
来自今天的爱可可AI前沿推介
[LG] Simple Hardware-Efficient Long Convolutions for Sequence Modeling
D Y. Fu, E L. Epstein, E Nguyen, A W. Thomas, M Zhang, T Dao, A Rudra, C Ré
[Stanford University]
用于序列建模的简单硬件高效长卷积
要点:
-
在长序列建模中,长卷积是状态空间模型的有效替代方法; -
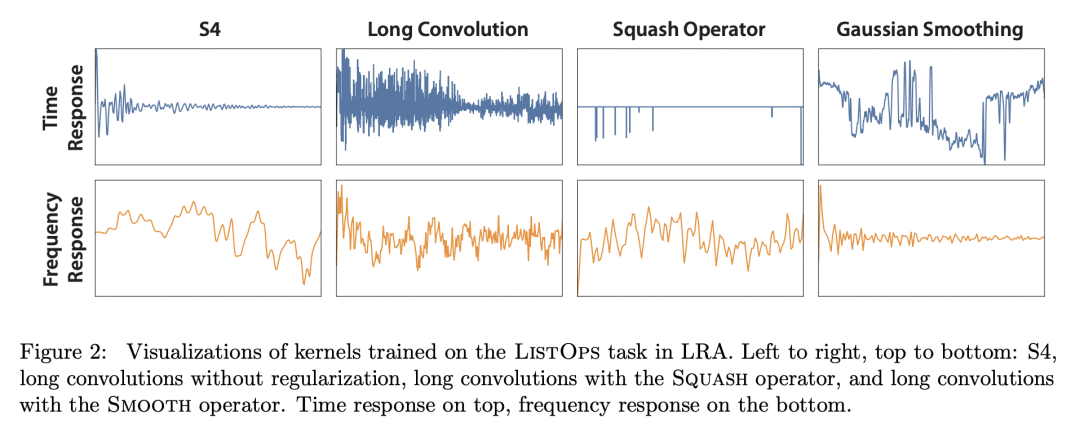
平滑核权重是实现长卷积的高性能的关键; -
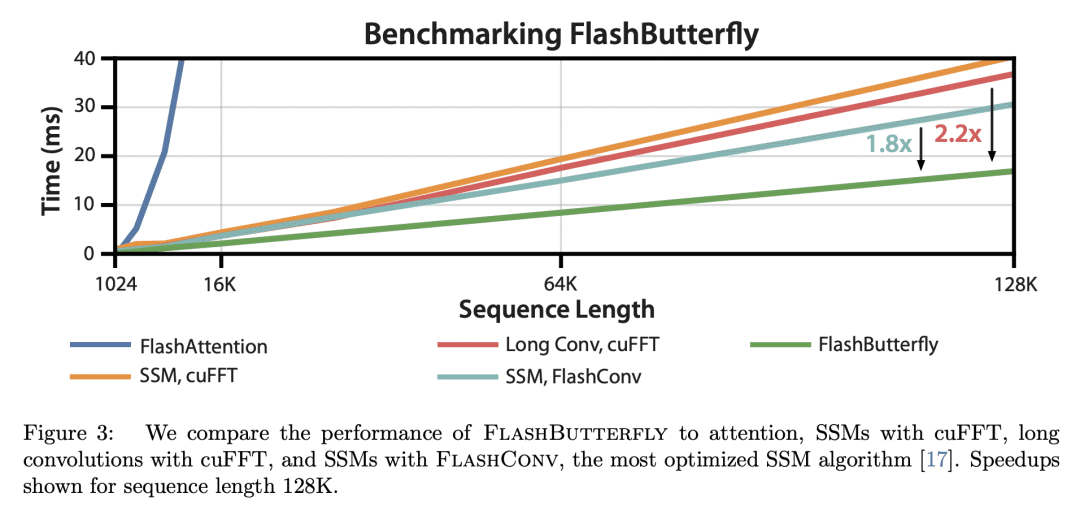
FlashButterfly 是一种 IO 感知算法,通过减少 GPU 内存 IO 、提高 FLOP 利用率来提高长卷积的运行性能; -
通过利用与 Butterfly 矩阵的连接,长卷积的训练速度比状态空间模型快1.8倍。
一句话总结:
长卷积是状态空间模型在序列建模方面的一个硬件高效的替代方案,需要简单的干预措施,如平滑核权重以实现高性能,并引入 IO 感知算法 FlashButterfly 以提高运行效率。
State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2×, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2× faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
论文链接:https://arxiv.org/abs/2302.06646

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢