
Modular Deep Learning
J Pfeiffer, S Ruder, I Vulić, E M Ponti
[Google Research & University of Cambridge]
模块化深度学习
要点:
-
模块化深度学习通过将计算与路由分离,并在本地更新模块来实现正向迁移和系统性泛化; -
该框架由自主参数高效模块组成,信息有条件地被路由到模块的子集,随后被聚合; -
模块化还有其他用途,包括扩展语言模型、因果推理、程序归纳和强化学习中的规划; -
模块化深度学习已经成功地部署在具体的应用中,如跨语言和跨模态的知识转移。
一句话总结:
模块化深度学习提供了一种很有前途的解决方案,可以开发出专门针对多个任务而没有负面干扰的模型,并且可以系统性泛化到非相同分布的任务。
Transfer learning has recently become the dominant paradigm of machine learning. Pre-trained models fine-tuned for downstream tasks achieve better performance with fewer labelled examples. Nonetheless, it remains unclear how to develop models that specialise towards multiple tasks without incurring negative interference and that generalise systematically to non-identically distributed tasks. Modular deep learning has emerged as a promising solution to these challenges. In this framework, units of computation are often implemented as autonomous parameter-efficient modules. Information is conditionally routed to a subset of modules and subsequently aggregated. These properties enable positive transfer and systematic generalisation by separating computation from routing and updating modules locally. We offer a survey of modular architectures, providing a unified view over several threads of research that evolved independently in the scientific literature. Moreover, we explore various additional purposes of modularity, including scaling language models, causal inference, programme induction, and planning in reinforcement learning. Finally, we report various concrete applications where modularity has been successfully deployed such as cross-lingual and cross-modal knowledge transfer. Related talks and projects to this survey, are available at this https URL.
论文链接:https://arxiv.org/abs/2302.11529
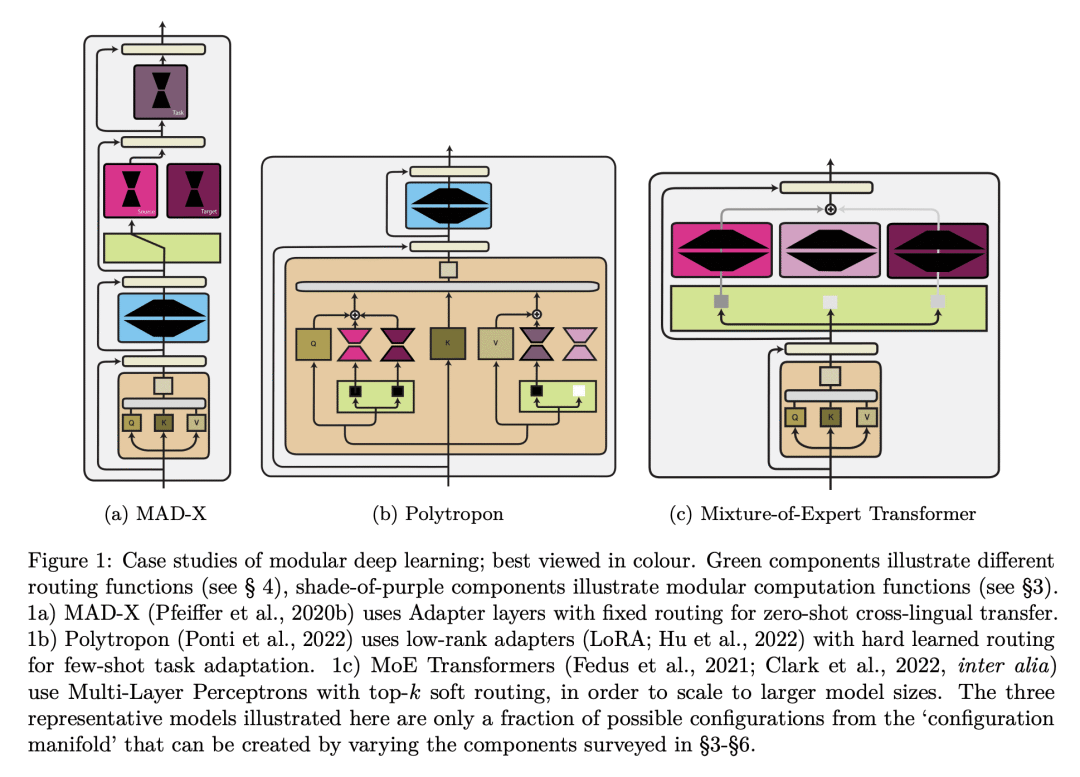
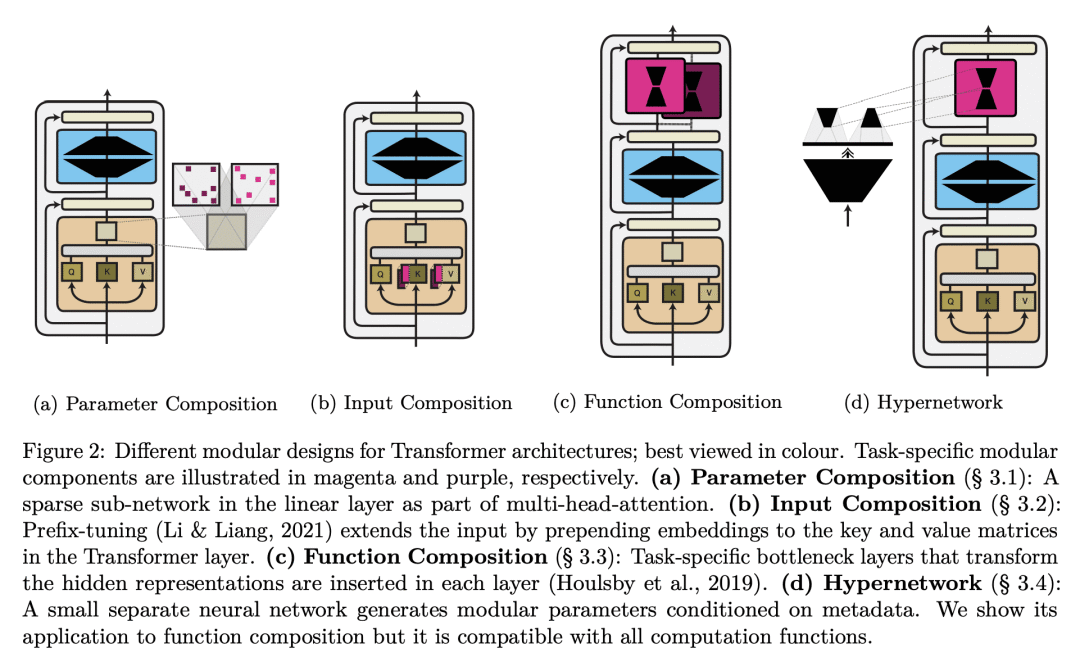
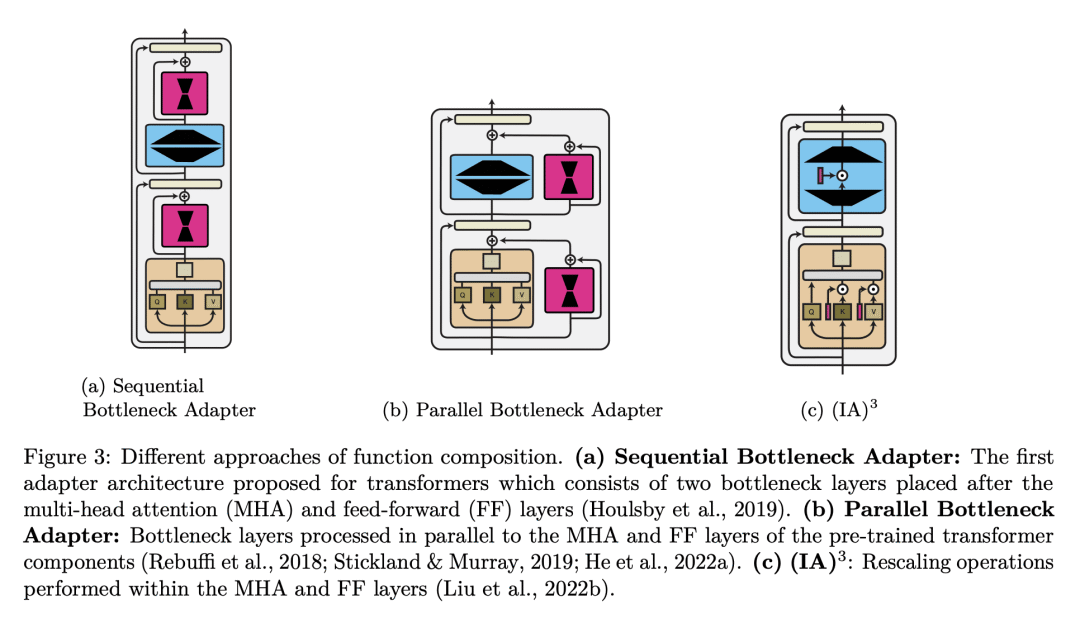
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢