

来自爱可可的前沿推介
Big Little Transformer Decoder
S Kim, K Mangalam, J Malik, M W. Mahoney, A Gholami, K Keutzer
[UC Berkeley]
大-小Transformer解码器
要点:
-
提出 BiLD 框架,可为广泛的文本生成应用提高推理效率、降低延迟;
-
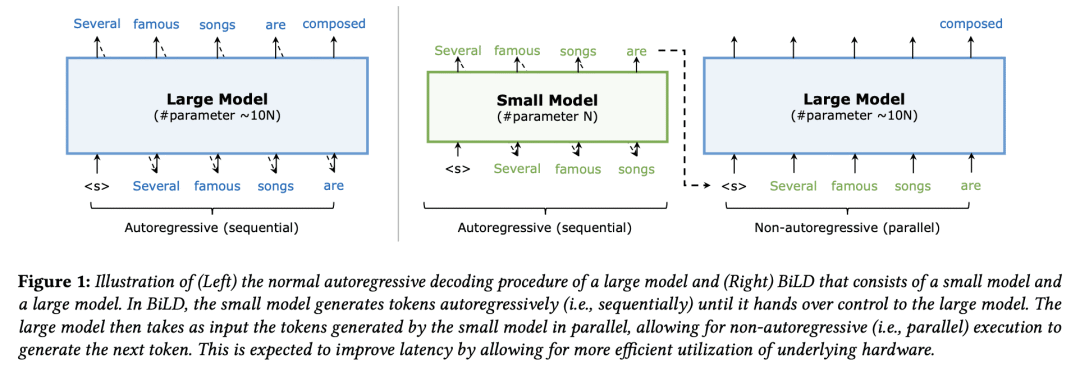
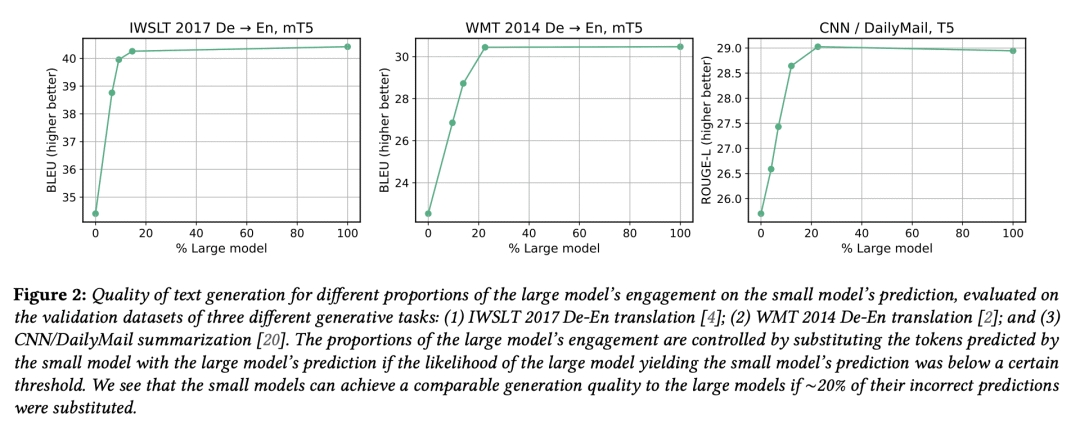
BiLD 包含两个不同规模的模型,以协同方式生成文本:小模型以自回归方式运行,大模型以非自回归方式完善小模型的不准确预测;
-
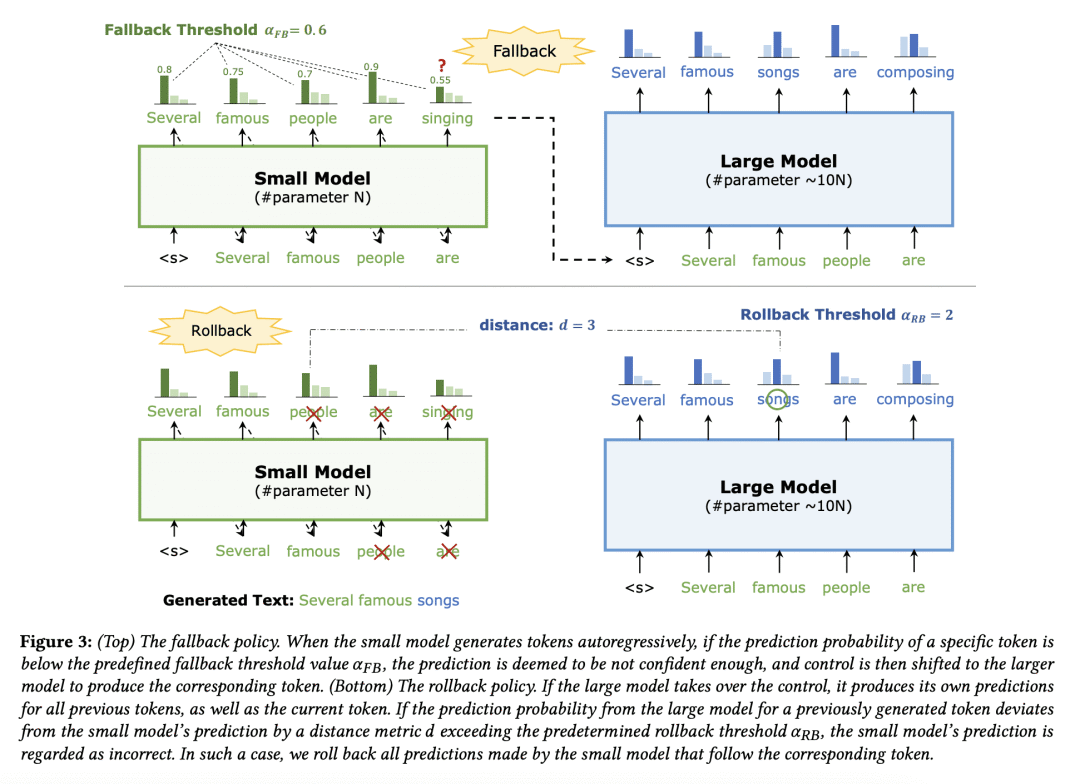
BiLD 引入两种策略来协调小模型和大模型:回退策略和回滚策略;
-
BiLD在 NVIDIA Titan Xp GPU上 实现了高达 2.13 倍的速度而没有任何性能下降,并且在 NVIDIA Titan Xp GPU 上实现了高达 2.38 倍的速度而只有约1个点的下降,而且完全即插即用,不需要任何训练或对模型架构的修改。
一句话总结:
提出 BiLD 框架,通过耦合大型和小型解码器模型并引入两种策略来进行协调,从而减少文本生成任务的推理延迟。
The recent emergence of Large Language Models based on the Transformer architecture has enabled dramatic advancements in the field of Natural Language Processing. However, these models have long inference latency, which limits their deployment, and which makes them prohibitively expensive for various real-time applications. The inference latency is further exacerbated by autoregressive generative tasks, as models need to run iteratively to generate tokens sequentially without leveraging token-level parallelization. To address this, we propose Big Little Decoder (BiLD), a framework that can improve inference efficiency and latency for a wide range of text generation applications. The BiLD framework contains two models with different sizes that collaboratively generate text. The small model runs autoregressively to generate text with a low inference cost, and the large model is only invoked occasionally to refine the small model's inaccurate predictions in a non-autoregressive manner. To coordinate the small and large models, BiLD introduces two simple yet effective policies: (1) the fallback policy that determines when to hand control over to the large model; and (2) the rollback policy that determines when the large model needs to review and correct the small model's inaccurate predictions. To evaluate our framework across different tasks and models, we apply BiLD to various text generation scenarios encompassing machine translation on IWSLT 2017 De-En and WMT 2014 De-En, summarization on CNN/DailyMail, and language modeling on WikiText-2. On an NVIDIA Titan Xp GPU, our framework achieves a speedup of up to 2.13x without any performance drop, and it achieves up to 2.38x speedup with only ~1 point degradation. Furthermore, our framework is fully plug-and-play as it does not require any training or modifications to model architectures. Our code will be open-sourced.
https://arxiv.org/abs/2302.07863
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢