
Massively Multilingual Shallow Fusion with Large Language Models
K Hu, T N. Sainath, B Li, N Du, Y Huang, A M. Dai, Y Zhang, R Cabrera, Z Chen, T Strohman
[Google]
基于大型语言模型的大规模多语言浅融合
要点:
-
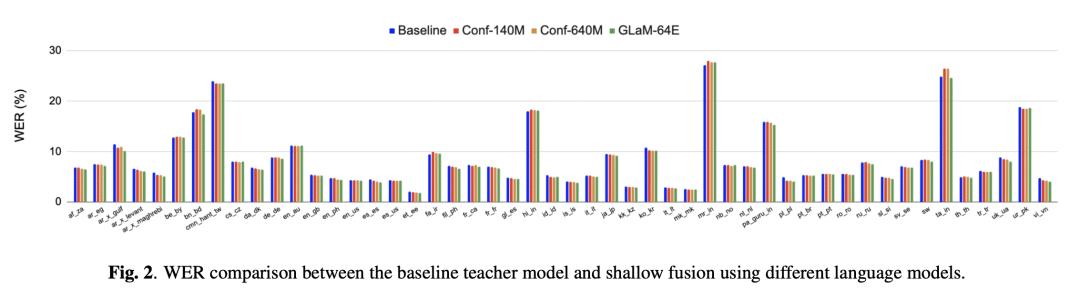
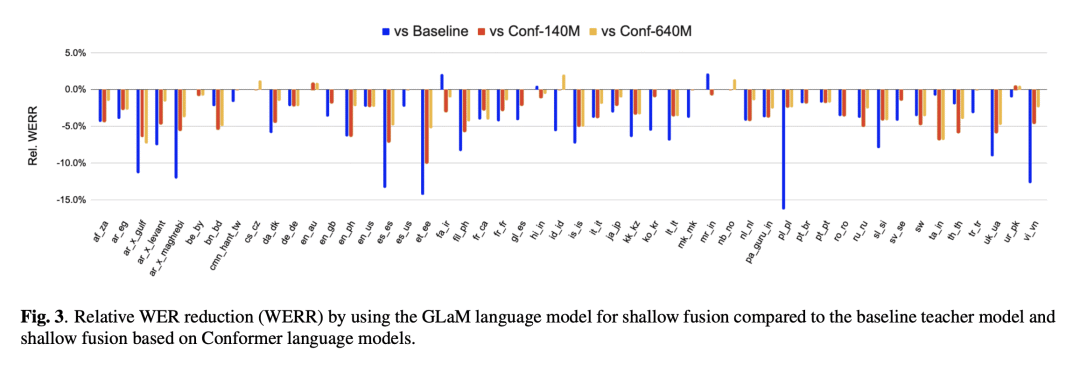
相对于类似计算的稠密型语言模型,GLaM 将英语长尾测试集的误码率降低了4.4%; -
在多语言浅层融合任务中,GLaM 改善了50种语言中 41 种语言的误码率,平均降低了 3.85%,最大相对降低了 10%。 -
与基线模型相比,GLaM 在 43 种语言中实现了平均 5.53% 的误码率降低; -
尽管 GLaM 模型很大(1.9GB),但由于其 MoE 架构,其推理计算量与 140M 稠密语言模型相似。
一句话总结:
提出在自动语音识别的浅层融合中使用大规模多语种语言模型(GLaM),在许多语言中取得了显著的改进。
While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.
论文链接:https://arxiv.org/abs/2302.08917

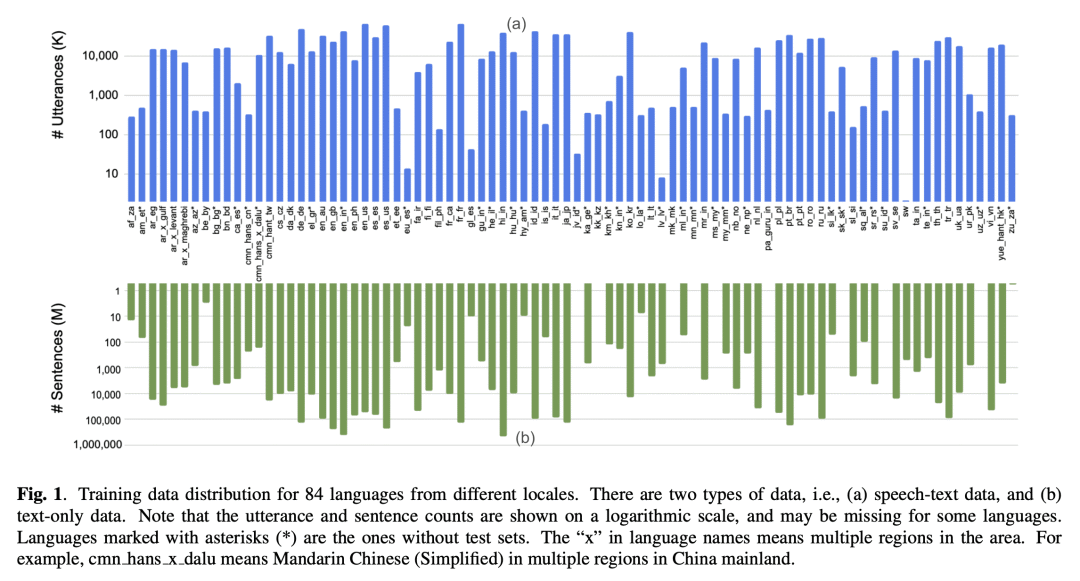
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢