
自 ViT 时代到来之后,由一叠 blocks 堆起来构成的基础模型已经成为了广泛遵循的基础模型设计范式,一个神经网络的宏观架构由width宽度(channel 数)和 depth 深度(block 数)来决定。有没有想过,一个神经网络未必是一叠 blocks 组成的?可能是 2 叠,4 叠,或者…16 叠?
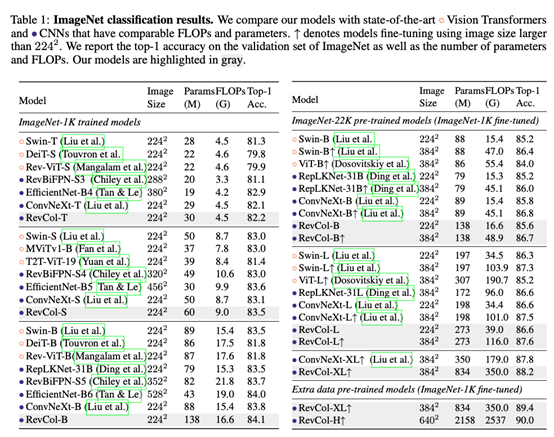
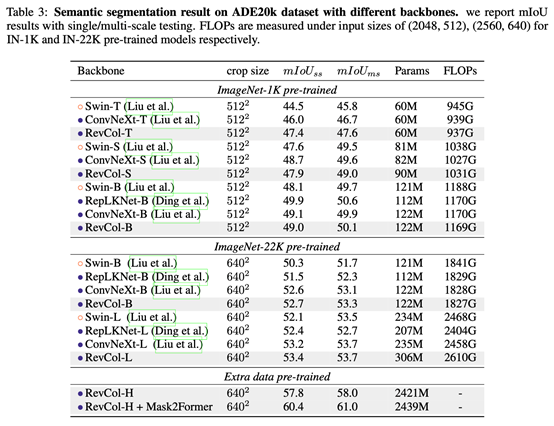
介绍一下我们最新的工作“Reversible Column Networks”,将解耦学习(disentangled feature learning)的思想引入模型设计中,提出以 reversible column 为单元来传递信息,既保证特征解耦,同时信息在网络中的传递不受到损失。整个网络结构包括了多个子网络(我们称为 column),column 间加入可逆的连接,通过将输入反复接入 column,逐渐分离 low-level 的纹理细节和 semantic 语义信息。这样做的好处在于,既能够保证在预训练中保持高精度,又保证了 low-level 的信息不丢失以在下游任务(detection,segmentation)中能够达到更好效果。为了验证这套设计模式在大模型大数据下的表现,我们在 RevCol 上做了一个2B 参数的纯 CNN 超大模型,且只使用了 3x3 的卷积核。在 ImageNet-1K 上达到了 90% 的 Top-1 Accuracy,下游的检测和分割任务上双双达到 60+的水平,COCO AP box 63.8%,ADE 20k mIoU 61.0%。此外,RevCol 架构依然遵循了可逆神经网络的设计范式,也就继承了可逆网络天然的节省显存的优势,文中的大部分实验均可在 2080ti 上完成。而节省显存这件事,对于大模型训练无疑是重要的。
论文链接: https://arxiv.org/pdf/2212.11696.pdf
代码链接: https://github.com/megvii-research/RevCol
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢