
论文标题:A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
论文链接:https://arxiv.org/abs/2302.09419
作者单位:密歇根大学 & 北京航空航天大学等
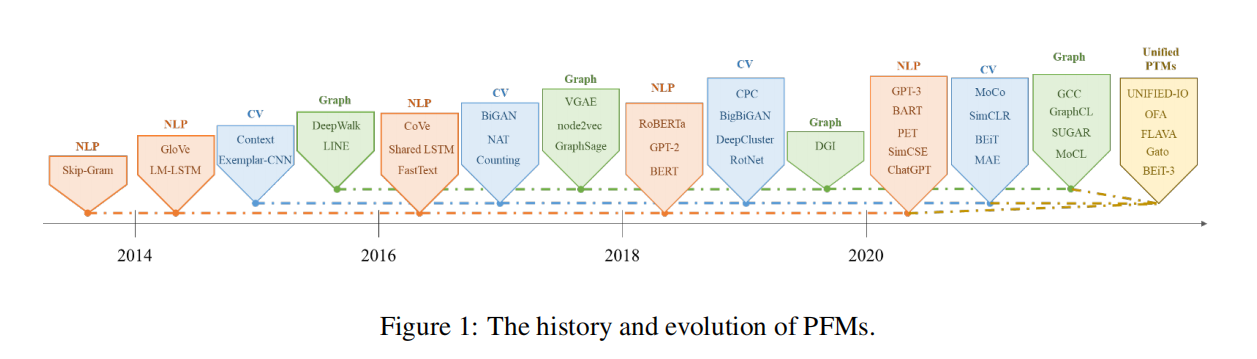
预训练基础模型 (PFM) 被视为具有不同数据模式的各种下游任务的基础。 BERT、GPT-3、MAE、DALLE-E 和 ChatGPT 等预训练基础模型在大规模数据上进行训练,为广泛的下游应用提供合理的参数初始化。 PFM 背后的预训练思想在大型模型的应用中起着重要作用。 作为一种迁移学习范式,预训练通过冻结和微调技术应用于计算机视觉,表现出良好的性能。 自然语言过程中的词嵌入也可以看作是一种归属,但它存在多义等诸多问题。 与以往应用卷积和循环模块进行特征提取的方法不同,生成式预训练 (GPT) 方法应用 Transformer 作为特征提取器,并使用自回归范式在大型数据集上进行训练。 同样,BERT apples transformers 作为上下文语言模型在大型数据集上进行训练。 最近,ChatGPT 在大型语言模型上取得了可喜的成功,它应用了零镜头或很少显示提示的自回归语言模型。 随着 PFM 的非凡成功,AI 在过去几年中在各个领域掀起了波澜。 文献中已经提出了相当多的方法、数据集和评估指标,因此需要更新调查。
本研究全面回顾了最近的研究进展、当前和未来的挑战以及 PFM 在文本、图像、图形以及其他数据模式中的机遇。 我们首先回顾了自然语言处理、计算机视觉和图形学习中的基本组成部分和现有的预训练。 然后,我们讨论其他数据模式的其他高级 PFM 和考虑数据质量和数量的统一 PFM。 此外,我们讨论了有关 PFM 基础知识的相关研究,包括模型效率和压缩、安全性和隐私。 最后,我们列出了关键意义、未来的研究方向、挑战和未解决的问题。 我们希望本次调查能够为 PFM 在人工智能的可扩展性、推理能力、跨域能力、用户友好交互能力、安全性和隐私保护能力方面的研究提供启示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢