
【论文标题】Making a Case for 3D Convolutions for Object Segmentation in Videos 【亚琛工大Bastian和慕尼黑Laura团队】使用三维卷积进行视频目标分割 【作者团队】Sabarinath Mahadevan, Ali Athar, Aljosa Osep, Sebastian Hennen, Laura Leal-Taixé, and Bastian Leibe 【发表时间】9月17日 【论文链接】https://www.bmvc2020-conference.com/assets/papers/0233.pdf 【论文代码】https://github.com/sabarim/3DC-Seg 【推荐理由】“本文收录于BMVC-2020会议,来自亚琛工业大学和慕尼黑工业大学的研究人员提出一种全新的三维卷积神经网络用于视频目标分割任务(VOS)。”
视频中的对象分割任务通常是通过使用标准的二维卷积网络分别处理外观和运动信息,然后对两种信息源进行融合来完成。另一方面,三维卷积网络已成功地应用于视频分类任务,但与二维卷积相比,尚未有效地利用视频中涉及密集像素的解释问题,并且在性能方面落后于上述网络。 在这项工作中,研究团队证明了三维卷积神经网络可以有效地应用于密集视频预测任务,例如显著目标分割。本文提出了一种简单而有效的编码器-解码器网络结构,该体系结构完全由3D卷积组成,可以使用标准的交叉熵损失函数进行端到端训练。为此,研究人员利用了高效的3D编码器,并提出了一种3D解码器体系结构,其中包括新颖的3D全局卷积层和3D优化模块。该方法不仅速度更快,而且在DAVIS'16无监督任务上,FBMS和ViSal数据集基准方面的性能远远优于现有的最新技术,因此表明该体系结构可以有效地学习表现力的时空特征并产生高质量的视频分割蒙版。
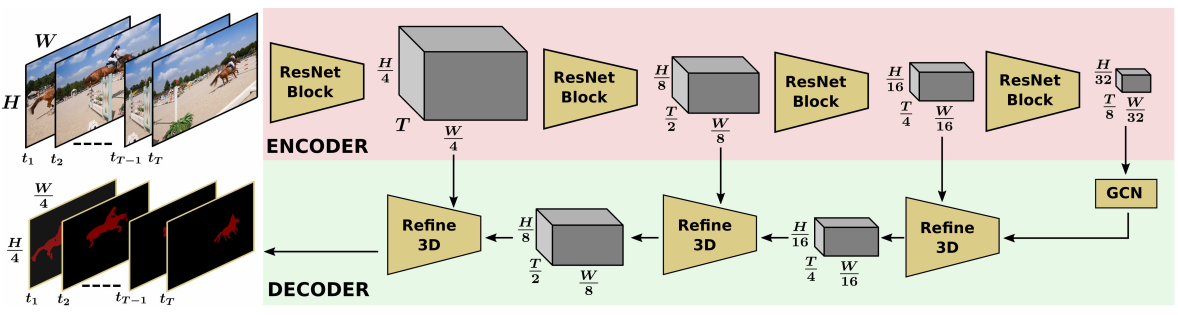 编码器-解码器网络结构解释
编码器-解码器网络结构解释
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢