
Designing an Encoder for Fast Personalization of Text-to-Image Models
R Gal, M Arar, Y Atzmon, A H. Bermano, G Chechik, D Cohen-Or
[Tel Aviv University & NVIDIA]
面向快速个性化文本到图像模型的编码器设计
要点:
-
目前的文本到图像模型的个性化方法在冗长的训练时间、高存储要求或身份的损失方面存在缺陷; -
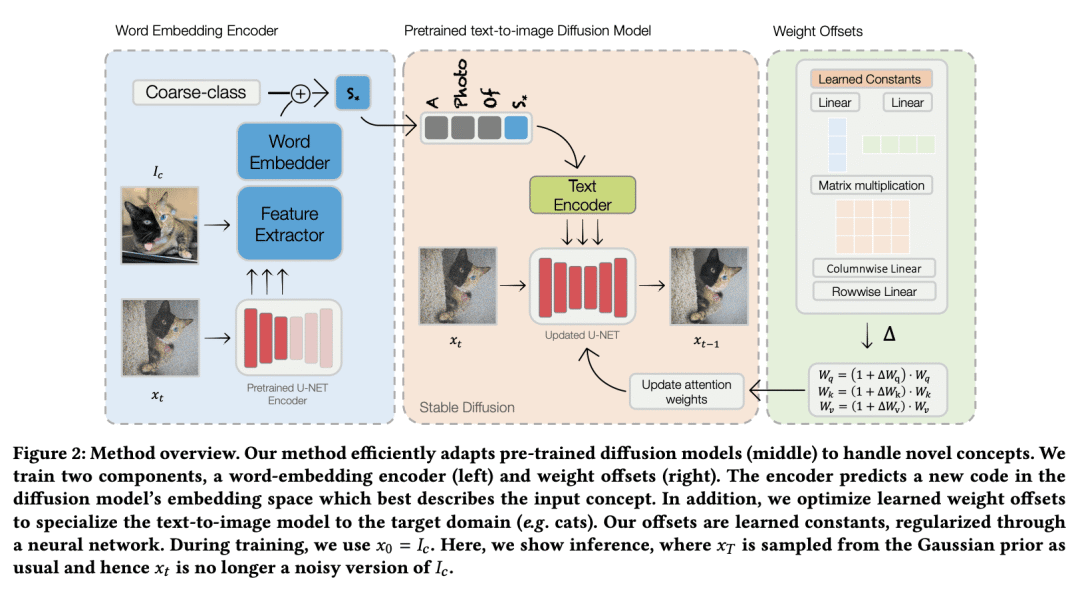
所提出的基于编码器的域微调方法,用一个编码器将目标概念的单幅图像从给定域映射到词嵌入,并为文本到图像模型提供一组正则化权重偏移,以学习如何有效地摄取更多的概念; -
该方法利用大型的、特定域的数据集为未来的优化找到一个好的起点,使网络能更好地自适应来自相同域的新样本; -
该方法在保持最先进的质量的同时实现了显著的加速。
一句话总结:
基于编码器的域微调方法可用于个性化文本到图像模型,只需使用一张图像和至少5个训练步,在保持质量的同时将个性化从数十分钟加速到数秒。
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
论文链接:https://arxiv.org/abs/2302.12228


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢