
0. 论文信息
标题:DreamFusion: Text-to-3D using 2D Diffusion
作者:Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
原文链接:https://arxiv.org/abs/2209.14988
代码链接:https://dreamfusion3d.github.io/?utm_source=catalyzex.com
1. 前置信息
1.1 NeRF
NeRF(神经辐射场)是一种用于三维场景重建和渲染的深度学习方法,它将场景中每个三维点的颜色和密度表示为神经网络的输出。NeRF 可以从不同角度的图像中学习场景的三维表示,并能够生成高质量的图像和视频。NeRF自2020年提出后,极大的推动了计算机视觉和计算机图形学的结合。它的目的是合成同一场景不同视角下的图像。对于方法,也非常直接,就是给定一个场景的若干张图片,重构出这个场景的3D表示,然后推理的时候输入不同视角就可以合成(渲染)这个视角下的图像。
参考:https://zhuanlan.zhihu.com/p/569843149
1.2 Diffusion model
2. 引言
近年来,DALL-E2,Stable Diffusion这些通过文本生成图像的大模型十分流行。这些生成图像模型现在支持高保真、多样且可控的图像合成。这些质量改进来自大型对齐图像文本数据集 和可扩展的生成模型架构。diffusion model在学习具有稳定且可扩展的目标过程中非常鲁棒。将扩散模型应用于其他模态已经成功,但需要大量特定于模态的训练数据。3D的数据比2D的数据收集要复杂的多,那怎么借助大模型获得3D的模型呢?在这项工作中,我们开发了将预训练的 2D 图像-文本扩散模型传输到 3D 对象合成的技术,无需任何 3D 数据。尽管 2D 图像生成应用广泛,但模拟器和数字媒体(如视频游戏和电影)需要数以千计的详细 3D 资产来填充丰富的交互环境。3D 数据目前是在 Blender 和 Maya3D 等建模软件中手工设计的,这一过程需要大量时间和专业知识。文本到 3D 生成模型可以降低新手的入门门槛,并改善有经验的艺术家的工作流程。3D 生成模型可以在pixel voxel和点云等结构的显式表示上进行训练,但与丰富的 2D 图像相比,所需的 3D 数据相对稀缺。论文的方法仅使用在图像上训练的 2D 扩散模型来学习 3D 结构,并回避了这个问题。GAN 可以从单个对象类别的照片中学习可控的 3D 生成器。尽管这些方法在特定对象类别(例如面部)上取得了可喜的结果,但尚未证明它们支持任意文本的描述。而NeRF是一种逆向渲染方法,其中体积光线追踪器与从空间坐标到颜色和体积密度的神经映射相结合。最初,NeRF 被发现非常适用于“经典”3D 重建任务:一个场景的许多图像被提供作为模型的输入,NeRF 被优化以恢复该特定场景的几何形状,从而允许新的视图 从未被观察到的角度拍摄该场景,以进行合成。许多 3D 生成方法已成功地将类似 NeRF 的模型作为构建块纳入更大的生成系统中,它们使用来自 CLIP 的冻结图像-文本联合嵌入模型和基于优化的方法来训练 NeRF。这些工作说明,预训练的 2D 图像文本模型可用于 3D 合成,尽管通过这种方法生成的 3D 对象往往缺乏真实感和准确性。

如上图所见,本文利用diffusion生成的3D模型质量还是非常高的。论文提出的Dream Fields 采用了类似的方法,但是用从 2D 扩散模型的蒸馏中得到的损失代替了 CLIP。我们的损失基于概率密度蒸馏,基于扩散的前向过程和通过预训练扩散模型学习的得分函数最小化具有共享均值的高斯分布族之间的 KL 散度。由此产生的分数蒸馏采样 (Score Distillation Sampling) 方法可以通过优化可微图像参数化来进行采样。通过将Score Distillation Sampling与专为该 3D 生成任务量身定制的 NeRF 变体相结合,dream fusion 可为用户提供的各种文本提示集生成高保真连贯的 3D 对象和场景。
3. 方法
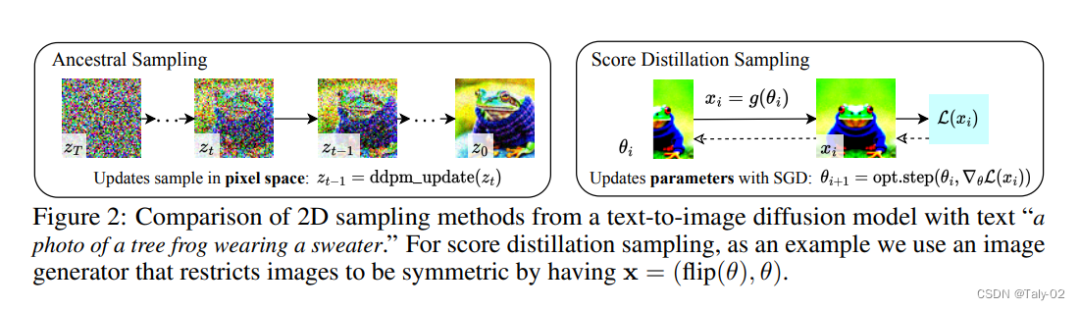
扩散模型包含前向过程和反向过程,前者通过逐步添加噪声和移除结构,缓慢地将数据变得模糊,反向过程或生成式模型则在噪声上逐渐添加结构。现有的扩散模型采样方法只能对像素进行采样,但研究人员希望生成的三维模型从随机角度渲染时具有良好的外观,因此他们使用可微分图像参数化(DIP)来实现约束条件的表达和更强大的优化算法。
在DIP中,参数θ表示三维体积的参数,可微生成器g是体积渲染器。为了学习这些参数,需要一个适用于扩散模型的损失函数,该函数利用扩散模型的结构,通过优化实现可操作的取样。当损失函数最小化时生成一个样本,然后对参数θ进行优化,使x=g(θ)看起来像冻结扩散模型的样本。
在实践中,研究人员发现即使是在使用相同的DIP时,损失函数也无法生成现实的样本。但同期的一项工作表明,通过精心选择的时间步长可以实现这个目标。然而,这种方法是脆弱的,且时间步长的调整非常困难。通过观察和分解梯度,作者发现U-Net Jacobian项的计算成本很高,而且对于小的噪声水平来说条件很差。
介绍好了该方法的数学模型,下面来看具体的完成过程。如何完成SDS与定制的NeRF变体相结合,来生成高保真的连贯的3D物体和场景。该方法使用预训练扩散模型Imagen,并按原样使用分辨率为64×64的基础模型,同时采用类似于NeRF的随机权重初始化模型,并用反复渲染的视图作为环绕Imagen的分数蒸馏损失函数的输入。
给出一个预训练好的tex-to-image的model,一个以NeRF形式存在的可w微分的图像参数化DIP,利用一个loss来作为优化目标。
对于每个文本的prompt,都从头开始训练一个随机初始化的NeRF。DreamFusion优化的每次迭代都包含四步:
-
随机采样一个相机和灯光
-
从该相机和灯光下渲染NeRF的图像
-
计算SDS损失相对于NeRF参数的梯度。
-
使用优化器更新NeRF参数。
4. 实验

首先通过可视化我们可以发现,DreamFusion 可用于创建和优化 3D 场景。在这里,我们迭代地改进示例文本提示,同时从四个不同的角度渲染每个生成的场景。效果还是非常不错的。
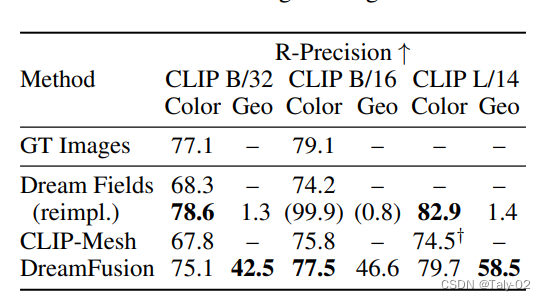
再来看相较于之前的方法 CLIP-Mesh等,还是具有主观上的优势的。同时可以发现,RP值相较于即使是GT-Images也是非常逼真的,可见方法的优越性。
5. 方法
论文提出了 DreamFusion,这是一种用于各种文本提示的文本到 3D 合成的有效技术。DreamFusion 的工作原理是通过使用一种新颖的分数蒸馏采样方法和一种新颖的类 NeRF 渲染引擎,将可扩展的高质量 2D 图像扩散模型转移到 3D 域。DreamFusion 不需要 3D 或多视图训练数据,仅使用预训练的 2D 扩散模型(仅在 2D 图像上训练)进行 3D 合成。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢