
Efficiency 360: Efficient Vision Transformers
B N. Patro, V Agneeswaran
[Microsoft]
Efficiency 360: 高效视觉Transformer
要点:
-
为视觉 Transformer 引入一个高效的360框架,面向工业应用,将其分为隐私、鲁棒性和包容性等多个维度; -
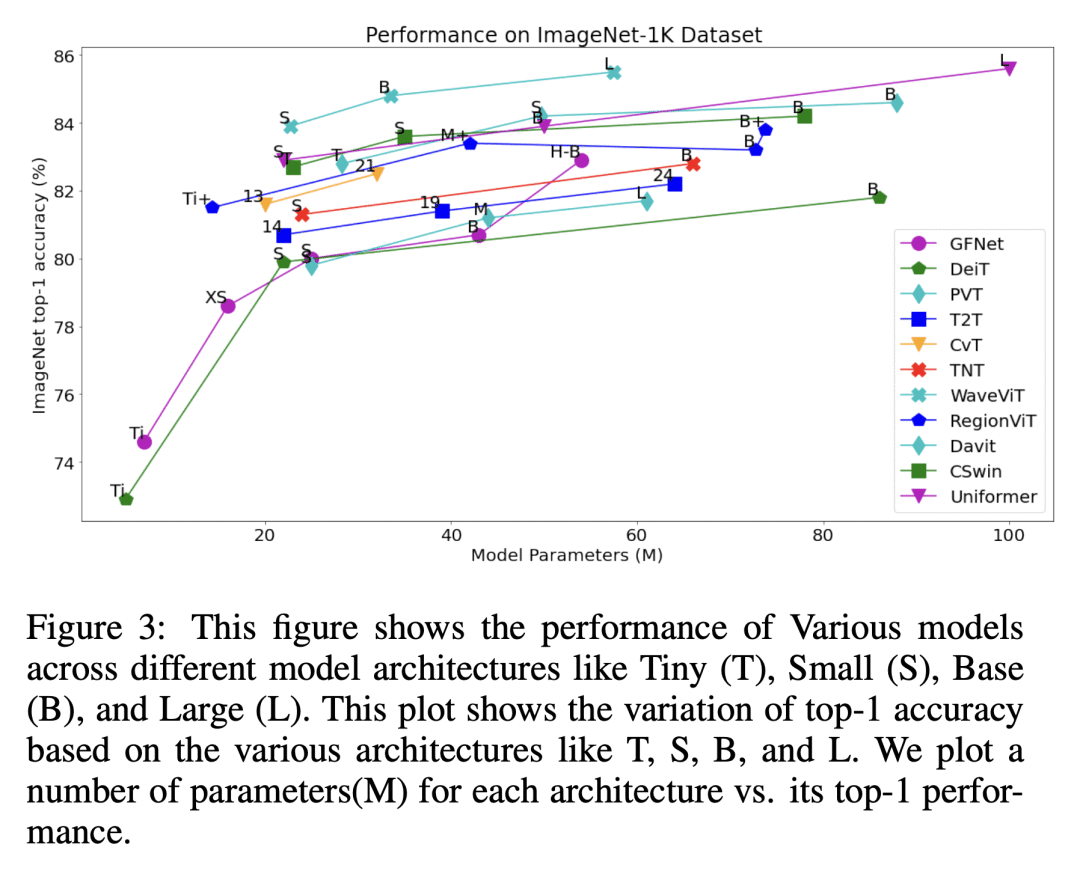
根据多种数据集的性能、参数数量和浮点运算量,对各种视觉 Transformer 模型进行了比较; -
讨论了 Transformer 在隐私、透明度、公平性和包容性等方面的研究潜力; -
强调了高级 Transformer 模型在其他模态数据上的适用性,如音频、语音和视频,以及天气预报和海洋学中的高分辨率数据。
一句话总结:
讨论了视觉 Transformer 的效率,并介绍了工业应用的高效 360 框架,将其分为多个维度,如隐私性、鲁棒性、透明度、公平性、包容性,等等。
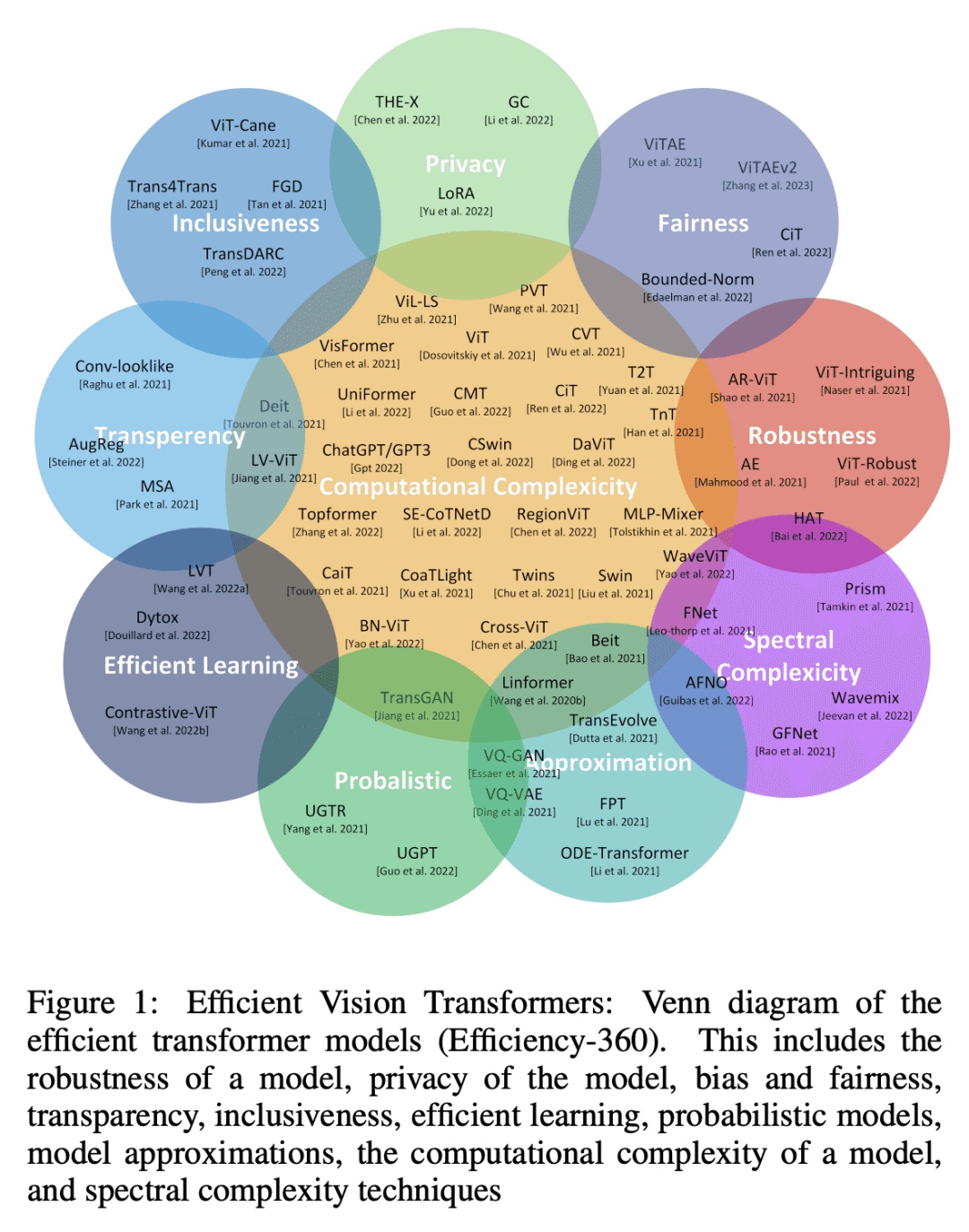
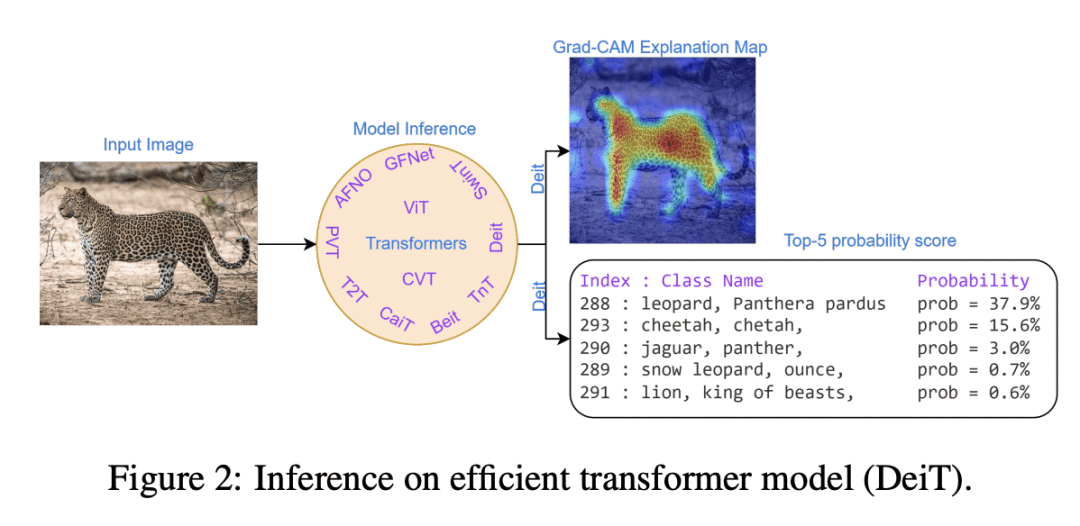
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair & bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
https://arxiv.org/abs/2302.08374
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢