
Energy Transformer
B Hoover, Y Liang, B Pham, R Panda, H Strobelt, D H Chau, M J. Zaki, D Krotov
[IBM Research & RPI & Georgia Tech]
能量Transformer
要点:
-
能量Transformer(ET)用一个大型关联记忆模型取代了前馈 Transformer 块的序列; -
能量Transformer 被设计为最小化一个表示Token间关系的能量函数; -
与传统的注意力相比,ET 中的注意力机制包含一个额外的 term; -
在图异常检测任务中,ET 显示了强大的定量结果。
一句话总结:
能量Transformer(ET)是一种新的 Transformer 结构,用一个单一的大型关联记忆模型取代了前馈 Transformer 块的序列,旨在最小化一个专门设计的能量函数,该函数表示了令牌之间的关系。
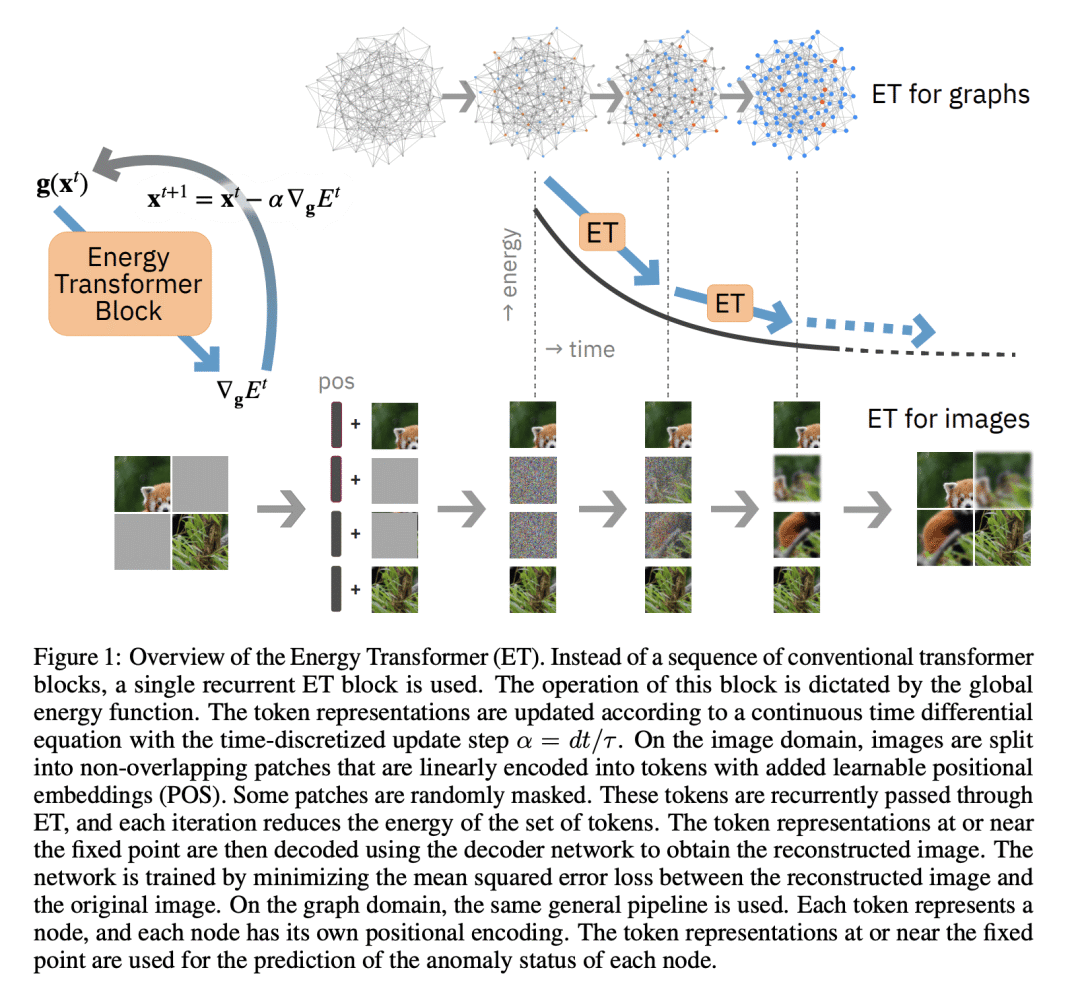
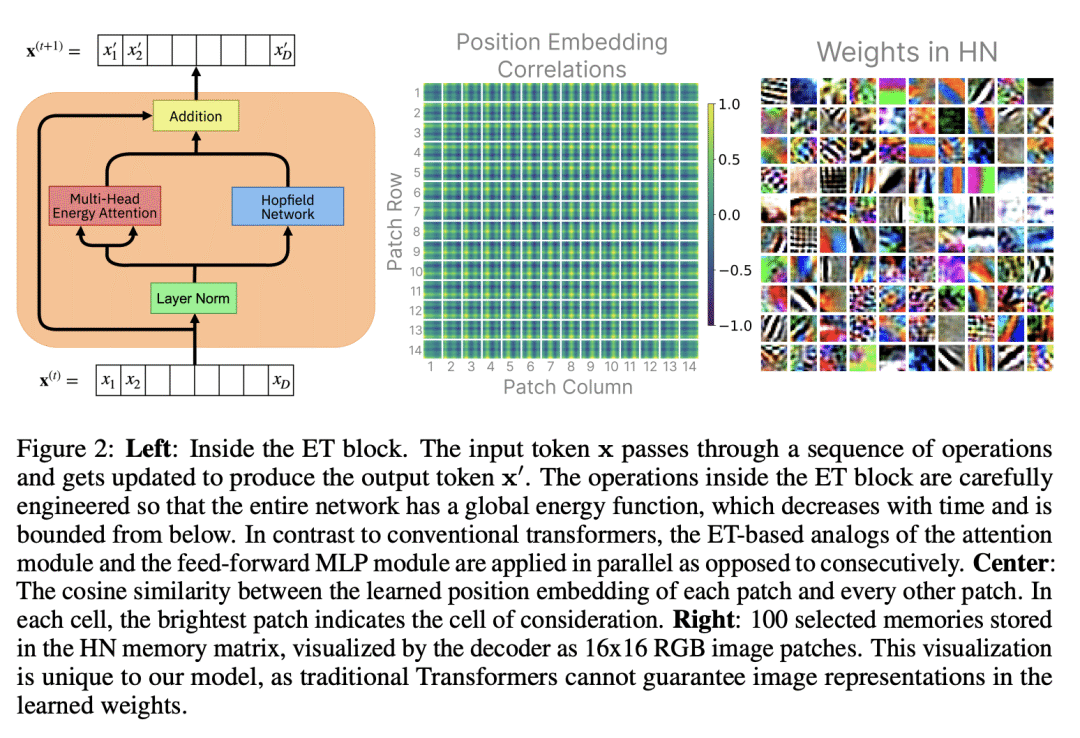
Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
https://arxiv.org/abs/2302.07253

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢