
Aligning Text-to-Image Models using Human Feedback
K Lee, H Liu, M Ryu, O Watkins, Y Du, C Boutilier, P Abbeel, M Ghavamzadeh, S S Gu
[Google Research & UC Berkeley]
用人工反馈对齐文本-图像模型
要点:
-
提出一种简单有效的方法,通过人工反馈来微调文本到图像模型; -
有人工反馈的微调明显改善了图像-文本的对齐,改善幅度高达47%,但代价是图像保真度的轻微下降; -
学到的奖励函数比 CLIP 分数更准确地预测了人工的质量评估; -
对设计选择的仔细调查对于平衡对齐-保真度的权衡是很重要的。
一句话总结:
用人工反馈微调文本到图像模型,有助于提高图像-文本的一致性。
https://arxiv.org/abs/2302.12192
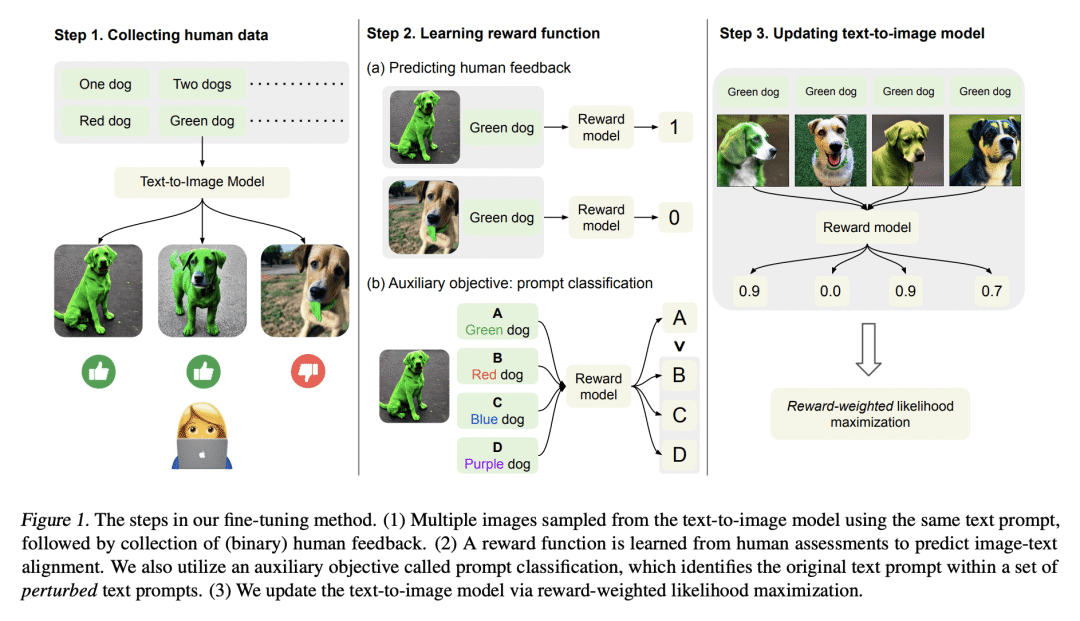
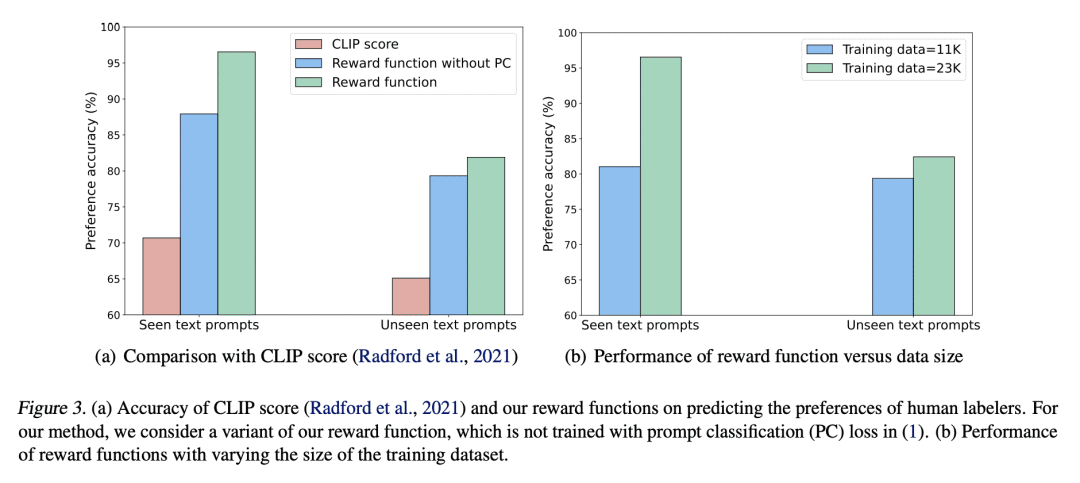
Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢