
Video Probabilistic Diffusion Models in Projected Latent Space
S Yu, K Sohn, S Kim, J Shin
[KAIST & Google Research]
投射潜空间视频概率扩散模型
要点:
-
PVDM 是一种视频生成模型,使用低维潜空间来对高分辨率视频进行高效训练; -
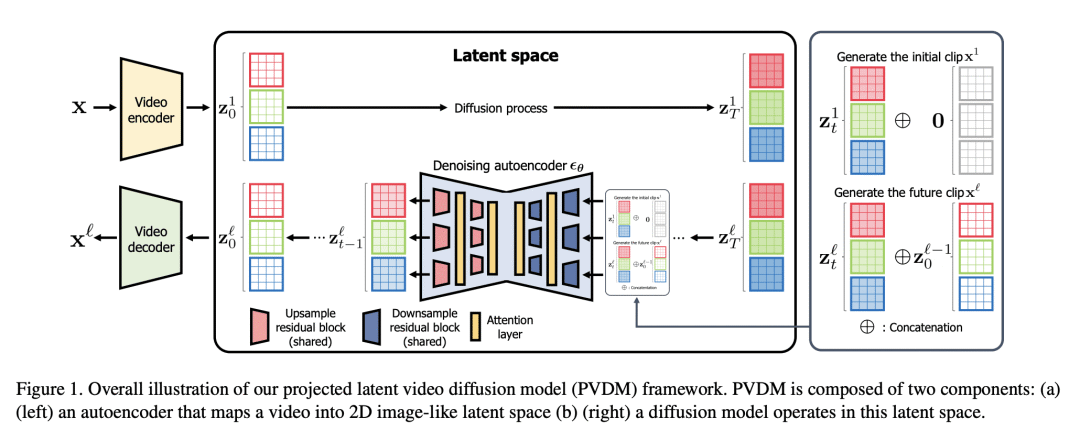
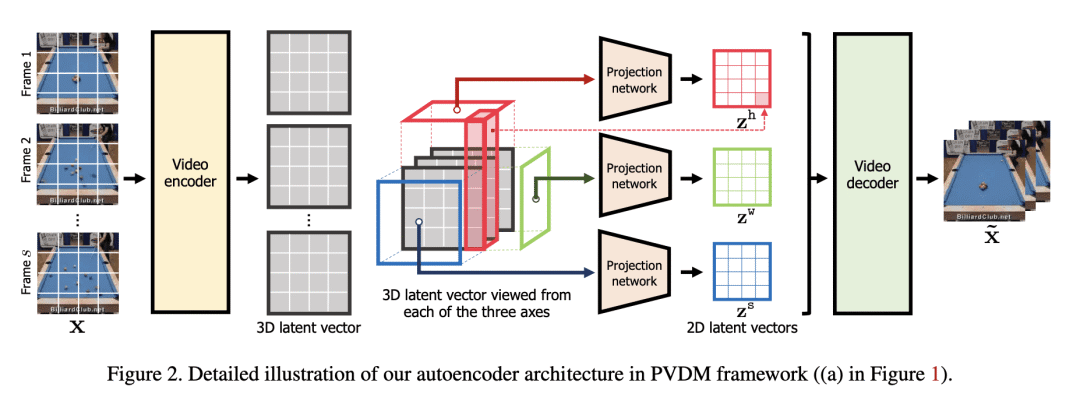
PVDM 由一个自编码器和一个用于视频生成的扩散模型结构组成,自编码器将视频投射为 2D 潜向量; -
PVDM 在流行视频生成数据集上的 FVD 得分方面优于之前的视频合成方法; -
PVDM避免了计算量大的 3D 卷积神经网络架构,并为无条件和有条件帧生成建模提供了联合训练。
一句话总结:
PVDM 是一种新的视频生成模型,使用概率扩散模型在低维潜空间高效地学习视频分布。
Despite the remarkable progress in deep generative models, synthesizing high-resolution and temporally coherent videos still remains a challenge due to their high-dimensionality and complex temporal dynamics along with large spatial variations. Recent works on diffusion models have shown their potential to solve this challenge, yet they suffer from severe computation- and memory-inefficiency that limit the scalability. To handle this issue, we propose a novel generative model for videos, coined projected latent video diffusion models (PVDM), a probabilistic diffusion model which learns a video distribution in a low-dimensional latent space and thus can be efficiently trained with high-resolution videos under limited resources. Specifically, PVDM is composed of two components: (a) an autoencoder that projects a given video as 2D-shaped latent vectors that factorize the complex cubic structure of video pixels and (b) a diffusion model architecture specialized for our new factorized latent space and the training/sampling procedure to synthesize videos of arbitrary length with a single model. Experiments on popular video generation datasets demonstrate the superiority of PVDM compared with previous video synthesis methods; e.g., PVDM obtains the FVD score of 639.7 on the UCF-101 long video (128 frames) generation benchmark, which improves 1773.4 of the prior state-of-the-art.
https://arxiv.org/abs/2302.07685


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢