随着神经网络的成功应用,各项研究和机构也一直在致力于实现快速且高效的计算,特别是在推理时。对此,各种技术应运而生,包括降低计算精度,二进制和稀疏神经网络。本文中,来自斯坦福大学、萨尔茨堡大学等机构的研究者希望训练出一种不同的、在计算机领域被广泛应用的体系架构:逻辑门网络(logic (gate) networks)。
训练像逻辑门这样的离散组件网络所面临的问题是,它们是不可微的,因此,一般而言,不能通过梯度下降等标准方法进行优化。研究者提出了一种方法是无梯度优化方法,如演化训练(evolutionary training),它适用于小型模型,但不适用于大型模型。
在这项工作中,该研究探索了用于机器学习任务的逻辑门网络。这些网络由「AND」和「XOR」等逻辑门电路组成,可以快速执行任务。逻辑门网络的难点在于它通常是不可微的,不允许用梯度下降进行训练。因此,可微逻辑门网络的出现是为了进行有效的训练。由此产生的离散逻辑门网络实现了快速的推理速度,例如,在单个 CPU 核上每秒处理超过一百万张 MNIST 图像。这篇论文入选 NeurIPS 2022。

论文标题:Deep Differentiable Logic Gate Networks
代码链接:https://github.com/Felix-Petersen/difflogic
纽约大学计算机科学教授 Alfredo Canziani 表示:由逻辑门(如 AND 和 XOR)组成的可学习组合网络,允许非常快速的执行任务及硬件实现。

距离论文公开才过去三个月,论文作者 Felix Petersen 表示该研究的官方实现已经公布,他们发布了 difflogic 项目,这是一个基于 pytorch 实现的可微逻辑门网络库。不仅如此,经过优化现在的训练速度比最初的速度快 50-100 倍,因为该研究提供了高度优化的 CUDA 内核。
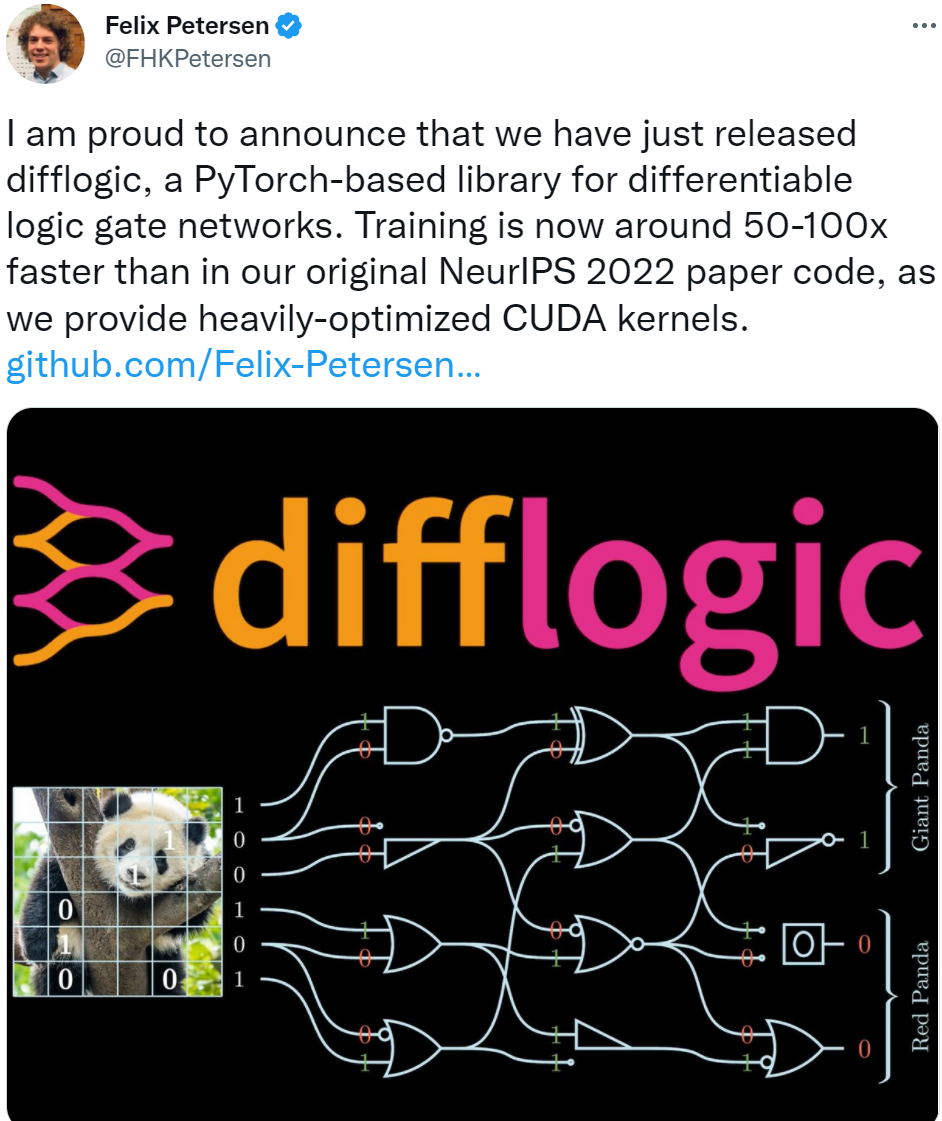
difflogic 是一个基于 Python 3.6 + 和 PyTorch 1.9.0 + 的库,基于逻辑门网络进行训练和推理。该库安装代码如下:
需要注意的是,使用 difflogic,还需要 CUDA、CUDA 工具包(用于编译)以及 torch>=1.9.0(匹配 CUDA 版本)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢