述任务分为以下类别之一:
- 一些既不需要知识也不需要LLM生成能力的NLU任务,这意味着测试数据点大多与手头的训练数据点分布相同。以前微调模型已经很好地执行了这些任务。
- 一些不需要LLM提供太多额外知识的任务,因为每个示例的上下文/提示中都已经包含足够的知识,例如机器阅读理解。
- 一些需要额外知识但不太可能获得足够知识的任务,或从LLM中看到类似的分布,例如一些低资源语言中的任务,其中LLM在这种语言中的训练前数据有限。
- 一些需要知识的任务,这与LLM中的知识不一致,或者没有基于大多数现实世界的语言数据。由于LLM是接受现实世界语言数据的训练,因此在新任务中很难用反事实知识来覆盖知识。除了反向缩放法挑战中的“重新定义数学”问题外,还有另一个名为“修改引用重复”的例子,要求LLM在提示符中重复修改后的名引号。在这种情况下,LLM倾向于重复原始的著名引文,而不是修改后的版本。
- 一些需要LM知识的任务,但也严重依赖于操纵这些知识,而LLM下一个令牌预测目标无法轻松解决此类操作。一个例子是一些常识性的推理任务。CoT和最少的提示之所以可以帮助法学硕士推理,可能是因为它们可以更好地调用那些连续的预训练文本,这些文本恰好模仿了规划和分解/组合知识的过程。因此,CoT和最少的提示在一些数学推理、编码和其他简单的自然语言推理任务中表现良好,但在许多常识性推理(例如逆缩放定律中解释的演绎推理)和有线符号推理任务中仍然挣扎,这些任务不包含在自然语言数据中大多数现实世界的连续序列中,需要操纵分布式知识。
- 一些任务容易在上下文学习示例或现实世界数据中受到虚假相关性的影响。一个例子是反向缩放法挑战的否定问题回答。如果LLM被问到“如果猫的体温低于平均水平,它不在”,它倾向于产生“危险”而不是“安全范围”。这是因为LLM以“低于平均水平的身体温度”和“危险”之间的关系为主,相反,这与否定是虚假的相关性。
- 一些目标与语言数据大不相同的任务,例如回归问题,微调模型很难被LLM取代。至于多模式任务,它们无法由LLM完成,但可能会从更好的大型预训练多模式模型中受益。
- 一些不需要LLM紧急能力的任务,为了准确地对更多此类任务进行分类,我们需要更好地了解这些紧急能力在LLM训练期间来自哪里。
请注意,在现实世界的用例中,即使无法在线使用LLM来满足延迟要求,仍然可以使用LLM离线生成/标记数据。这种标记数据可以在线查找并提供给用户,或者用于微调较小的模型。使用这些数据微调较小的模型可以缓解训练模型所需的人工注释数据,并注入一些紧急能力(例如CoT)将LLM到较小的型号。
总之,当有足够的标记数据时,考虑到开源FLAN-T5在许多任务中的惊人性能,我建议调用OpenAI API的资源有限的人首先尝试微调目标任务上的FLAN-T5-11B。此外,根据最近FLAN-PaLM 540B在MMLU数据集上的性能(根据HELM)的最新版本相比,FLAN-PaLM 540B的性能惊人地更好,如果OpenAI已经通过API推出了最强的LLM,谷歌可能会拥有比OpenAI更强大的基本模型。谷歌唯一剩下的步骤是通过人类反馈使这个LLM与对话场景保持一致。如果他们很快就有了像ChatGPT这样相似甚至更好的聊天机器人,我不会感到惊讶,尽管他们最近“没有成功”发布了Bard,这可能是基于LaMDA的。
参考文献:
- HELM:语言模型及其董事会的整体评估:https://crfm.stanford.edu/helm/v0.2.0/?group=core_scenarios
- GPT3:语言模型是很少有热门学习者
- PaLM:使用路径扩展语言建模
- OPT:开放预训练变压器语言模型
- BLOOM:176B参数开放获取多语言模型
- FLAN-T5/PaLM:缩放指令-Finetuned语言模型
- Flan收集:设计有效指令调优的数据和方法
- 指导GPT:训练语言模型遵循人工反馈的说明
- Yao Fu关于“将语言模型的新兴能力追查到源头”的博客
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢