
作者 | 于文豪;单位 | 美国圣母大学;研究方向 | 机器学习,自然语言处理
知识密集型任务,例如开放领域问答(QA),需要访问大量的世界或领域知识。解决知识密集型任务的常见方法是使用先检索再阅读的框架,首先从外部语料库(如维基百科)中检索几篇相关的上下文文档,然后根据检索到的文档预测答案。
在本文中,我们提出了一种解决知识密集型任务的新视角,通过用大型语言模型生成器代替文档检索器。我们称之为先生成再阅读(Generate-then-Read),首先向大型语言模型提示(prompt)生成基于给定问题的上下文文档,然后阅读生成的文档以产生最终答案。此外,我们提出了一种基于聚类的提示(prompt)方法,该方法选择不同的提示,以生成涵盖不同视角的不同文档,从而提高接受答案的召回率。
我们对三个不同的知识密集型任务进行了广泛的实验,包括开放领域 QA、事实检查和对话系统。值得注意的是,GENREAD 在 TriviaQA 和 WebQ 上分别获得了 71.6 和 54.4 的精确匹配分数 (Accuracy),明显优于现有 SoTA 技术。

论文标题:
Generate rather than Retrieve: Large Language Models are Strong Context Generators
论文链接:
https://arxiv.org/abs/2209.10063
代码链接:
https://github.com/wyu97/GenRead
论文报告直播地址:
https://event.baai.ac.cn/activities/656
智源LIVE 31期解读交流群
直播提醒、交流互动

总体而言,我们的主要贡献可以总结如下:
1. 我们提出了一种新的先生成再读取框架,用于解决知识密集型任务,即用大型语言模型生成相关上下文文档代替从维基百科检索文档或在 Google 上搜索相关文档的过程;
2. 我们提出了一种新的基于聚类的提示(prompt)方法,用于生成多个不同的上下文文档,增加涵盖正确答案的可能性。我们证明了这种方法可以显著提高端到端问答和其他下游任务的性能;
3. 我们在零样本和监督设置下对三个知识密集型自然语言处理任务进行了广泛的实验。值得注意的是,我们的方法可以与甚至优于从任何外部知识源检索文档的先检索再读取框架方法相匹配。

方法(Generate-then-Read)
核心思路:Generate-then-Read 首先提示大型语言模型生成关于给定查询的上下文文档,然后读取生成的文档以预测最终答案。阅读器可以是一个大型模型(例如 GPT-3),用于 zero-shot 或者 few-shot 的情况,或一个小的可训练的阅读器(例如 FiD),在目标数据集的训练分割上使用生成的文档进行微调。

▲ Figure 1:我们提出的先生成再阅读(Generate-then-Read)的框架可以正确回答图中的问题。GPT-3使用的是text-davinci-002.
Advanced 方法:Clustering-based Prompt
为了增加生成文档中的知识覆盖面,我们提出了一种基于聚类的提示方法。它首先将一组文档的表示聚类成 K 类(图 1 中 K=2),其中类的数量等于最终需要生成的文档数量。接下来,它从每个聚类中随机选择 n 个问题-文档对(图 1 中 n=5)。最后,大型语言模型将不同的 n 个问题-文档对作为上下文演示,以便根据给定问题生成文档。这样,大型语言模型基于不同的示例分布,因此生成的文档涵盖了不同的观点。
我们在图 1 中展示了这一点,并详细说明了每一步的细节:

▲ Figure 2: 基于聚类的提示方法的总体框架。它利用从每个嵌入聚类中抽样的不同问题-文档对作为上下文演示,提示大型语言模型生成多样化的文档,然后阅读文档预测答案。
步骤 1:获得每个问题的一份初始文档。与零点设定类似,我们首先要求大型语言模型为每个问题 q 生成一份上下文文档 d,其中 Q 是训练分裂中的问题集。或者,我们可以使用无监督检索器(例如 BM25)从维基百科获得一份文档。现在我们有一个问题-文档对集 ,其中 。
步骤 2:对每个文档进行编码,并进行 K-Means 聚类。然后,我们使用大型语言模型(即 GPT-3)对每个问题-文档对进行编码,即,,从而每个文档得到 12,288 维向量。然后,我们使用 K-means 将所有嵌入向量 聚类到 K 个集合中,因此每个问题-文档对分配了唯一的聚类 ID 。
步骤 3:抽样并生成 K 个文档。最后,我们从每个聚类 c 中抽样 n 个问题-文档对,表示为 ,其中 n 是超参数 2。然后,同一聚类中的 n 个抽样问题-文档对作为大型语言模型生成上下文文档的上下文演示。例如,大型语言模型的输入可以是“{ placeholder} { placeholder} ... { placeholder} { placeholder} {input question placeholder}”。
通过枚举这 K 个聚类中的抽样文档,我们最终可以得到 K 个生成的文档。通过对不同聚类收集的不同抽样上下文演示进行调整,大型语言模型已经偏向了不同的观点。尽管这些不同的观点以潜在的方式存在,但我们通过与抽样方法、不同的人类提示和从整个数据集随机抽样 n 对进行比较,经验证明它在实践中表现良好。
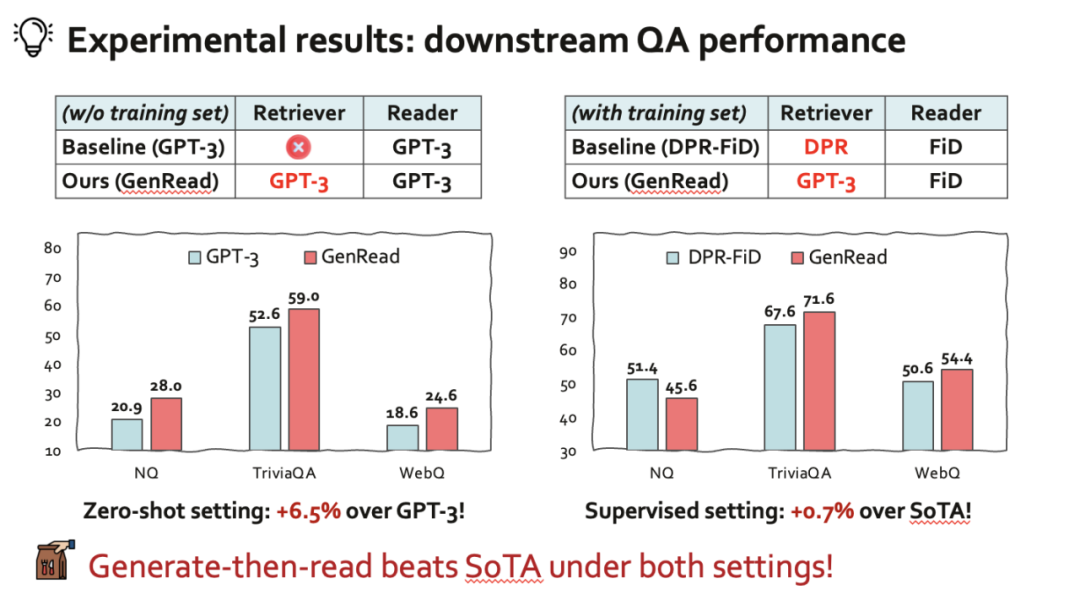
我们提出的 GenRead 与 InstructGPT 阅读器可以显著优于原始的 InstructGPT,在不使用任何外部文档的情况下,在三个开放领域 QA 基准上实现了新的最新性能。我们的 GenRead 可以实现与零点检索再阅读模型相当或更好的性能,这些模型使用检索器或搜索引擎首先获取上下文文档。
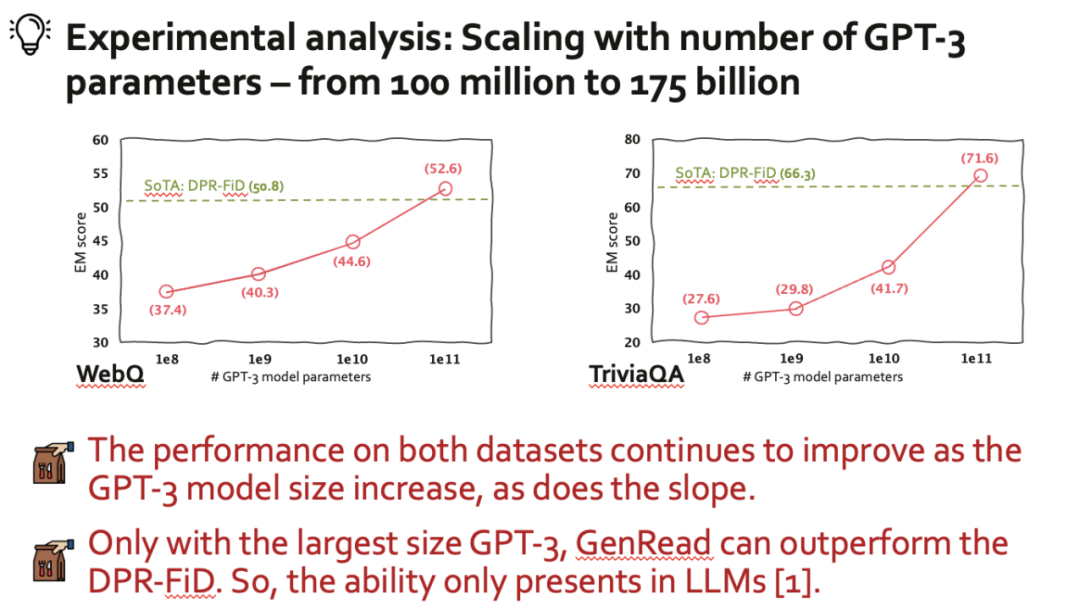
为了确保可重复性,我们在解码中使用贪心搜索。在监督 (supervised learning) 的设置下,相比于基于检索的 SoTA 方法 (DPR-FiD)。仅使用 InstructGPT 生成的文档,我们的 GenRead 可以在 TriviaQA 和 WebQ 上获得比 SoTA 方法更好的性能。
参考文献
[1] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktaschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems (Neurips) 2020.
[2] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems (Neurips) 2020.
[3] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. Advances in neural information processing systems (Neurips) 2022
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢