
Paper: https://arxiv.org/pdf/2302.04869.pdf
Code: https: //github.com/facebookresearch/slowfast.
近年来,计算机视觉领域中出现的许多基于深度学习的革命性工作均离不开高性能硬件的支持。在专用 AI 加速器的推动下,对最先进模型的计算量要求呈指数级增长。然而,计算量只是一部分,还有另一部分是被大家经常忽视的内存带宽瓶颈。 据统计,AI 加速器的FLOPs是以每2年约3.1倍的速度增加,而带宽仅是每2年约1.4倍。这种差异导致了所谓的内存墙,这尤其在transformer中尤其明显。
因此,对于带宽需求高的模型可以通过重新计算(re-computation),以计算换取内存可能比目前SOTA算法更有效。 例如,在模型训练阶段,可以通过重新计算激活值代替在内存中对激活值进行先存后取的操作。除了训练速度之外,缩放vision transformer网络深度会影响 GPU 内存容量。例如,视频识别领域的SOTA模型的batch size仅能为1,这是由于中间激活层的内存占用量过大造成的。
基于此,本文提出了可逆的vision transformer(Rev-ViT),与不可逆的版本相比,它的内存占用量显著降低,如上图所示。通过权衡 GPU 激活缓存与高效的即时激活重新计算,Rev-ViT有效地将激活内存增长与模型深度分离。 此外,通过重新配置ViT和Multiscale ViT中的残差路径,有效解决了模型训练收敛不稳定问题,使得Rev-ViT能够直接适应深层的常规ViT架构。
本文提出的Rev-ViT方法的主要贡献如下:
-
提出了Rev-ViT 和Rev-MViT,这是目前最先进的内存友好型的视觉识别backbone。
-
通过大量的消融实验发现,Rev-ViT比常规ViT具有更强的正则化能力。
-
在图像分类、检测和动作识别数据集上验证了本文方法的高效性,Rev-ViT比ViT在内存使用的指标上平均低10+倍。
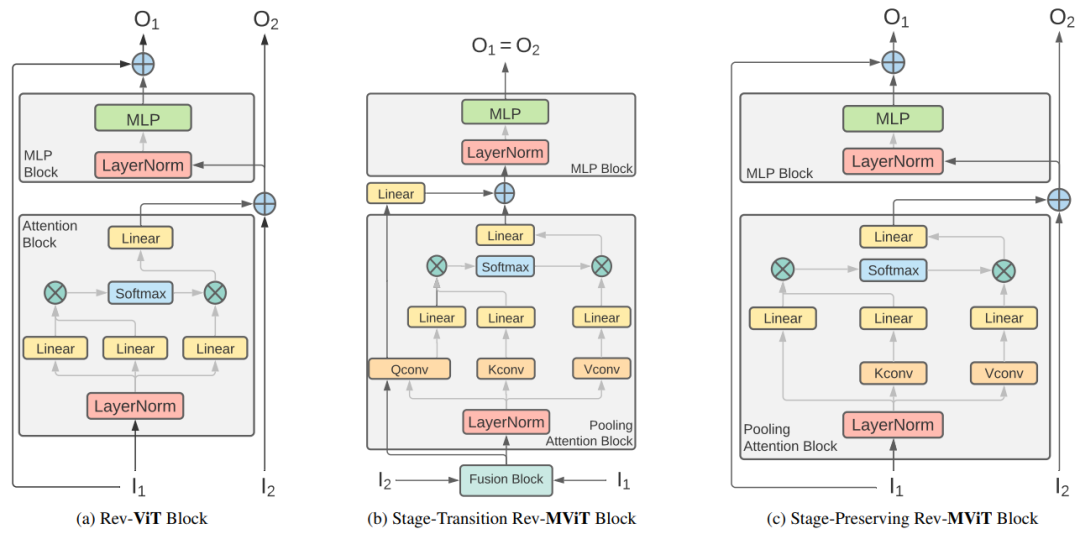 Rev-ViT和Rev-MViT结构图
Rev-ViT和Rev-MViT结构图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢