
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
H Hu, Y Luan, Y Chen, U Khandelwal, M Joshi, K Lee, K Toutanova, M Chang
[Google Research]
开放域视觉实体识别:数百万维基百科实体识别研究
要点:
-
大规模预训练模型在开放域视觉识别任务中表现良好; -
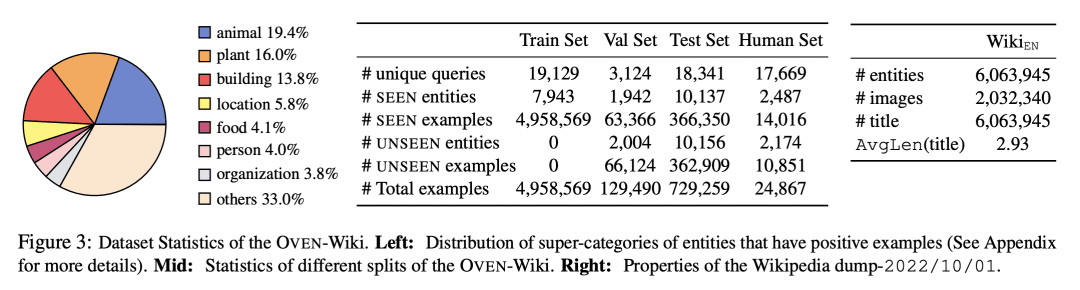
OVEN-Wiki 数据集挑战模型在 600 万个可能的维基百科实体中进行识别,使其成为一个通用的视觉识别基准; -
基于 PaLI 的自回归视觉识别模型表现出奇的好,甚至在微调期间从未见过的维基百科实体上; -
基于 CLIP 的模型在识别长尾实体方面更出色,而基于 PaLI 的模型获得了更高的整体性能。
一句话总结:
大规模预训练模型可以在识别开放域视觉概念上表现良好,正如 OVEN-Wiki 数据集所显示的,其挑战模型在600万个可能的维基百科实体中进行识别。
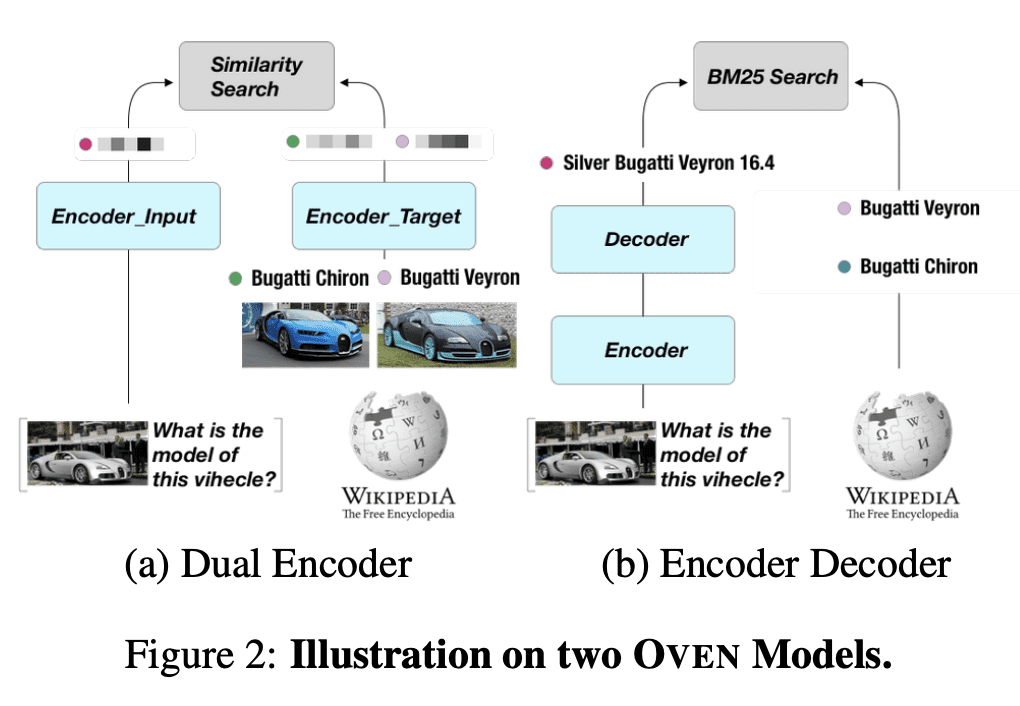
Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
论文链接:https://arxiv.org/abs/2302.11154

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢