
LLaMA: Open and Efficient Foundation Language Models
H Touvron, T Lavril, G Izacard…
[Meta AI]
LLaMA: 开源高效的基础语言模型
要点:
-
LLaMA 是一个开源的基础语言模型集合,参数范围从7B到65B,完全使用公开的数据集在数万亿 Token 上训练; -
LLaMA-13B 在大多数基准上都优于 GPT-3(175B),而体积却小了 10 倍以上,LLaMA-65B 与最好的模型 Chinchilla70B 和 PaLM-540B 相比有竞争力; -
该研究表明,通过完全在公开可用的数据上进行训练,有可能达到最先进的性能,而不需要求助于专有的数据集,这可能有助于努力提高鲁棒性和减轻已知的问题,如毒性和偏见; -
向研究界发布LLaMA模型,可能会加速大型语言模型的开放,并促进对指令微调的进一步研究,未来的工作将包括发布在更大的预训练语料库上训练的更大的模型。
一句话总结:
LLaMA 是开放高效的基础语言模型集合,仅在公开可用的数据集上进行训练,在大多数基准测试中表现优于GPT-3。
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. We release all our models to the research community.
论文链接:
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
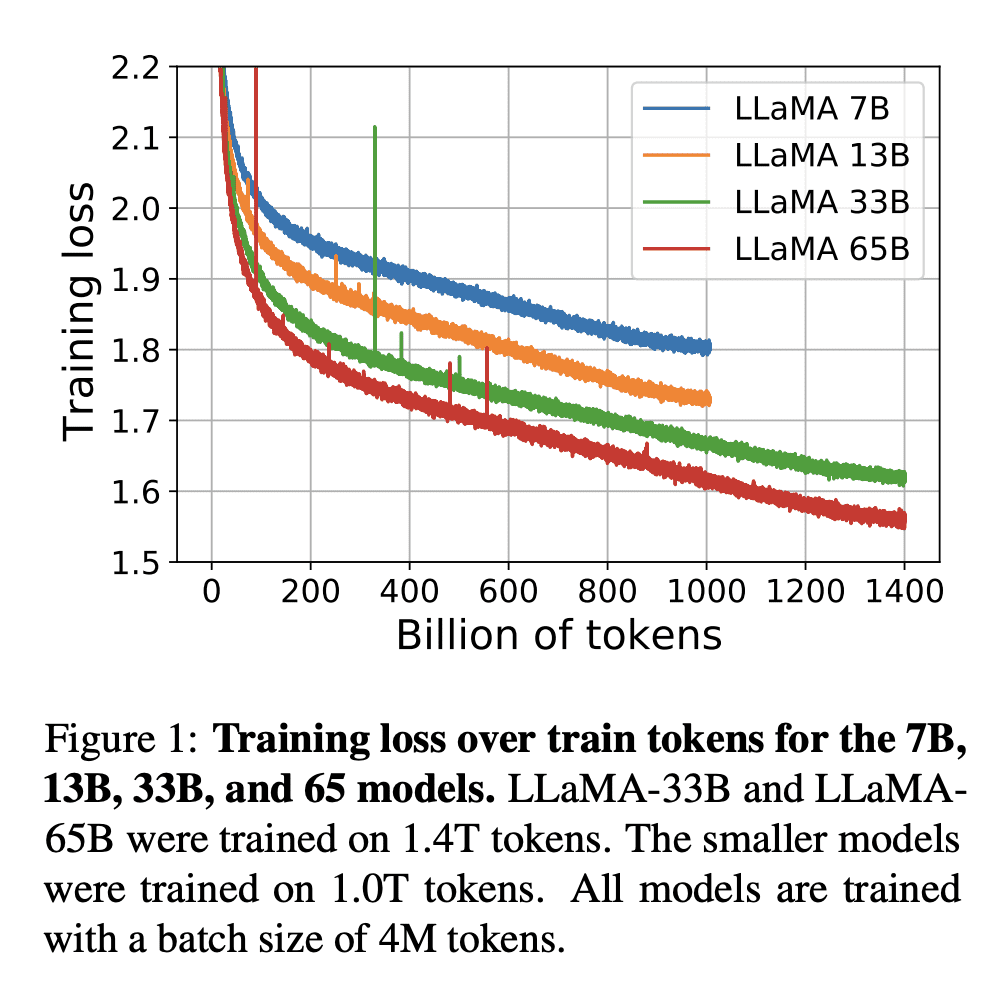
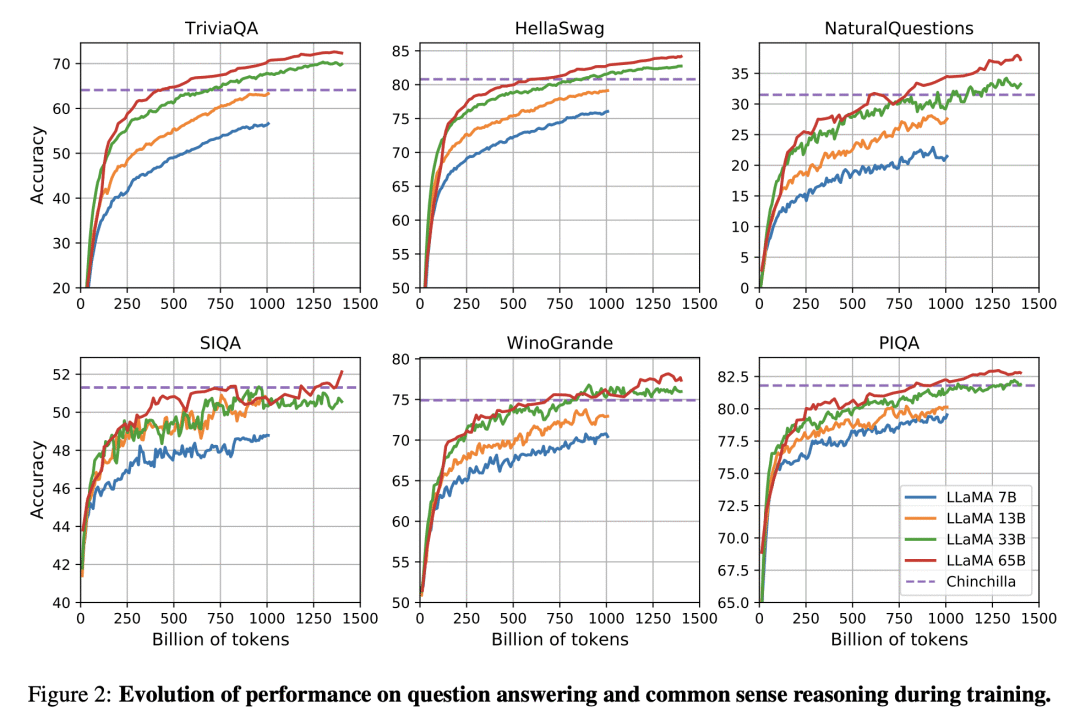
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢